Performance and scale testing
With every JIRA release, we’re publishing a performance and scaling report that compares performance of the current JIRA version with the previous one. The report also contains results of how various data dimensions (number of custom fields, issues, projects, and so on) affect JIRA, so you can check which of these data dimensions should be limited to have best results when scaling JIRA.
This report is for
JIRA 7.3
. If you’re looking for other reports, select your version at the top-right.Introduction
When some JIRA administrators think about how to scale JIRA, they often focus on the number of issues a single JIRA instance can hold. However, the number of issues is not the only factor that determines the scale of a JIRA instance. To understand how a large instance may perform, you need to consider multiple factors.
This page explains how JIRA performs across different versions and configurations. So whether you are a new JIRA evaluator that wants to understand how JIRA can scale to your growing needs or you're a seasoned JIRA administrator that is interested in taking JIRA to the next level, this page is here to help.
There are two main approaches, which can be used in combination to scale JIRA across your entire organization:
- Scale a single JIRA instance.
- Use JIRA Data Center which provides JIRA clustering.
Here we'll explore techniques to get the most out of JIRA that are common to both approaches. For additional information on JIRA Data Center and how it can improve performance under concurrent load, please refer to our JIRA Data Center page.
Determining the scale of a single JIRA instance
There are multiple factors that may affect JIRA's performance in your organization. These factors fall into the following categories (in no particular order):
- Data size
- The number of issues, comments and attachments.
- The number of projects.
- The number of JIRA project attributes, such as custom fields, issue types, and schemes.
- The number of users registered in JIRA and groups.
- The number of boards, and number of issues on the board (when you're using JIRA Software).
- Usage patterns
- The number of users concurrently using JIRA.
- The number of concurrent operations.
- The volume of email notifications.
- Configuration
- The number of plugins (some of which may have their own memory requirements).
- The number of workflow step executions (such as Transitions and Post Functions).
- The number of jobs and scheduled services.
- Deployment environment
