Search JIRA like a boss with JQL
JQL stands for JIRA Query Language (not to be confused with Java Query Language). It’s the most flexible way to search for issues in JIRA and is for everyone: developers, testers, project managers, and even non-technical business users. This blog is intended to be a tutorial for those who have no experience with database queries as well as those who want faster access to information in JIRA. Basically, anyone who works in JIRA can benefit from a little JQL.
If you're a technical person who already knows SQL, you've got a leg up because Atlassian's implementation of JQL is very similar. The search box is even equipped with code hints and inline validation to make constructing queries easy. To try out JQL in your JIRA instance, you can:
- Click Issues > Search for issue
- Click Edit (If you have a search in progress)
- Click Advanced Searching
You can then type your queries directly into JIRA. For a complete reference, check out our help docs on advanced searching. I recommend bookmarking this link – I find myself returning to it often to look up obscure queries. The docs page has a lot of content, so it's helpful to do a "Ctrl/Cmd + F" so you can jump directly to a specific topic or keyword of interest.
You don't have to be technical to use JQL
Let's start with a simple example to help explain fundamental concepts to ground our discussion. If you stepped into an unfamiliar grocery store, you might ask an employee, "Where can I find a package of three Acme cookies?" The clerk would bring you to the right aisle and shelf for that product. JIRA can do the same for issues.
There are two types of searches in JIRA: simple and advanced. Simple search uses a set of forms that a user fills in. The advanced search uses JQL, our very own query language. Not familiar with queries? Queries are a series of simple questions strung together to form a more complex question. A query has three basic parts: fields, operators, and values. You can optionally link them together using a few select keywords. Let's define each term for the context of this discussion (each item is linked to the JQL reference if you want you want to dive deeper!).
- Field - Fields are different types of information in the system. JIRA fields include priority, fixVersion, issue type, date created, etc.
- Value - Values are the actual data in the query: v2.3, Bug, 10/21/2014, etc.
- Operator - Operators are the heart of the query. They relate the field to the value. Common operators include equals (=), not equals (!=), less than (<), etc.
- Keyword - Keywords are specific words in the language that have special meaning. In this post we will be focused on AND and OR.
If we go back to our example of three Acme cookies, we are essentially asking three questions to the store clerk:
- What items in your store are made by the company Acme?
- AND which of those are cookies?
- AND which of those come in packages of three?
Visually we can represent this query using the following Venn diagram. The area of interest to us is the shaded area in the center that involves all three circles.

In the first part of the example, we're using company as the field, equals as the operator, and Acme as the value we're querying on. If we wanted to ask the entire question to the store clerk in a structured way we could say:company = "acme" AND itemtype ="cookie" AND packagequantity = 3
The query states that the company must be Acme, the item must be a cookie, and the quantity needs to be three. Since we want items that meet all three criteria, we use the keyword "AND", which means that the conditions to the left and right of AND have to be met. You can also use OR, which means that only one of the conditions needs to be met. For example, if you want to save money by looking for items on sale or store brand items, we can use this query.
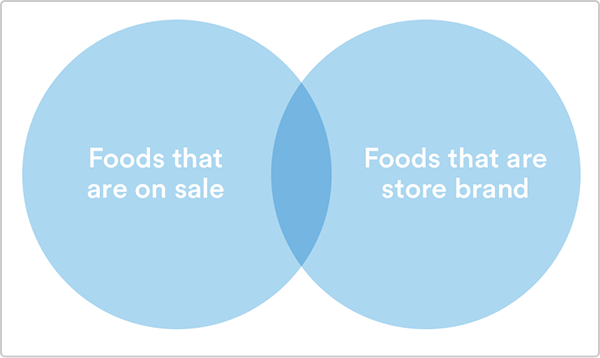
Using an AND would give only the area covered by both circles, but an OR returns all items in either circle. Generally speaking, AND will narrow your query and return fewer results, while using an OR broadens it and will return more results.
Ok, so back to JIRA...
Effective project management requires specific metrics from the issue tracker relevant to your project. JIRA offers a number of fields for you to query. Let's start with a simple example.
What bugs did John Smith file yesterday in the Pipeline project?
reporter = jsmith AND project = PIPELINE and issueType = Bug and createdDate >= -1d
In this example the person filing the bug is stored in the reporter field. JIRA also has a project field that matches the issue key. For example, the issue PIPELINE-2 is in the PIPELINE project. Again, we can set up multiple conditions joined by the AND keyword.
Often times you may want to have the query reference a set of items. Let's go with a slightly more involved example.
