Set up a Confluence Data Center cluster
Clustering with AWS and Azure
You can also choose to deploy a Data Center cluster on public cloud providers, like AWS (Amazon Web Services) and Azure. We have specific guides and deployment templates to help you easily configure a cluster in AWS or Azure. Check them out to find out what's required.
Before you begin
Clustering requirements
To use Confluence Data Center you must:
- Have a Data Center license (you can purchase a Data Center license or create an evaluation license at my.atlassian.com)
- Use a supported external database, operating system and Java version
- Use OAuth authentication if you have application links to other Atlassian products (such as Jira)
To run Confluence in a cluster you must also:
Use a load balancer with session affinity in front of the Confluence cluster. WebSockets support is also recommended for collaborative editing.
- Have a shared directory accessible to all cluster nodes in the same path (this will be your shared home directory). This must be a separate directory, and not located within the local home or install directory.
See Clustering with Confluence Data Center for a complete overview of hardware and infrastructure considerations.
Security
Ensure that only permitted cluster nodes are allowed to connect to the following ports through the use of a firewall and / or network segregation:
- 5801 - Hazelcast port for Confluence
- 5701 - Hazelcast port for Synchrony
- 25500 - Cluster base port for Synchrony
If you use multicast for cluster discovery:
- 54327- Multicast port for Synchrony (only required if running Synchrony standalone cluster)
Terminology
In this guide we'll use the following terminology:
- Installation directory – The directory where you installed Confluence.
- Local home directory – The home or data directory stored locally on each cluster node (if Confluence is not running in a cluster, this is simply known as the home directory).
- Shared home directory – The directory you created that is accessible to all nodes in the cluster via the same path.
Set up and configure your cluster
We recommend completing this process in a staging environment, and testing your clustered installation, before moving to production.
1. Back up
We strongly recommend that you backup your existing Confluence local home and install directories and your database before proceeding.
2. Create a shared home directory
- Create a directory that's accessible to all cluster nodes via the same path. This will be your shared home directory.
- In your existing Confluence home directory, move the contents of
<local home directory>/shared-hometo the new shared home directory you just created. To prevent confusion, we recommend deleting the empty<local home directory>/shared-homedirectory once you've moved its contents. - Move your
<local home>/attachments>directory to the new<shared home>/attachmentsdirectory.
4. Enable cluster mode
Before you enable cluster mode, you should be ready to restart Confluence and configure your cluster. This will require some downtime.
- Start Confluence.
- Go to
 > General Configuration.
> General Configuration. - Choose Clustering from the sidebar.
- Select Enable cluster mode.
- Select Enable to confirm you’re ready to proceed.
5. Restart Confluence
Restart Confluence to configure your cluster. Once you restart, Confluence will be unavailable until you’ve completed the set up process.
6. Configure your cluster
The setup wizard will prompt you to configure the cluster, by entering:
- A name for your cluster
- The path to the shared home directory you created earlier
- The network interface Confluence will use to communicate between nodes
How you want Confluence to discover cluster nodes:
- Multicast - enter your own multicast address or automatically generate one.
- TCP/IP - enter the IP address of each cluster node
AWS - enter your IAM Role or secret key, and region.
If Synchrony is managed by Confluence, the same network settings will be applied to Synchrony.
Follow the prompts to create the cluster.
When you restart, Confluence will start setting up the cluster. This can take a few minutes. Some core components of Confluence will also change to become cluster compatible. For example, Confluence will switch to a distributed caching layer, managed by Hazelcast.
![]() Do not restart Confluence until your cluster is set up, and Confluence is back up and running.
Do not restart Confluence until your cluster is set up, and Confluence is back up and running.
Add more Confluence nodes
Your Data Center license doesn’t restrict the number of nodes in your cluster. To achieve the benefits of clustering, such as high availability, you’ll need to add at least one additional cluster node.
We’ve found that typically between 2 and 4 nodes is sufficient for most organizations. In general we recommend starting small and growing as needed.
7. Copy Confluence to the second node
To copy Confluence to the second node:
- Shut down Confluence on node 1.
- Copy the installation directory from node 1 to node 2.