- JIRA version used.
- The server JIRA runs on.
- The database used and connectivity to the database.
- The operating system, including local file storage, memory allocation, and garbage collection.
This page will show how the speed of JIRA can be influenced by the size and characteristics of data stored in the database.
JIRA 7.3 performance
JIRA 7.3 was not focused solely on performance, however we do aim to provide the same, if not better, performance with each release. In this section, we'll compare JIRA 7.3.0 to JIRA 7.2.5. Specifically, we ran the same extensive test scenario for both JIRA versions. The only difference between the scenarios was the JIRA version.
The following chart presents 1%-trimmed mean response times of individual actions performed during the tests.
Response times for JIRA actions
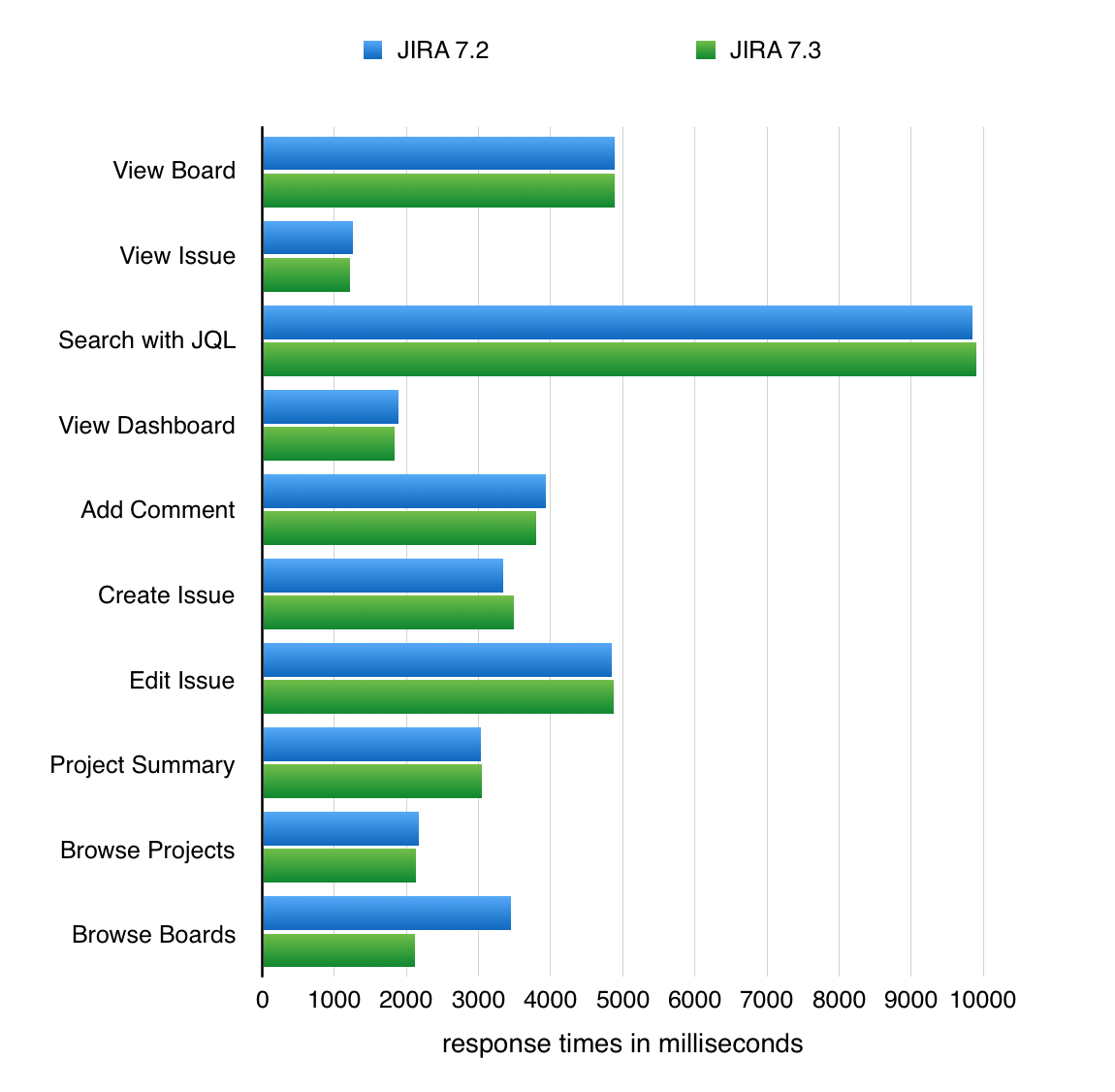
Performance Testing Conclusions:
- On average, JIRA 7.3.0 performs actions 4% faster than JIRA 7.2.5. This is based on the average time to complete an action, obtained from our tests described below.
- Most of the individual actions have very similar performance.
- Browsing agile boards is noticeably faster.
JIRA performance testing methodology
The following sections detail the testing environment, including hardware specification, and methodology we used in our performance tests.
How we tested
Before we started the test, we needed to determine what size and shape of dataset represents a typical large JIRA instance.
In order to achieve that, we used our Analytics data to form a picture of our customers' environments and what difficulties they face when scaling JIRA in a large organization.
The following table presents rounded values of the 999th permille of each data dimension. We used these values to generate a sample dataset with random test data in JIRA Data Generator.
Baseline test JIRA data set
| JIRA Data Dimension | Value |
|---|---|
| Issues | 1,000,000 |
| Projects | 1500 |
| Custom Fields | 1400 |
| Workflows | 450 |
| Attachments | 660,000 |
| Comments | 2,900,000 |
| Agile Boards | 1,450 |
| Users | 100,000 |
| Groups | 22,500 |
| Security Levels | 170 |
| Permissions | 200 |
Next we chose a mix of actions that would represent a sample of the most common user actions. An "action" in this context is a complete user operation like opening of an Issue in the browser window. The following table details the actions that we included in the script for our testing persona, indicating how many times each action is repeated during a single test run.
