Data pipeline export schema
This page describes the structure and data schema of the Jira data export files.
To learn more about how to set up and configure your data pipeline, see Data pipeline.
- Each file has a header. This includes files from exports that resulted in no data.
- New lines are separated by CRLF characters
\r\n. - Fields containing line breaks (CRLF), double quotes, and commas are enclosed in double quote.
- If double-quotes are present inside fields, then a double-quote appearing inside a field are escaped by preceding it with another double quote. For example:
"aaa","b""bb","ccc". - Fields with no data (null values) are represented in the CSV export by two consecutive delimiters (as in,
,,). - Embedded break lines are escaped by default and printed as n.
Availability
Output
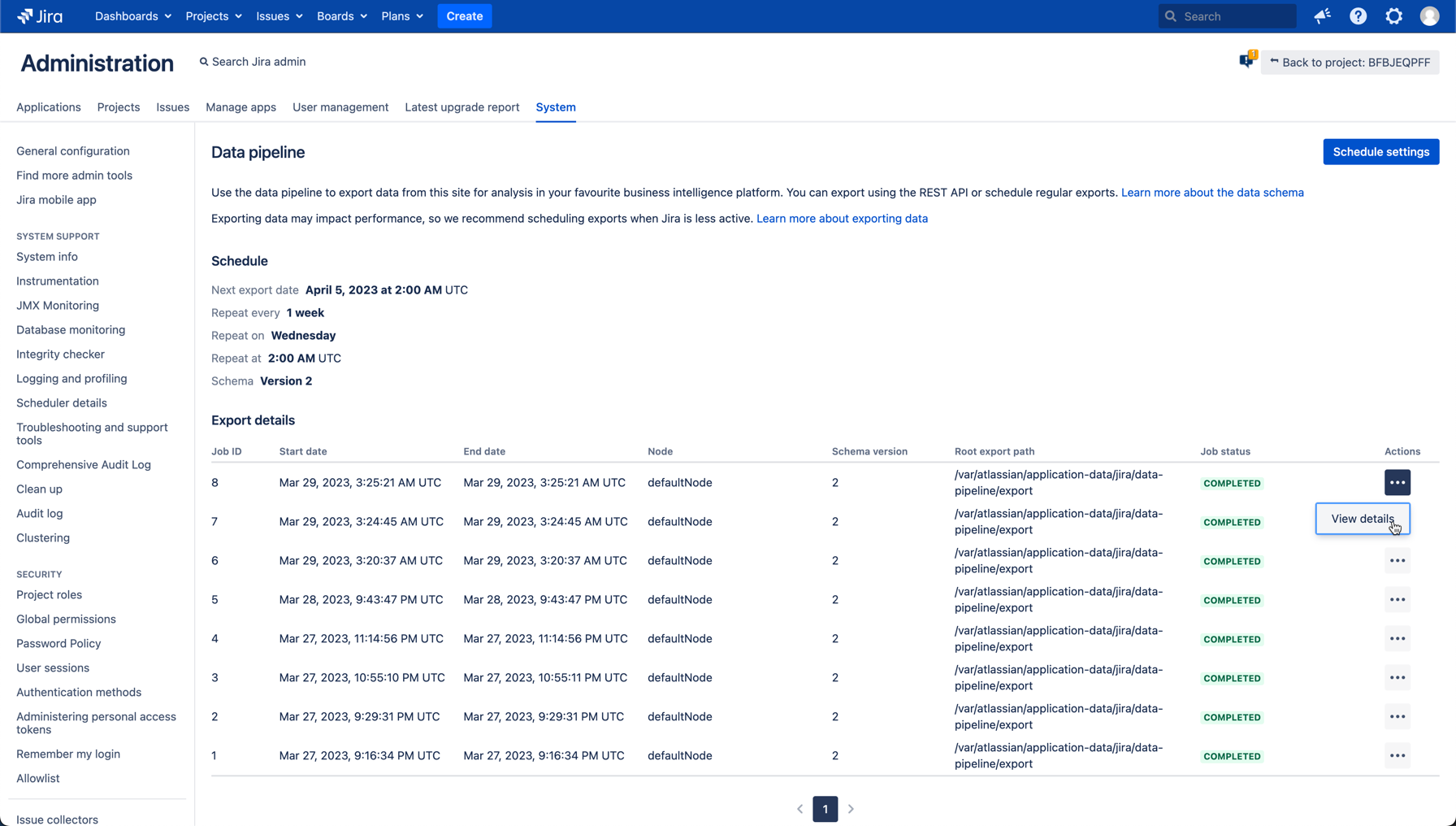
To access the export details:
Go to Administration > System > Data pipeline.
