Configuring global Jira settings
Global Jira settings for Insight include configuration for the Insight app itself, rather than object schemes, object types, or even objects. Here you can configure log settings, date and time, Insight reindexing, and so on. Read on for more details on available settings.
Accessing global Jira settings
To access global Jira settings for Insight:
- Go to Administration > Manage apps.
- Look for pages in the Insight section.
General configuration
To open general configuration, select Insight configuration.
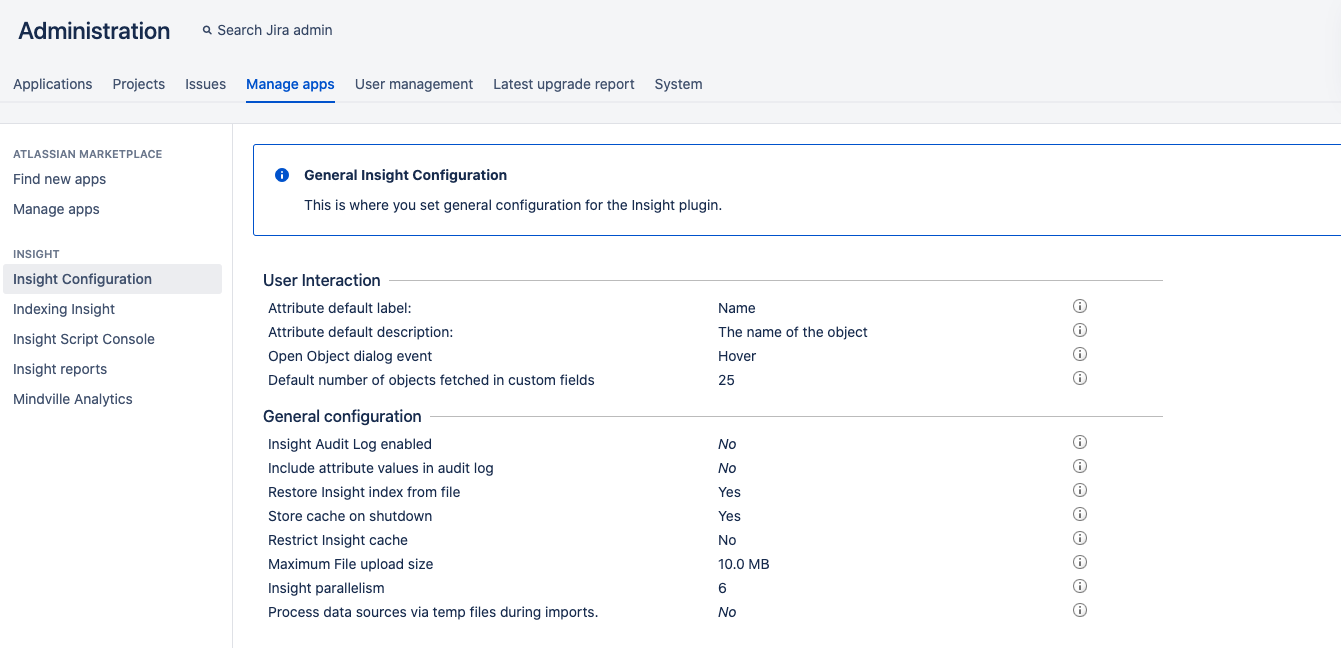
| Setting | Description | |
|---|---|---|
| User interaction | ||
Attribute default label | The text type attribute to be used as default label for every object type. You can change this on the specific object type configuration too. Note that this affects only for those object types that are created after this setting has changed. | No |
Attribute default description | The description for the default label attribute. You can change this on the specific object type configuration too. | No |
Open Object dialog event | Determines if the object dialog should open when a user selects an object link or when the user hovers with the mouse over an object link. This will also apply when you view Insight object fields while you view a Jira issue. | No |
Default number of objects fetched in custom fields | This indicates the number of objects that Insight will fetch in custom fields for each request. The default value is set to 25. Once the user starts to search any objects on the custom field, more objects matching the search criteria are fetched from server asynchronously. Hence, the default limit of 25 is recommended and should be enough. If you increase this number, it will affect the performance since more objects would then have to be fetched on every request. | No |
| General configuration | ||
Insight Audit Log enabled | If you check this checkbox, it is ensured that all Insight object events are logged to an audit log file. | No |
Include attribute values in audit log | This checkbox is enabled only if the above "Insight Audit Log enabled" is checked. If checked, this will include all attribute values of an object in the audit log. | No |
Restore Insight index from file | This will ensure that on start up, Insight index will be restored from a file. This will help increase the startup time. Insight will perform a consistency check of the file against the database on startup and recreate the index if they mismatch. If you uncheck this, you may experience a slower start up time. However, it could remove the risk of a potential corrupted index file which may cause data inconsistency. By default, this is checked. The file is located at {$JIRA_HOME/caches/insight_indexes} E.g, path of the file on MacOS will be {/var/atlassian/application-data/jira/caches/insight_indexes} | No |
Store cache on shutdown | This indicates that the Insight index should be persisted to a file on Insight shutdown (e.g, in cases of a plugin upgrade, Jira restart, Insight disable etc). It is recommended that if "Restore Insight index from file" is checked, this property should be switched on too. | No |
Restrict Insight Cache | This helps to limit the amount of objects allowed to be stored in Insight. This will subsequently limit the memory footprint by allowing only a limited number of objects to reside in the cache. The default and recommended way to use Insight is to not restrict objects in cache. The limit will have negative performance impact. | Yes |