Action name | Description | Number of times action is performed during a single test run |
|---|---|---|
| View Dashboard | Opening the Dashboard page. | 10 |
| Create Issue | Submitting a Create Issue dialog. | 5 |
| View Issue | Opening an individual issue in a separate browser window. | 55 |
| Edit Issue | Editing the Summary, Description and other fields of an existing Issue. | 5 |
| Add Comment | Adding a Comment to an Issue. | 2 |
| Search with JQL | Performing a search query using JQL in the Issue Navigator interface.
| 10 |
| View Board | Opening of Agile Board | 10 |
| Browse Projects | Opening of the list of Projects (available under Projects > View All Projects menu) | 5 |
| Browse Boards | Opening of the list of Agile Boards (available under Agile > Manage Boards menu) | 2 |
Test environment
Our performance tests were all run on the same controlled isolated lab at Atlassian. For each test, the entire environment was reset and rebuilt, and then each test started with some idle cycles to warm up instance caches. To run the tests, we used 10 scripted browsers and measured the time taken to perform the actions. Each browser was scripted to perform a random action from predefined list of actions and immediately move on to the next action (i.e. zero think time). Please note that it resulted in each browser performing substantially more tasks than would be possible by a real user and you should not equate the number of browsers to represent the number of real world concurrent users. Each test was run for 45 minutes, after which statistics were collected.
JIRA 7.3 scalability
JIRA's flexibility causes tremendous diversity in our customer's configurations. Analytics data shows that nearly every customer dataset displays a unique characteristic. Different JIRA instances grow in different proportions of each data dimension. Frequently, a few dimensions become significantly bigger than the others. In one case, the issue count may grow rapidly, while the project count remains constant. In another case, the custom field count may be huge, while the issue count is small.
Many organizations have their own unique processes and needs. JIRA's ability to support these various use cases explains the dataset diversity. However, each data dimension can influence JIRA's speed. This influence is often not constant nor linear.
In order to provide individual JIRA instance users with an optimum experience and avoid performance degradation, it is important to understand how specific JIRA data dimensions influence the speed of the application. In this section we will present the results of the JIRA 7.3 scalability tests that investigated the relative impact of various configuration values.
How we tested
As a reference for the test we used a JIRA 7.3 instance with the baseline test data set specified above and ran the full performance test cycle on it. Next, in the baseline data set we doubled each attribute and ran independent performance tests for each doubled value (i.e. we ran the test with a doubled number of issues, or doubled number of custom fields) while leaving all the other attributes in the baseline data set unchanged. Then, we compared the response times from the doubled data set test cycles with the reference results. With this approach we could isolate and observe how the growing size of individual JIRA configuration items affects the speed of an (already large) JIRA instance.
In the charts below we present how the response times of JIRA actions change for growing size of individual data attributes.
In order to provide a clearer view, each graph shows only the actions for which the difference of response time was greater than the variance of natural noise caused by the randomness of the tests procedure.




Issues
There is a common belief among seasoned JIRA admins in large organizations that the number of issues is the most important factor affecting JIRA performance; in other words, when an individual JIRA instance reaches a couple of hundred thousand issues it will start becoming unresponsive. While this was generally true in older JIRA versions, since JIRA 5.1 the number of issues has become less and less important for the overall JIRA responsiveness. That number still affects the speed of actions that require indexing of issues, but the degradation is not as severe and JIRA 7.3 can handle more than a million Issues.
The following chart presents response times of JIRA actions in JIRA 7.3 instances with 1,000,000 and 2,000,000 issues.

Conclusion
The number of issues has the highest impact on searching via JQL and viewing boards - actions reading from the issue index.
Custom Fields
Custom fields can be configured in a variety of ways including setting the applicable context, field configurations and screen schemes, and including the three of them in various combinations. In this test we had all the custom fields set to global in order to see how much of an impact the raw number of custom fields has on performance.
The following chart presents response times of JIRA actions in JIRA 7.3 instances with 1,400 and 2,800 custom fields.

