Clustering with Bitbucket
Benefits of clustering
Clustering is designed for enterprises with large or mission-critical Data Center deployments that require continuous uptime, instant scalability, and performance under high load.
Here are some of the benefits:
High availability and failover
If one node in your cluster goes down, the others take on the load, ensuring your users have uninterrupted access to Bitbucket.
Performance at scale
Each node added to your cluster increases concurrent user capacity, and improves response time as user activity grows.
Instant scalability
Add new nodes to your cluster without downtime or additional licensing fees. Data and apps are automatically synced.
Upgrade with no downtime
Perform a rolling upgrade to the latest bug fix update of your feature release, without any downtime. Apply critical bug fixes and security updates to your site while providing users with uninterrupted access to Bitbucket.
Architecture
The image below shows a typical configuration:
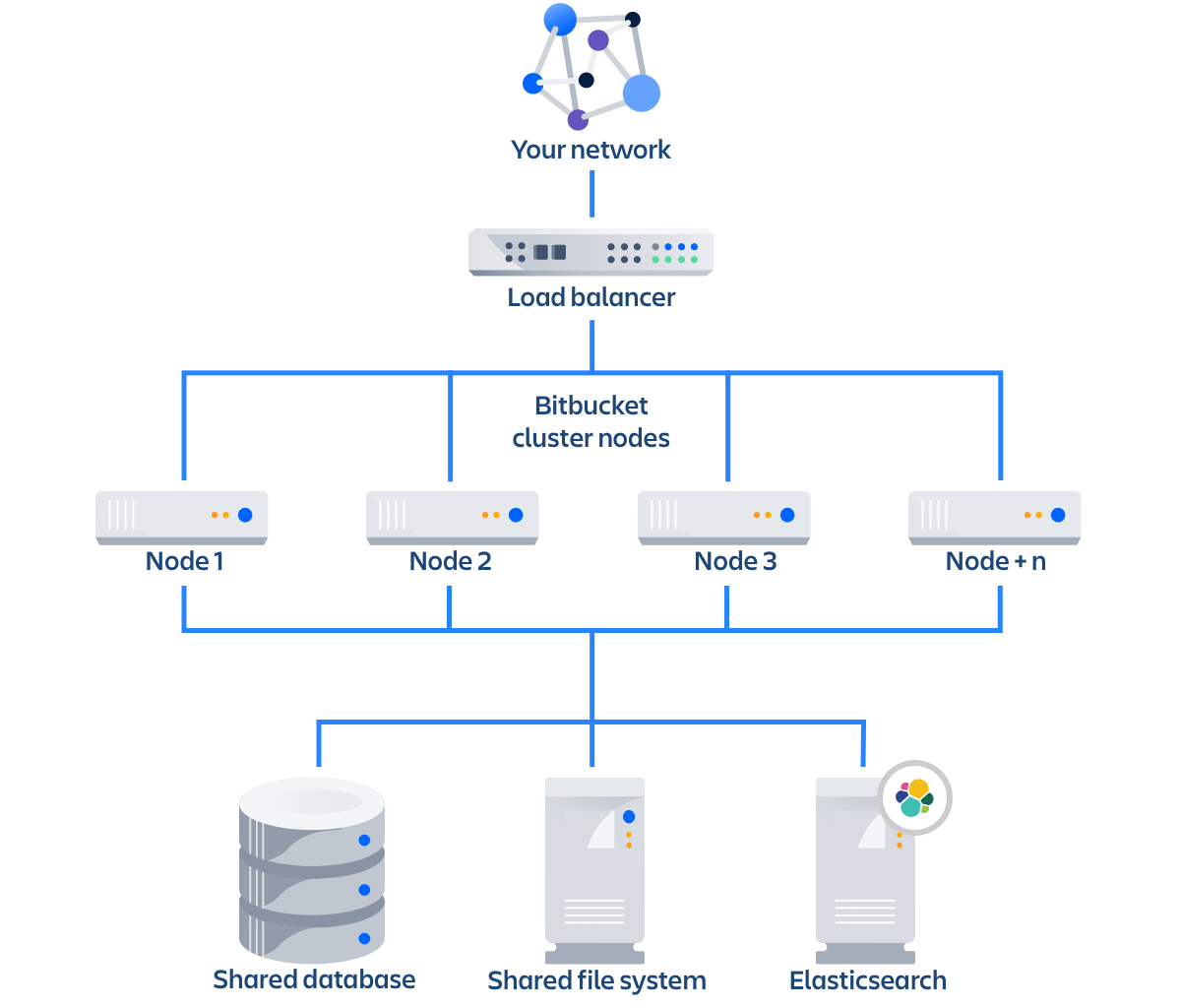
A Bitbucket Data Center cluster consists of:
Multiple identical application nodes running Bitbucket Data Center.
A load balancer to distribute traffic to all of your application nodes.
A shared file system that stores repositories, attachments, and other shared files.
A database that all nodes read and write to.
An Elasticsearch instance that enables searching for projects, repositories, and code
All application nodes are active and process requests. A user will access the same Bitbucket node for all requests until their session times out, they log out, or a node is removed from the cluster.
Learn more
Infrastructure and requirements
The choice of hardware and infrastructure is up to you. Below are some areas to think about when planning your hardware and infrastructure requirements.
Deploying Bitbucket Data Center on AWS and Azure
If you plan to run Bitbucket Data Center on AWS or Azure, you can use our templates to deploy the whole infrastructure. You’ll get your Bitbucket Data Center nodes, Elasticsearch, database and storage all configured and ready to use in minutes. For more info, see the following resources:
Server requirements
You should not run additional applications (other than core operating system services) on the same servers as Bitbucket. Running Bitbucket, Jira, and Confluence on a dedicated Atlassian software server works well for small installations but is discouraged when running at scale.