Number of objects allowed in cache | This is enabled only if "Restrict Insight Cache" is checked. This property indicates the number of Insight objects that will be be stored in the cache. The recommended way is to not limit objects in cache. | Yes |
Maximum File upload size | The maximum file upload size in bytes when uploading files, images, attachments into Insight. | No |
Insight parallelism | This is number of threads that Insight will spawn to perform parallel tasks, e.g, importing data, re-indexing etc. If this number is set to a lower value, Insight will put less strain on Jira. However, it will come at the cost of a low performance speed. | No |
Process data sources via temp files during imports | Temporarily store data on disk when using the import modules to reduce memory footprint during import. | No |
| Use a custom locale for Insight | This is used to indicate if the data stored in Insight should be sorted by a locale other than Jira's default one. Fetching of objects may be slower if this option is switched on. Hence, by default, this is disabled to avoid performance issues. | No |
| The locale for Insight | This is enabled only if "Use a custom locale for Insight" is checked. This determines the language Insight should use when sorting data. | No |
Service Desk portal search text (single) | Placeholder for the Insight field on the Jira Service Desk portals (Single fields) | |
Service Desk portal search text (multi) | Placeholder for the Insight field on the Jira Service Desk portals (Multiple fields) | |
| Dedicated Scheduling Node | This node will be the dedicated node to execute Insight scheduling tasks, such as Importers, Automation, etc. Note that, if a node was selected as the dedicated scheduling node and happens to be unavailable at the time of running a scheduled task, then that task will not run. | No |
Date settings
All dates in Insight use the Jira administrator settings, and can be changed under the following URL:
https://host:port/secure/admin/AdvancedApplicationProperties.jspaLog files
Logs are located in the following directory:
<Jira-shared-home>/logAttachments
Insight attachments are stored accordingly in subfolders named avatars, files, icons, and objects in the following directory:
<Jira_home>/data/attachments/insightIndexing
To open indexing configuration, select Indexing Insight.
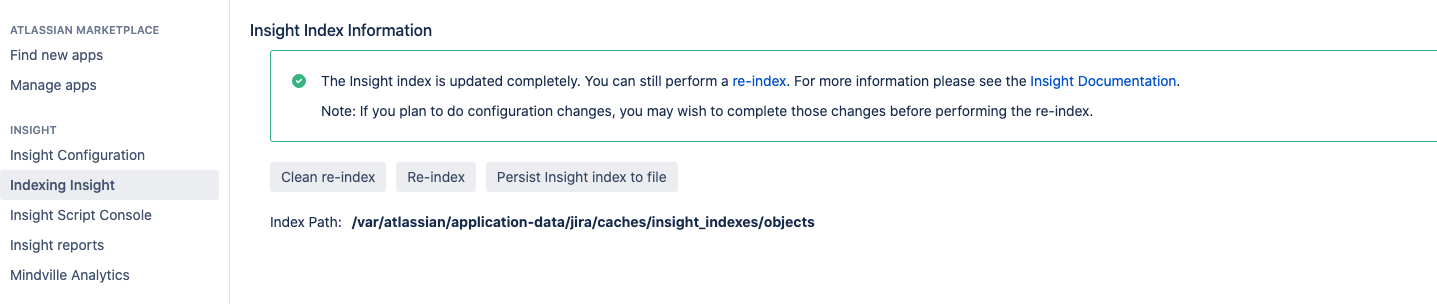
You can select from the following options for indexing:
- Clean re-index
A clean re-index means that all objects will be removed from the index, and then will be indexed again. This is recommended if you want to have a fresh state of the index. Once the indexing is in progress, you won't be able to search for objects or filter them. - Re-index
A re-index means that all objects will stay in the index during the process, and Insight will index them again. You can search for objects during the process. - Persist Insight index to file
You can manually persist (copy) the index on your disk. This is useful if you have a big Insight environment with a large number of objects and are planning to reinstall the app. With the index on your disk, Insight won't have to recreate it from scratch.
Testing Groovy scripts
To test Groovy scripts, select Insight script console. It gives you a quick and easy way to test Groovy scripts that you want to use in Insight automation or post-functions.