From the Export details list select Actions > View details.
3. You’ll find the export time in the exportFrom line.
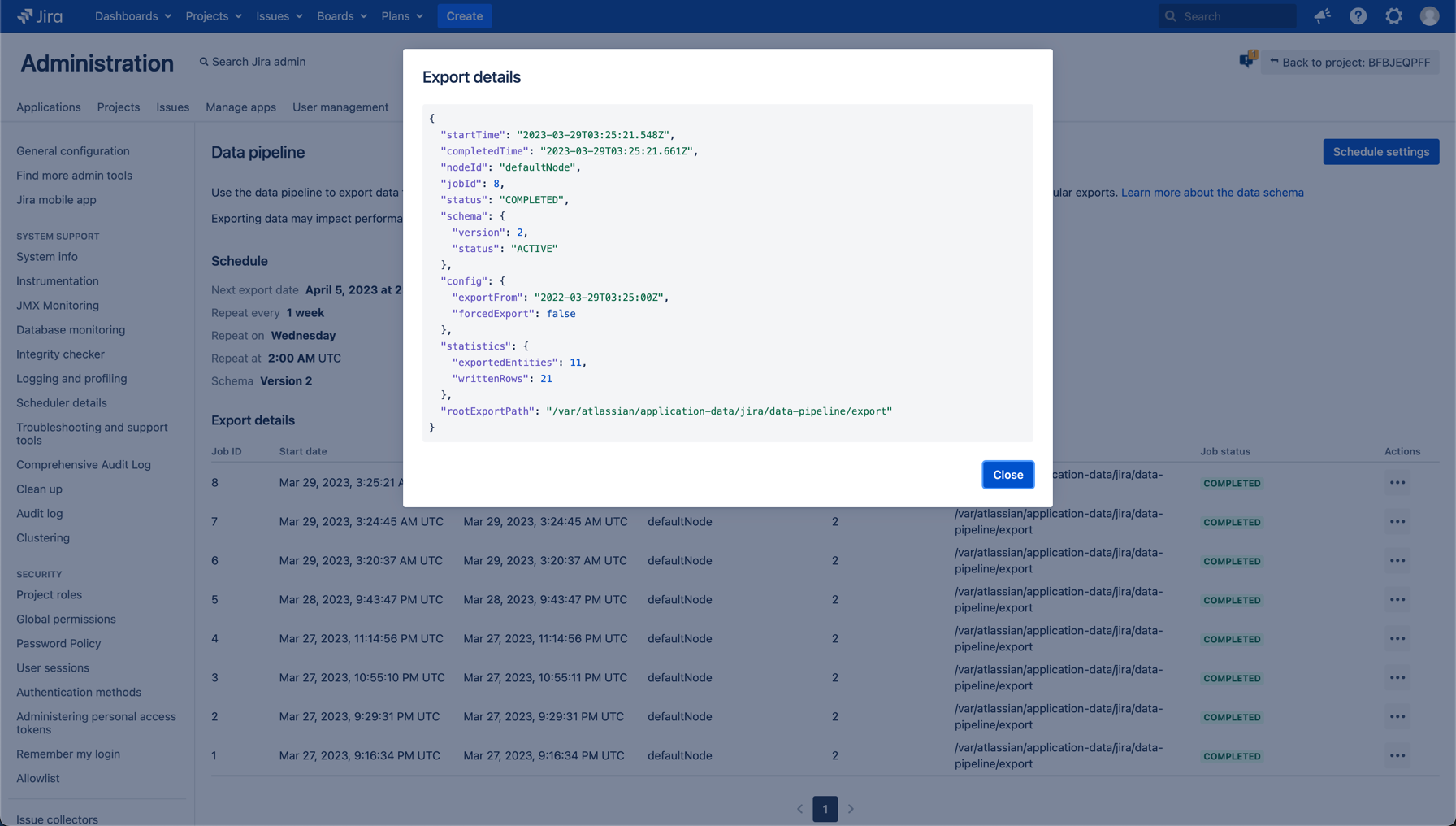
If an issue or an issue link was permanently deleted, it won’t be found in these files. For all historical changes, you should consult the issue_history file.
