Setting up a Bitbucket Data Center failover instance
Please note: Atlassian do not offer architecture design consulting services and therefore we cannot advise you on what your architecture design should look like for your needs. This article intends to provide some basic guidelines for setting up a failover instance of Bitbucket Data Center. If you require in depth assistance or consultation you can contact our Experts team.
Routing
In the event of a full outage of the Active DC you ideally want to seamlessly redirect the existing incoming traffic from users and other dependent services to the Standby DC. Whilst it's possible to achieve this by reconfiguring your DNS records to point to the new instance, there is a brief period governed by your DNS record's TTL where traffic is not guaranteed to be redirected to the new location. In this scenario you may wish to introduce a global load balancer that handles all incoming traffic and directs it to the appropriate Data Center instance. Note that in this scenario, the global load balancer is separate from the individual Data Center load balancers that distribute traffic amongst individual nodes within a single DC instance. An example network diagram might look like this:
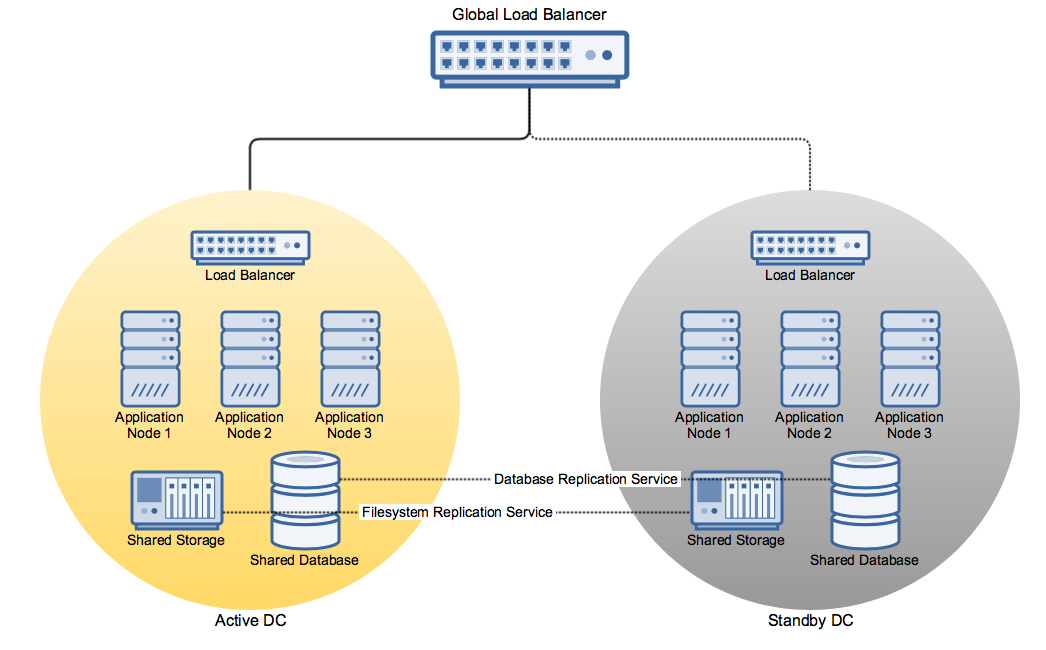
Note: This diagram is for illustration purposes only and does not represent a recommended implementation
Replication
In replicating your instance to another location there are three primary considerations: the Database, the File System and the Application Installation itself.
Please note that Atlassian makes no recommendation for particular tools or solutions to achieve replication across these areas.
Database
You will need to fully replicate your database to the secondary location. You need to ensure that your solution is capable of handling any potential intermittent failures and of self-healing in the event of a temporary connection failure. Both database instances should maintain the exact same version if possible, to ensure against any unknown behaviour across RDBMS versions. All supported database vendors provide their own database replication solutions:
File System
Similarly, you will need to fully replicate the contents of your application's HOME directory to the replica file system. This mechanism should also be self-healing and/or able to withstand a temporary connection failure.
Application Installation
The Atlassian applications on the Standby DC nodes should be kept up to date with the Active DC version. Scheduled maintenance to perform upgrades on the Active DC should always include steps to perform the same upgrade on the Standby DC nodes. Note that once again, the applications should not be started on the standby DC.
Any configuration files located in the installation directories that manage the configuration of the JVM environment, Tomcat, etc. should also be kept in sync across the Active and Standby DC.
Other Considerations
Depending on the version of Bitbucket Server in use, there are some specific considerations you should make to determine your architectural needs
Bitbucket Server
- Bitbucket Server 4.3 introduces Mirrors for customers with a Data Center license. This feature allows you to provision mirror instances that can be located in different geographic reasons to enable faster downstream fetching for geographically distributed teams and is also a great solution for CI systems to reduce the load on your primary instance. A mirror instance can potentially fail over from the active DC to the standby DC invisibly, for instance if you have a global load balancer set up or some other mechanism whereby the Smart Mirror can continue to reach the Standby DC via the same routes.
- Bitbucket Server 4.6 introduces Code Search. In a Data Center configuration, it would be necessary to install and configure a remote Elasticsearch instance to make use of this feature, as the built-in Elasticsearch instance is not suitable for a multi-node DC deployment. This is something for you to keep in mind as it impacts your requirements in setting up a secondary standby DC instance, and is another system you would need to investigate a replication scenario for. Note that if you choose not to replicate the Elasticsearch instance, code search would be initially unavailable during a failover event whilst the index was rebuilt and could take a number of minutes or hours to completely reindex all of your repositories.