- Copy the local home directory from node 1 to node 2.
Copying the local home directory ensures the Confluence search index, the database and cluster configuration, and any other settings are copied to node 2.
Copying the local home directory ensures the Confluence search index, the database and cluster configuration, and any other settings are copied to node 2.
Make sure your database has sufficient connections available to support the number of nodes.
8. Configure your load balancer
Configure your load balancer for Confluence. You can use the load balancer of your choice, but it needs to support session affinity and WebSockets.
You can verify that your load balancer is sending requests correctly to your existing Confluence server by accessing Confluence through the load balancer and creating a page, then checking that this page can be viewed/edited by another machine through the load balancer.
See Clustering with Confluence Data Center for further load balancer guidance.
9. Start Confluence one node at a time
You must only start Confluence one node at a time. The first node must be up and available before starting the next one.
- Start Confluence on node 1
- Wait for Confluence to become available on node 1
- Start Confluence on node 2
- Wait for Confluence to become available on node 2.
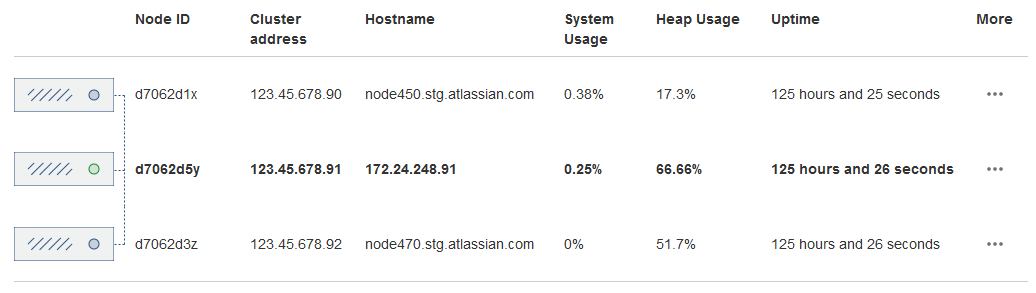
The Cluster monitoring console (![]() > General Configuration > Clustering) shows information about the active cluster.
> General Configuration > Clustering) shows information about the active cluster.
When the cluster is running properly, this page displays the details of each node, including system usage and uptime. Use the  menu to see more information about each node in the cluster.
menu to see more information about each node in the cluster.
10. Test your Confluence cluster
To test creating content you'll need to access Confluence via your load balancer URL. You can't create or edit pages when accessing a node directly.
A simple process to ensure your cluster is working correctly is:
- Access a node via your load balancer URL, and create a new document on this node.
- Ensure the new document is visible by accessing it directly on a different node.
- Search for the new document on the original node, and ensure it appears.
- Search for the new document on another node, and ensure it appears.
If Confluence detects more than one instance accessing the database, but not in a working cluster, it will shut itself down in a cluster panic. This can be fixed by troubleshooting the network connectivity of the cluster.
11. Set up a Synchrony cluster (optional)
Synchrony is required for collaborative editing. You have two options for running Synchrony with a Data Center license:
- managed by Confluence (recommended)
This is the default setup. Confluence will automatically launch a Synchrony process on the same node, and manage it for you. No manual steps are required. - Standalone Synchrony cluster (managed by you)
You deploy and manage Synchrony standalone in its own cluster with as many nodes as you need. Significant setup is required. See Set up a Synchrony cluster for Confluence Data Center for a step-by-step guide.
Head to Administering Collaborative Editing to find out more about collaborative editing.
Troubleshooting
If you have problems with the above process, check our cluster troubleshooting guide.
We’re here to help
Need help setting up your cluster? There are a range of support services available to help you plan and implement a clustered Data Center installation.
- An Atlassian Technical Account Manager can provide strategic guidance. They work with you to develop best practices for configuring, deploying and managing Confluence in a cluster.
- The Atlassian Premier Support team can provide technical support. Premier Support also offers health check analyses to validate the readiness of your environment.
- Atlassian Enterprise Partners offers a wide array of services to help you get the most out of your Atlassian tools.
- You can also ask questions in the Atlassian Community.