Configuring S3 object storage
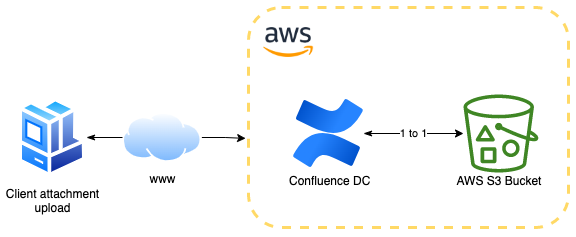
Diagram of how object storage works. Attachments uploaded to Confluence are stored in and retrieved from an Amazon S3 bucket.
Check if object storage is right for you
We're continuing to build improvements to our object storage solution and we recommend you take some time to read through the requirements and limitations of this version to make sure it's suitable for you.
Requirements
To use Amazon S3 object storage:
You must be using a Data Center license.
You should plan to provision Confluence to AWS, or already run Confluence in AWS. This feature isn't supported for on-premise deployments or for any customers not running Confluence in AWS.
- You'll need a dedicated Amazon S3 bucket to hold Confluence attachment data. Learn more about how to create, configure and connect an S3 bucket to Confluence on this page.
For existing customers: You should migrate attachment data to Amazon S3, see Attachment Storage Configuration for instructions on how to do this.
Limitations
- Amazon S3 is currently the only Confluence-supported object storage solution.
S3 object storage is for attachment data only. You'll still need to use file system storage for other data, for example configuration data.
There is currently no Atlassian-supported way to migrate attachment data from your file system to Amazon S3, nor from Amazon S3 back to your file system or another storage medium. In general, we'd recommend Amazon DataSync for all migration work.
- Using temporary credentials to authenticate to AWS will require a Confluence restart every time they change. Track this issue at CONFSERVER-81610 - Getting issue details... STATUS
- There is a known issue when Amazon S3 object storage is configured where performing attachment-related tasks involving more than 50 attachments causes your instance to become temporarily unresponsive or slow. We are actively investigating this bug, and you can track the issue at CONFSERVER-82499 - Getting issue details... STATUS
Step 1. Create a bucket
Before you can start using Amazon S3 to store your attachments, you'll need an Amazon S3 bucket. Amazon has official guides for how to do this:
Reminder to secure your S3 bucket
Make sure your bucket is correctly secured, and not publicly exposed. You're responsible for your Amazon S3 bucket configuration and security, and Atlassian is unable to provide direct support for issues related to your S3 setup.
Bucket permissions
Make sure you grant Confluence read and write permissions to:
s3:ListBuckets3:PutObjects3:GetObjects3:DeleteObject
Depending on how you authenticate your bucket (see step 2), these permissions can be applied at the bucket level using bucket policies and also via IAM roles for EC2.
Here is an example Identity and Access Management (IAM) policy providing appropriate permissions (based on a least privilege model):
{
"Version": "2012-10-17",
"Id": "PolicyForS3Access",
"Statement": [
{
"Sid": "StatementForS3Access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/ConfluenceS3"
},
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::confluence-attachment-data/*",
"arn:aws:s3:::confluence-attachment-data"
]
}
]
}Supported bucket configurations
Confluence supports these S3 bucket properties and features being enabled via the AWS console or CLI.
Configuring any property not listed below may result in Confluence not working correctly with your bucket.
Property | Description |
|---|---|
Bucket versioning | Keep multiple versions of an object in one bucket by enabling versioning. By default, versioning is disabled for a new S3 bucket. Amazon S3's bucket versioning should be considered complementary to Confluence's way of managing attachment versions. The two approaches are mutually exclusive where one does not affect the other. You should use S3 bucket versioning where you need to preserve, retrieve, and restore every version of every object stored in your bucket, even when purged from Confluence.
For information about enabling versioning, see Enabling versioning on buckets. |
Bucket policies | Control access to the objects stored in the bucket, see Policies and Permissions in Amazon S3. |
| S3 Intelligent-Tiering | Only those access tiers marked as "automatic" are supported, see S3 Intelligent-Tiering access tiers. |
Step 2. Authenticate your Amazon S3 bucket
Confluence uses the AWS SDK for Java 2.x to communicate with Amazon S3. The SDK will search for credentials in your Confluence environment in this predefined sequence until it can be authenticated:
Amazon EC2 instance profile credentials is recommended by Amazon. If using this option then it is also advisable to use v2 of the Instance Meta Data Service.
- Environment variables
Java system properties
If using Java system properties, be aware that these values may be logged by the product on startup.
Web identity token from AWS Security Token Service
The shared credentials and
configfiles(~/.aws/credentials)Amazon ECS container credentials
Amazon EC2 instance profile credentials (recommended by Amazon)
For information on setting credentials against your environment, Amazon has developer guides on:
To test your bucket connectivity:
Confirm the authentication mechanism is valid and that the correct permissions are in place using the AWS S3 CLI and the steps below.