What issues are blocking or critical in Projects A, B, and C?
priority in (Blocker, Critical) AND project in (ProjA, ProjB, ProjC)
The "in" keyword will include any item that matches any criteria in the list. In the above example it will return all of the blocker and critical bugs in projects A, B, and C. This is extremely helpful for organizations that have service level agreements (SLA) with their customer base. A JQL query can easily find the issues that aren't meeting the SLA.
What issues are unassigned and have not been updated in the last day?
assignee is EMPTY and updatedDate < -1d
In this query the "is empty" statement tells JIRA to return only issues where the value of the assignee field is blank. This query also shows how JIRA supports relative dates. The value -1d evaluates to 1 day behind the current date when the query is run. As a result, the above query will return all issues that do not have an assignee and haven't been updated in the past day.
Entering JQL in JIRA
Don't be intimidated by JIRA's advanced searching – JIRA's JQL editor makes it easy to learn JQL. The editor offers suggestions and hints as you type, which goes a long way in smoothing out the learning curve. For example, if we enter the following JQL:
project = Pipeline
JIRA gives suggestions at each step of the way for each of the three components of our query. When you see the value you'd like to select, you can use the arrow keys or mouse to select it.

Once the query is complete, JIRA validates the JQL and lets us know the syntax is correct by the green check in the left and side of the text entry box. Note the Syntax Help link, which opens a reference page to the JQL language.

Using JQL functions
We've already talked about how JIRA's fields store data related to an issue: priority, issue key, summary, etc. Functions, however, pack even more power inside of them. Functions contain a lot of complex query logic and mask it so that it's easy for anyone to use. Some functions take input, and all of them return a result. For example, JIRA supports a function called membersof() which returns all users who are members of whatever group (or groups) you specify. Here's a query that returns all issues in the PWC project which are assigned to test engineers:
project = pwc AND assignee in membersof('test-engineering')Functions are powerful because they can react dynamically as the environment changes. If users are added to the test-engineering group, this query will start including issues assigned to the new members. It's a more flexible solution than using assignee in (user1, user2, user3).
Now let's see which issues got fixed in the last release.
project = pwc AND status in (resolved, closed) and fixversion = "Sprint A"
This will return all of the issues that were fixed in that particular release. What if we want a list that always shows the issues fixed in the last release whenever it was run? That's very easy to do with a function.
status in (resolved, closed) and fixVersion = latestReleasedVersion(PWC)
What's the difference here? The first query only returns the list of issues resolved in Sprint A. But eventually the team will release sprints B, C, and D. The second query looks in JIRA to find the last released version for project PWC. Thus as sprints B, C, and D are released this query will pull the right data for those releases. Pretty cool, eh?
JQL-based archeology with history operators
In all the queries we've discussed so far, the data is reflective of the current time the query was run. But values for fields like assignee, priority, fix version, and status often change over the course of an issue's lifecycle. JIRA stores each update an issue goes through, known as an issue's change history.
If you wanted to see all of the issues assigned to John Smith in project PWC, a simple query could find that data:
project = PWC AND assignee = jsmith
Simple enough. But what if we wanted to see the bugs that John Smith resolved in the PWC project? In JQL we can use the following query:
project = PWC AND status CHANGED FROM "In Progress" TO "Resolved" BY jsmith
Sometimes issues that fail verification or get reopened are of special interest and we want to see why a feature didn't work as intended. To find those bugs it's easy to run this query:
status CHANGED FROM "In Progress" TO "Open"
Similarly, to see what issues were in flight during the current week we can use the following JQL:
status was ("In Progress") DURING (startofweek(), endofweek())And at the end of the year it can be nice to see how many issues you resolved during the year. All it takes is a little JQL:
resolution changed to "Fixed" by currentUser() during (startOfYear(), endOfYear())
Scoping and sorting
Part of a good query is knowing how to get data out of JIRA. The other part is knowing how to engage your team and your customers with the result. Let's start with two concepts that are critical to effective data presentation:
- Scoping - Focusing your query so it pulls the right amount of data so the user sees only the information relevant to the current item at hand.
- Sorting - Ordering your data such that the most critical set of data is listed first.
Scoping
Let's take a look at a visual representation of a set of issues that get returned from JIRA.

When searching JIRA, it's easy to perform searches that return too many issues. In the above example both diagrams have the same number of issues we care about (issues with A on them) but the first query isn't specific enough. How does this play out in the real world? Development managers often have to find areas of risk in their programs. Good queries often take a bit of refinement as they get developed. Let's see if we can find some risky areas in our project PWC.