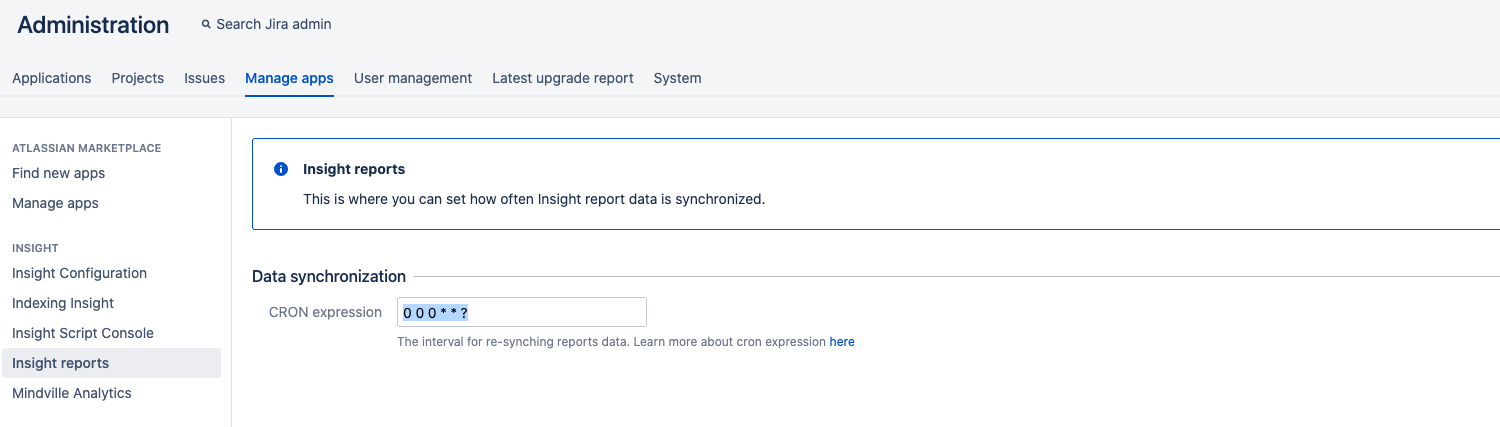
Syncing reports
To open reports syncing configuration, select Insight reports. Here you can set up a cron schedule, which syncs the data in your reports.
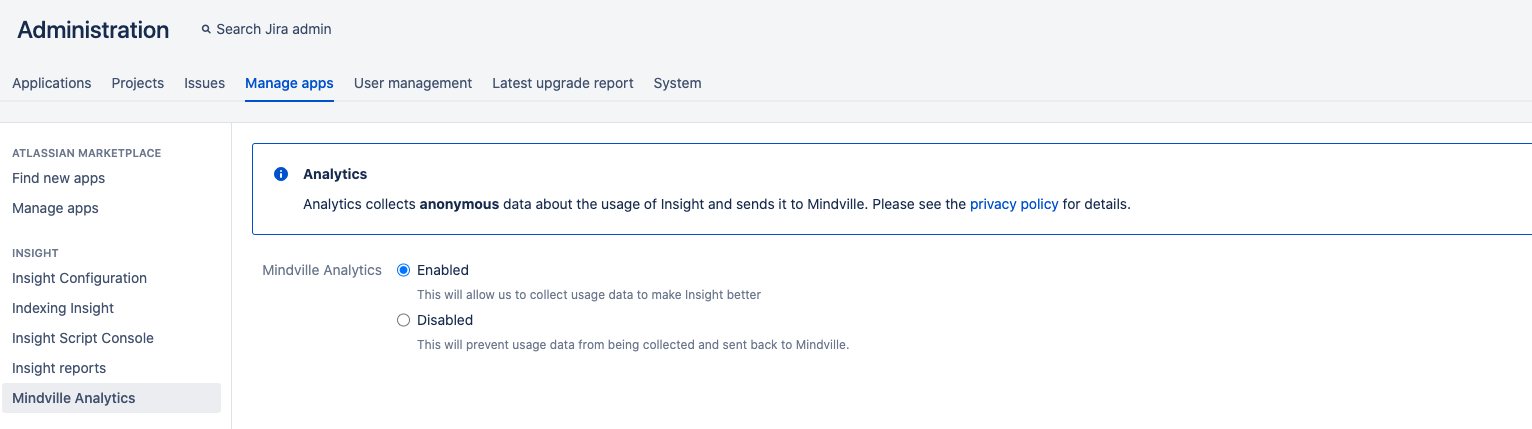
Analytics
To open analytics configuration, select Mindville analytics.
Additional Data Center configuration
Configure data retention period for clustermessage table
Configuring the data retention period helps you avoid performance issues that might result from overloading the clustermessage table. If you import large data sets to Insight in a short period of time, the clustermessage table will be filled with information and can cause performance issues.
To configure the data retention period, complete the following steps:
- Go to Administration > System.
- Scroll down to the Advanced section and select Services.
- Under Add Service, under Class, select Build-in services.
- Select Cluster messaging flush service.
- Enter the following information:
- Name - Cluster Messaging Flush Service
- Class - com.atlassian.jira.service.services.cluster.ClusterMessageCleaningService
- Schedule - 0 0 4/12 * * ?
- Select Add Service.
- Enter the following for Retention Period - 2880m
- Select Update.