Create a test file:
touch /tmp/test.txtConfirm
S3:PutObjectpermissions by writing the file to the target bucket:aws s3api put-object --bucket <bucket_name> --key conn-test/test.txt --body /tmp/test.txtConfirm
S3:ListBucketpermissions:aws s3api list-objects --bucket <bucket_name> --query 'Contents[].{Key: Key, Size: Size}'Confirm
S3:GetObjectpermissions:aws s3api get-object --bucket <bucket_name> --key conn-test/test.txt /tmp/test.txtConfirm
S3: DeleteObjectpermissions:aws s3api delete-object --bucket <bucket_name> --key conn-test/test.txtRemove the original test file:
rm /tmp/test.txt
Step 3. Connect your S3 bucket with Confluence
To connect the Amazon S3 bucket with your Confluence instance:
Configure the bucket name and region system properties:
confluence.filestore.attachments.s3.bucket.nameconfluence.filestore.attachments.s3.bucket.regionTo learn how to do this, see Configuring System Properties.
- Note:
confluence.cfg.xmlin local home or shared home (if clustering is enabled) will be automatically updated with these properties.
Then, start/restart your Confluence instances.
When Confluence starts up, it will check your bucket connectivity, bucket name and region validity, and bucket permissions. If these can’t be validated, the startup process will stop and you’ll receive an error message to tell you why it has failed. See our troubleshooting section below for help with these errors.
To verify that Confluence is using Amazon S3 object storage:
Go to Administration
 > General Configuration > System Information
> General Configuration > System InformationNext to Attachment Storage Type, you'll see S3
Additionally, next to Java Runtime Arguments, both the bucket name and region system properties and their respective values will be visible.
Note: When using Amazon S3 storage, Confluence ignores the attachments.dir property (used for relocating a storage directory). Instead, attachment data is stored in S3 using the root prefix /confluence/attachments/v4. In other words, changing the attachments.dir property will have no impact on where attachments are stored once Confluence is configured to use Amazon S3.
Troubleshooting
On startup, Confluence will perform a series of health checks to identify any problems. These are listed below with the actions you should take to resolve them.
The main issues will be related to improper S3 configuration, permissions, or authentication.
You can also find more details about the problem by reviewing the health check log at atlassian-confluence-health-checks.log. The Working with Confluence Logs page explains how to access this and other logs.
Problem | Solution |
|---|---|
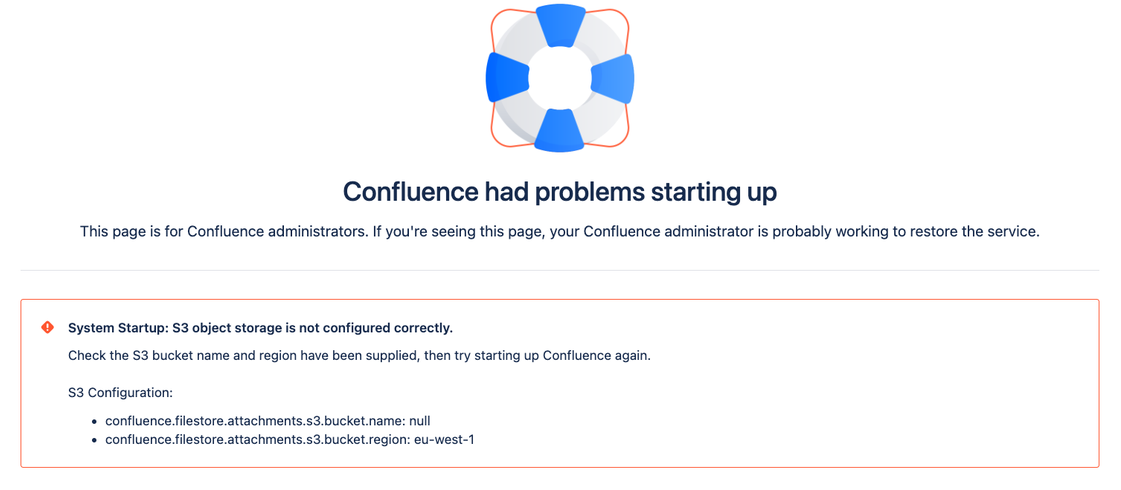
Missing S3 configuration
Example of health check warning
Text version:
Check the S3 bucket name and region have been supplied, they try starting up Confluence again. S3 Configuration:
| In this situation the property You’ll need to provide a valid value for both the bucket name and region for Amazon S3 to work. |