Conclusion
- The number of custom fields has high impact on actions that request or process custom issue details – viewing, searching, creating and editing issues, and adding comments.
- It has less, but still slightly noticeable impact on viewing dashboards and browsing projects.
Projects
The following chart presents response times of JIRA actions in JIRA 7.3 instances with 1,500 and 3,000 projects.
Conclusion
- The number of projects has visible impact on many aspects of JIRA performance, most importantly on adding comments and browsing projects.
- Less impact has been observed on viewing, creating and editing issues.
Users and Groups
The number of users, next to the number of issues, is one of the most commonly customer quoted examples of JIRA instance size. When evaluating the influence of the number of users on JIRA's performance, it is important to separate the number of user accounts registered in JIRA from the number of users actively using JIRA at the same time, known as concurrent users. In this test we wanted to determine the influence of the absolute number of users and groups registered in JIRA, without increasing the number of concurrent users. For a large number of concurrent JIRA users we suggest considering the JIRA Data Center solution, which allows the JIRA application to be clustered in a multi-node cluster with a load balancer to distribute the load across the cluster.
The following chart presents response times of the create issue action in a JIRA 7.3 instance with 100,000 users and 22,500 groups compared to 200,000 users and 45,000 groups.

Conclusion
The number of users and groups negatively impacts the performance of adding comments and creating/editing issues - actions using user pickers or comment visibility.
Workflows
The following chart presents the response time of JIRA actions in JIRA 7.3 instances with 450 and 900 workflows.

Conclusion
The number of workflows has a noticeable impact on adding comments, with smaller effects on creating and viewing issues.
Permissions and Security Levels
The following chart presents response times of JIRA actions in JIRA 7.3 instances with 170 security levels and 200 permissions compared to 340 security levels and 400 permissions.

Conclusion
- The number of permissions has noticeable impact on the time needed to view a single board.
- No other significant changes to JIRA performance have been observed.
Key takeaways
- JIRA 7.3.0 was not a release solely focused on performance. We observed only slight performance improvements. We've expanded our performance testing pipeline to prevent any future regressions through closer monitoring of the results.
- Custom fields is the most impactful data dimension. It means it is still a good practice to keep your JIRA configuration lean. Limiting the number of custom fields and workflows, as well as reusing schemes where possible, not only helps your JIRA instance keep satisfactory performance levels, but also makes administration less complicated.
- The number of comments, agile boards and attachments did not have a significant impact on JIRA performance in our tests, and is not covered in detail here.
Further resources
Archiving Issues
Although we discovered that the number of issues is not significantly affecting JIRA's performance, by far it will be the dimension with the highest value. You may come to conclusion that the massive number of issues clutters the view in JIRA, and therefore you still may wish to archive the outdated issues from your instance.
JIRA Data Center
JIRA Data Center is the ideal solution to use when you have a high number of concurrent users. JIRA Data Center allows the JIRA application to be clustered in a multi-node cluster where all nodes are active. This means that with a load balancer in front you can distribute the load across multiple nodes thereby increasing throughput when compared to a single server handling the same load. JIRA Data Center 7.3 also provides High Availability, and is the only fully Atlassian supported option for JIRA Disaster Recovery.
Please refer to our main page for more information on JIRA Data Center.
User Management
As your JIRA user base grows you may want to take a look at the following:
- Connecting JIRA to your LDAP Directory for authentication, user and group management.
- Connecting to Crowd or Another JIRA Server for User Management.
- Allowing Other Applications to Connect to JIRA for User Management.
JIRA Knowledge Base
For detailed guidelines on specific performance-related topics refer to the Troubleshoot performance issues in Jira server article in the JIRA Knowledge Base.
JIRA Enterprise Services
For help with scaling JIRA in your organization directly from experienced Atlassians, reach out to our Premier Support and Technical Account Management services.
Atlassian Experts
The Atlassian Experts in your local area can also help you scale JIRA in your own environment.