Starting with open issues:
project = pwc AND status = open
We find that query returns too many issues as it includes everything from the PWC project's backlog. We can tighten it up a bit by eliminating the backlog issues.
project = pwc AND status = open AND fixVersion = "Current Sprint"
This result is better, but now I'm curious to know what didn't make last sprint and got moved into this sprint.
project = pwc AND status = open AND fixVersion = "Current Sprint" AND fixVersion WAS "Last Sprint"
Now that I have the issues that I really care about in front of me, I'm able to look at each of these issues with a high degree of focus and figure out why they didn't make the last sprint. Was it an estimation problem? Unclear requirements? Something else? The issues were there in the first query, but they were too hard for me to find manually. Good query creation is an iterative process: query, review, see if you can narrow down the results. The more you do, the easier it is to find what you're looking for.
Sorting
Let's take another look at issues returned from JIRA. This time we have our query properly scoped. (Yay!)
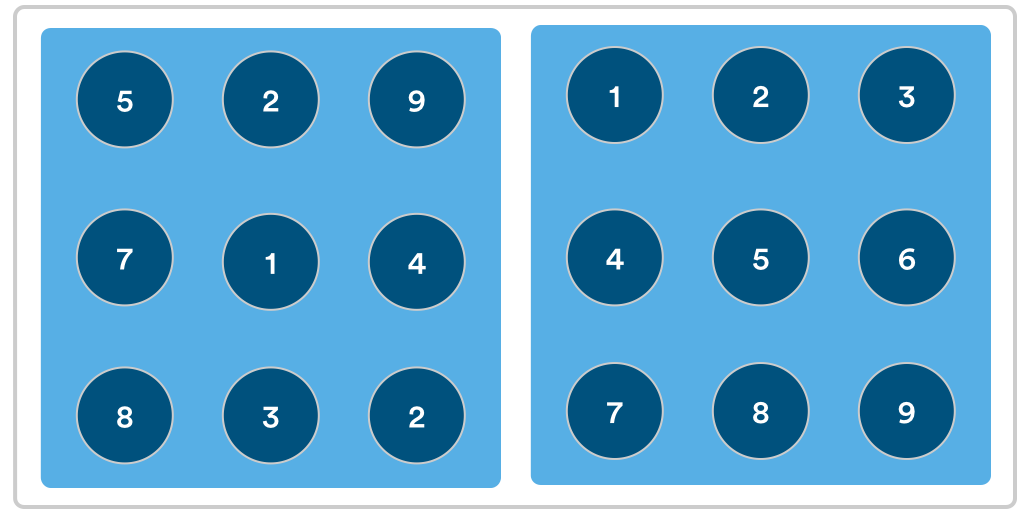
Both diagrams have the same issues in them. The set on the right is easier to process as we've given the reader a natural guide to follow (i.e., they're presented in numerical order). The easier the data is for you and your team to consume, the easier it is to plan what to do next. Let's say we want to see all the bugs open for our team in a particular sprint:
project = pwc AND fixVersion = "Current Sprint" AND status = open
Now we need to ask ourselves what we're trying to glean from this data. If we're trying to understand risk we might want to see the list ordered by priority and then by engineer so that we can easily see if one engineer has two high priority bugs. JQL has the keyword ORDER BY that tells JIRA to sort the results. So we want JIRA to first order the list by priority, then do a secondary sort by assignee. So we can modify the query to include sorting:
project = pwc AND fixVersion = "Current Sprint" AND status = open ORDER BY priority, assignee
Let's look at another example examining the incoming bugs for our project. We want to see any new critical or blocking bugs that have come in recently to see if recent checkins have decreased stability.
project = pwc AND priority in (blocker, critical) AND created > -2w ORDER BY created DESC
The query controls for priority and limiting the created time properly scopes the query. What the sorting does is show us the most recent issues first. We use the DESC keyword to sort in reverse (newest to oldest) so we focus our attention on the most important issues first.
Caveat: If another system will process your results before a user sees them, don't bother sorting via JQL – sorting twice will only make your searches and reports take longer.
Developers: it's time to REST
JIRA has a stable REST API to access issues that lets you use the same JQL you do in the UI. The REST endpoint for search returns structured JSON data that's easy to process and manipulate.
For example, you can run this command in the terminal on the Macintosh or Linux workstation. (Windows users will need to get curl.) If we want to grab all of the duplicate issues from the ANERDS project we could simply call the search REST endpoint.
The query will return JSON which you can then process in your client application.
There's a lot more you can do with JQL than what I've covered here. But hopefully you feel grounded in the basics now. Check out our help docs about advanced searching for complete lists of JQL operators, keywords, and functions, as well as our knowledge base article on JQL performance for you power-users out there. Happy searching!
Hungry for more?
Watch the blogs in this space to get notified when new tips articles like this are posted. And if that's still not enough, sign up for JIRA Insiders – our monthly newsletter covering all things JIRA.
![]() Written by Dan Radigan, Technical Account Manager
Written by Dan Radigan, Technical Account Manager