Unable to start Crowd: "This Crowd instance was unable to start the scheduler CrowdSchedulerService, and will not be usable."
Platform notice: Server and Data Center only. This article only applies to Atlassian products on the Server and Data Center platforms.
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
After starting Crowd and trying to access it, the following error message is shown:
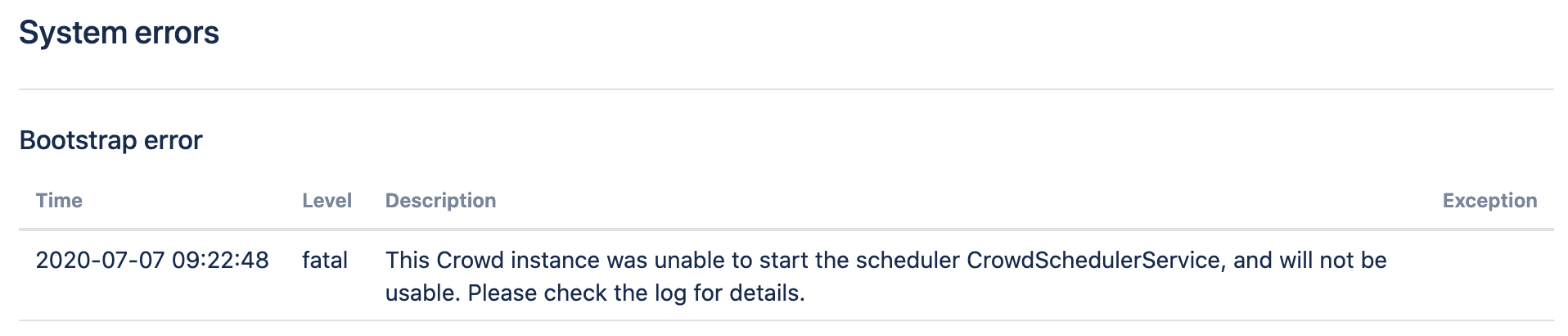
Checking the application logs you can see that a Duplicate Key in the database table caused the IllegalStateException:
2020-07-07 09:22:48,694 localhost-startStop-1 ERROR [atlassian.event.internal.AsynchronousAbleEventDispatcher] There was an exception thrown trying to dispatch event [com.atlassian.config.lifecycle.events.ApplicationStartedEvent@49ee9103] from the invoker [SingleParameterMethodListenerInvoker{method=public void com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(com.atlassian.config.lifecycle.events.ApplicationStartedEvent) throws com.atlassian.scheduler.SchedulerServiceException, listener=com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle@5ac44666}]
java.lang.RuntimeException: java.lang.IllegalStateException: Duplicate key Tue Jul 07 18:50:03 BRT 2020. Listener: com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle event: com.atlassian.config.lifecycle.events.ApplicationStartedEvent
...
Caused by: java.lang.RuntimeException: java.lang.IllegalStateException: Duplicate key Tue Jul 07 18:50:03 BRT 2020
...
Caused by: java.lang.IllegalStateException: Duplicate key Tue Jul 07 18:50:03 BRT 202The stack trace at the default log level doesn't show which table has the duplicate key.
Environment
Crowd 3.7.0
Diagnosis
To find out which table has the duplicate key, you'll have to Enable SQL Logging in Crowd. This will produce a large amount of information about the SQL queries executed during Crowd startup.
The last query displayed before the IllegalStateException will contain the table name, in this case cwd_cluster_job:
2020-07-06 18:30:28,754 localhost-startStop-1 DEBUG [org.hibernate.SQL] select internalcl0_.id as col_0_0_, internalcl0_.next_run_timestamp as col_1_0_ from cwd_cluster_job internalcl0_ where internalcl0_.next_run_timestamp is not null Cause
Due to some unknown reason, a constraint is missing at the table when compared to the same table in a fresh installation.
The lack of this constraint allowed a duplicate record to be inserted in that table.
Solution
- Compare the constraints of the table mentioned in the logs with the same table in a fresh installation, using the same Crowd version. In this example, the unique constraint on cwd_cluster_job is pk_cwd_cluster_job and contains a single column id
- Identify the duplicate record by grouping values by the unique constraint, as for example:
select count(*), id from cwd_cluster_job group by id having count(*) > 1; - Stop Crowd
- Ensure to perform a database backup before removing any record from the database
- Delete one of the duplicate rows
- In case the rows are slightly different, you can compare the values with a fresh installation
- In case the rows are completely identical, any of them can be removed
Add the unique constraint back to the table. In this example, for PostgreSQL:
ALTER TABLE ONLY cwd_cluster_job ADD CONSTRAINT pk_cwd_cluster_job PRIMARY KEY (id);- Start Crowd again
- Check the logs for any other possible Duplicate key error. In case you hit the same error message, repeat the process to identify the next duplicate record