Bitbucket Data Center can be run successfully on virtual machines.
Cluster nodes requirements
Each node does not need to be identical, but for consistent performance we recommend they are as close as possible. All cluster nodes must:
be a dedicated machine, physical or virtual
be located in the same data center, or region (for AWS and Azure)
be connected in a high speed LAN (that is, high bandwidth and low latency)
have the same OS, Java and application server version. See Supported platforms
have the same memory configuration (both the JVM and the physical memory) (recommended)
be configured with the same time zone (and keep the current time synchronized). Using ntpd or a similar service is a good way to ensure this
- Although a password is used to authenticate the nodes, we recommend that you use a firewall and/or network segregation to make sure that only specific nodes are allowed to connect to a Bitbucket cluster node’s Hazelcast port, which by default is port 5701
You must ensure the clocks on your nodes don't diverge, as it can result in a range of problems with your cluster.
How many nodes?
Your Data Center license does not restrict the number of nodes in your cluster. The right number of nodes depends on the size and shape of your Bitbucket instance, and the size of your nodes.
See our Bitbucket Data Center load profiles guide for help sizing your instance. In general, we recommend starting small and growing as you need.
Database
You should ensure your intended database is listed in the current Supported platforms, with one exception: we do not support MySQL due to inherent deadlocks that can occur in this database engine at high load. The load on an average cluster solution is higher than on a standalone installation, so it is crucial to use a supported database.
Additional requirements for database high availability
Running Bitbucket Data Center in a cluster removes the application server as a single point of failure. You can also do this for the database through the following supported configurations:
Amazon RDS Multi-AZ: this database setup features a primary database that replicates to a standby in a different availability zone. If the primary goes down, the standby takes its place.
Amazon PostgreSQL-Compatible Aurora: this is a cluster featuring a database node replicating to one or more readers (preferably in a different availability zone). If the writer goes down, Aurora will promote one of the writers to take its place.
The AWS Quick Start deployment option allows you to deploy Bitbucket Data Center with either one, from scratch. If you want to set up an Amazon Aurora cluster with an existing Bitbucket Data Center instance, refer to Configuring Bitbucket Data Center to work with Amazon Aurora.
Shared home and storage requirements
Bitbucket Data Center requires a high performance shared file system such as a SAN, NAS, RAID server, or high-performance file server optimized for I/O.
The shared file system must run on a dedicated machine.
The file system must be available to all cluster nodes via a high-speed LAN (it must be in the same physical data center).
The shared file system should be accessible via NFS as a single mount point.
- Due to known performance issues, we only support NFSv3 at this time.
Load balancer
You can use the load balancer of your choice. Bitbucket Data Center does not bundle a load balancer.
Your load balancer should run on a dedicated machine.
Your load balancer must have a high-speed LAN connection to the Bitbucket cluster nodes (that is, high bandwidth and low latency).
Your load balancer must support both HTTP mode (for web traffic) and TCP mode (for SSH traffic).
Terminating SSL (HTTPS) at your load balancer and running plain HTTP from the load balancer to Bitbucket is highly recommended for performance.
Your load balancer should support "session affinity" (also known as "sticky sessions").
If you don't have a preference for your load balancer, we provide instructions for haproxy, a popular Open Source software load balancer.
Many load balancers require a URL to constantly check the health of their backends in order to automatically remove them from the pool. It's important to use a stable and fast URL for this, but lightweight enough to not consume unnecessary resources. The following URL returns Jira’s status and can be used for this purpose.
| URL | Expected content | Expected HTTP status |
|---|---|---|
http://<bitbucketurl>/status | {"state":"RUNNING"} | 200 OK |
Here are some recommendations, when setting up monitoring, that can help a node survive small problems, such as a long GC pause:
Wait for two consecutive failures before removing a node.
Allow existing connections to the node to finish, for say 30 seconds, before the node is removed from the pool.
For more info, see Load balancer configuration options or Install Bitbucket Data Center (section about configuring the load balancer).
Network adapters
Use separate network adapters for communication between servers. Cluster nodes should have a separate physical network (i.e. separate NICs) for inter-server communication. This is the best way to get the cluster to run fast and reliably. Performance problems are likely to occur if you connect cluster nodes via a network that has lots of other data streaming through it.
Elasticsearch node
Bitbucket Data Center requires a connection to a remote Elasticsearch installation to enable code search. Although code search is not critical for high availability, it is possible run a cluster of Elasticsearch nodes to achieve high availability for the Bitbucket's code search index. The easiest way to set up and deploy an Elasticsearch cluster for Bitbucket Data Center is to use the Amazon's Elasticsearch service, but you can also set up a remote Elasticsearch instance on your own hardware.
Requirements:
Bitbucket Data Center currently works with Elasticsearch 5.5.1 - 5.5.3, 6.5.3, and 6.8.6.
Bitbucket Data Center can have only one remote connection to Elasticsearch for your cluster.
This may be a standalone Elasticsearch installation or a clustered installation behind a load balancer.
For more info, see Administer code search and How to install Elasticsearch.
App compatibility
The process for installing Marketplace apps (also known as add-ons) in a Bitbucket cluster is the same as for a standalone installation. You will not need to stop the cluster, or bring down any nodes to install or update an app.
The Atlassian Marketplace indicates apps that are compatible with Bitbucket Data Center. Learn more about Data Center approved apps
Ready to get started?
Head to Set up a Bitbucket Data Center cluster for a step-by-step guide to enabling and configuring your cluster.