Sprint Report shows a spike at the beginning of the Sprint in Jira
Platform notice: Server and Data Center only. This article only applies to Atlassian products on the Server and Data Center platforms.
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
Sprint Report shows an increase in workload at the beginning of the Sprint as if stories were added after the Sprint has started.
Example report:
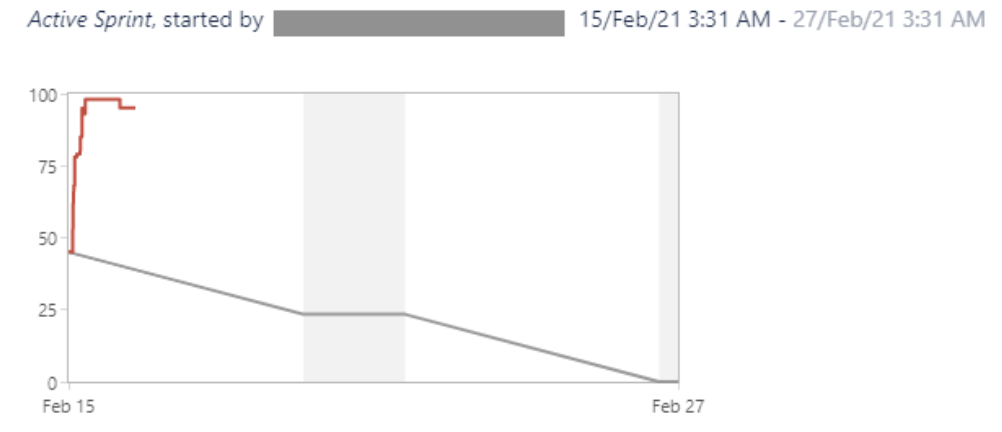
Environment
All versions of Jira Software 7.x and 8.x.
Diagnosis
Check the Sprint Report for issues that have an asterisk. They're been added after the Sprint Start Date.
The query below will show (in epoch time) when the Sprint "OPEN" operation was performed and which dates were entered as Sprint Start and Sprint End dates:
select s."ID", s."NAME", s."RAPID_VIEW_ID", ae."DATA", ae."TIME", s."START_DATE", s."END_DATE"
from "AO_60DB71_SPRINT" s
join "AO_60DB71_AUDITENTRY" ae on ae."ENTITY_ID" = s."ID"
where s."NAME" = '<SPRINT NAME>';The query below will show which stories were once included in the Sprint and when (created column):
select p.pkey, i.issuenum, i.id, au.lower_user_name, cg.created, ci.field, ci.oldvalue, ci.newvalue, ci.oldstring, ci.newstring
from changeitem ci
join changegroup cg on cg.id = ci.groupid
join jiraissue i on i.id = cg.issueid
join project p on p.id = i.project
join app_user au on au.user_key = cg.author
where ci.field in ('Story Points', 'Sprint')
and i.id in (select issueid from changeitem, changegroup where newstring = '<SPRINT NAME>' and changeitem.groupid = changegroup.id)
order by created, id;Replace SPRINT NAME on the commands above with the corresponding Sprint name.
The queries above are examples and built for Postgres and may need to be adjusted to your database type.
Cause
The Sprint report spikes for every Story added after the Sprint Start Date — not the Sprint start operation date (when the start button was pressed).
For the query #1 above, all stories added to the sprint after the "START_DATE" will count as a Story added after the Sprint was started — even if the start button was pressed after all stories have been added to the Sprint.
Solution
The most appropriate approach is to edit (may have to reopen) the Sprint and adjust the Start Date to some time after all stories were added to the Sprint (query #2 on the Diagnosis section above). Luckily, this would mean postponing the Sprint Start Date only a few hours instead of days.