Bucket region isn't valid
Example of health check warning
Text version:
Error performing write operation: Received an UnknownHostException when attempting to interact with a service. See cause for the exact endpoint that is failing to resolve. If this is happening on an endpoint that previously worked, there may be a network connectivity issue or your DNS cache could be storing endpoints for too long. S3 Configuration:
| In this situation the property You'll need to provide a valid value for the bucket region, then restart Confluence. |
Bucket name isn't valid
Example of health check warning
Text version:
Error performing write operation: The specified bucket does not exist (Service: S3, Status Code: 404, Request ID: X, Extended Request ID:X) S3 Configuration:
| In this situation the property You'll need to provide a valid value for the bucket name, then restart Confluence. |
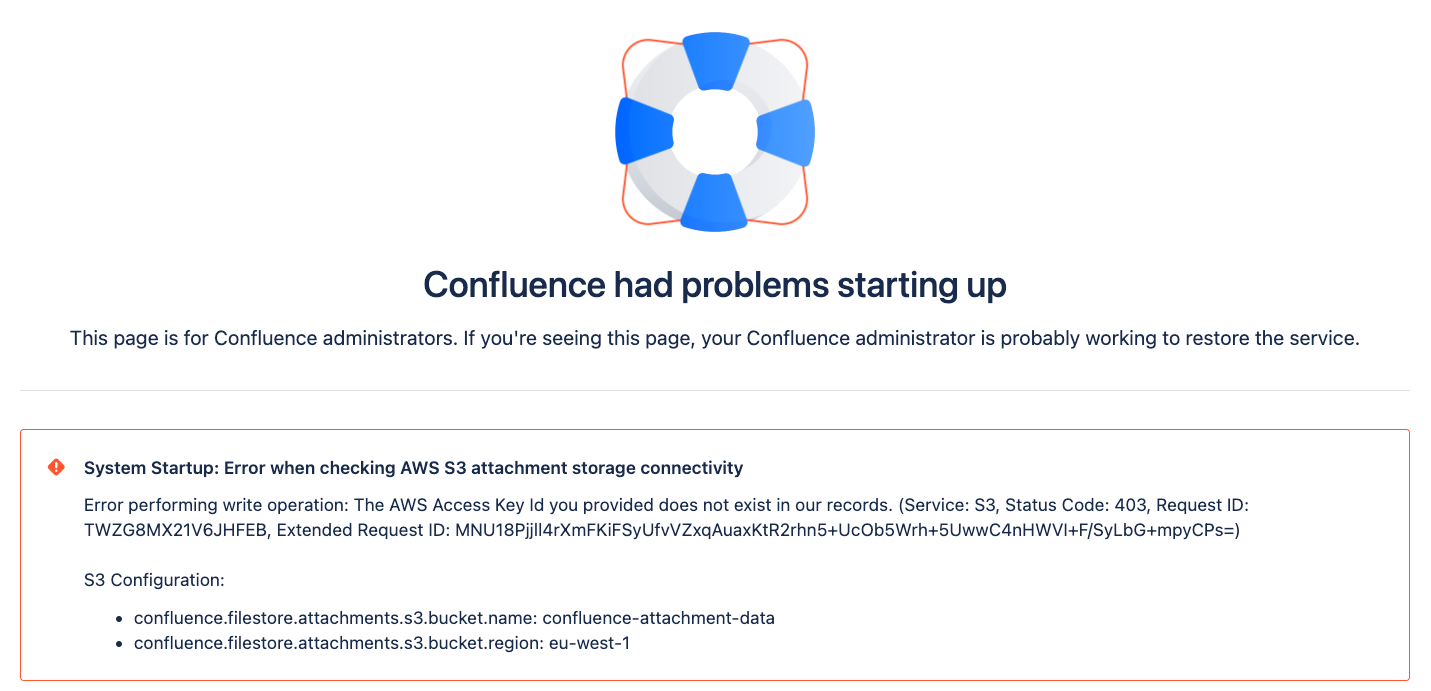
Starting Confluence with bad AWS credentials
Example of health check warning
Text version:
Error performing write operation: The AWS Key Id you provided does not exist in our records. (Service: S3, Status Code: 404, Request ID: X, Extended Request ID:X) S3 Configuration:
| In this situation an invalid AWS access key has been provided as part of the selected authentication mechanism. This has resulted in a failure to authenticate with AWS. You’ll need to provide a valid value for the access key, then restart Confluence. |
Bucket has not been configured read permissions (
Example of health check warning
Text version:
Error performing read operation: Access Denied (Service: S3, Status Code: 403, Request ID: X, Extended Request ID:X) S3 Configuration:
| In this situation the Check that the correct bucket permissions are in place, and apply them as necessary. Then restart Confluence. |
Bucket has not been configured write permissions (
Example of health check warning
Text version:
Error performing write operation: Access Denied (Service: S3, Status Code: 403, Request ID: X, Extended Request ID:X) S3 Configuration:
| In this situation the Check that the correct bucket permissions are in place, and apply them as necessary. Then restart Confluence. |
Bucket has not configured delete permissions (
Example of health check warning
Text version:
Error performing delete operation: Access Denied (Service: S3, Status Code: 403, Request ID: X, Extended Request ID:X) S3 Configuration:
| In this situation the Check that the correct bucket permissions are in place, and apply them as necessary. Then restart Confluence. |
Configuring Confluence with a bucket that has no list permissions (
Example of health check warning
Text version:
Error performing list operation: Access Denied (Service: S3, Status Code: 403, Request ID: X, Extended Request ID:X) S3 Configuration:
| In this situation the Check that the correct bucket permissions are in place and apply them as necessary. Then restart Confluence. |