The fromDate, which by default includes the last year, refers to querying for issues and their metadata updated since the supplied timestamp.
On this page:
Issues schema
JIRA SOFTWARE JIRA SERVICE MANAGEMENT
issues CSV file. | Field | Description |
|---|---|
id (Primary Key) | Type: Number Description: Unique ID of this issue. Use as Primary Key. Example: |
| instance_url | Type: String Description: Base url of the current instance Example: |
| url | Type: String Description: URL of the issue Example: |
| key | Type: String Description: Unique Key for this issue Example: |
| project_key | Type: String Description: Key of the project this issue is in Example: |
| project_name | Type: String Description: Title of the project this issue is in Example: |
| project_type | Type: String Description: Type of the project this issue is in (can be Business, Software, Service Desk) Example: |
| project_category | Type: String Description: Assigned category for the project this issue is in Example: |
| issue_type | Type: String Description: Type of issue (for example, task, bug, or epic) Example: |
| summary | Type: String Description: Summary of the issue Example: |
| description | Type: String Description: Description of the issue (limited to 2000 characters) Example: |
| creator_id | Type: Number Description: Unique identifier of the user who created the issue, regardless of directory Example: |
| creator_name | Type: String Description: Name of the user issue creator Example: Schema: Version 1 only. This data is now contained in the Users file. |
| reporter_id | Type: Number Description: Unique identifier of the issue reporter, regardless of directory Example: |
| reporter_name | Type: String Description: Name of the issue reporter Example: Schema: Version 1 only. This data is now contained in the Users file. |
| assignee_id | Type: Number Description: Unique identifier of the issue assignee, regardless of directory Example: |
| assignee_name | Type: String Description: Name of the issue assignee Example: Schema: Version 1 only. This data is now contained in the Users file. |
| status | Type: String Description: Current status of this issue Example: |
| status_category | Type: String Description: Status category for the current status for this issue Example: |
| priority_sequence | Type: String Description: The priority order (admins can change this which will result in non-deterministic priority orders) Example: |
| priority_name | Type: String Description: Name of the priority for this issue Example: |
| resolution | Type: String Description: The final status of an issue. Jira considers the workflow of an Issue complete once a value is present in the resolution field. Example: |
| watcher_count | Type: Number Description: Number of users watching this issue Example: |
| vote_count | Type: Number Description: Number of votes for this issue Example: |
| created_date | Type: Date Description: UTC timezone creation date of this issue (ISO string) Example: |
| resolution_date | Type: Date Description: UTC timezone resolution date of this issue (ISO string) Example: |
| updated_date | Type: Date Description: UTC timezone date that this issue was last updated (ISO string) Example: 2020-11-05T14:44:57Z |
| due_date | Type: Date Description: UTC timezone date that this issue is due to be completed (ISO string) Example: |
| estimate | Type: Number Description: Estimate time remaining from original estimate, in seconds (requires time-tracking enabled) Example: |
| original_estimate | Type: Number Description: Original estimate that was set, in seconds (requires time-tracking enabled) Example: |
| time_spent | Type: Number Description: Amount of logged work, in seconds (requires time-tracking enabled). Field is null if there is no time spent. Example: |
| labels | Type: String Description: JSON array of label names. Field is null if there are no labels. Example: |
| components | Type: String Description: JSON array of component names. Field is null if there are no labels. Example: |
| parent_id | Type: Number Description: ID of the parent issue. Field is null if the issue is not a subtask. Example: |
| environment | Type: String Description: A short description of the environment in which the issue occurred (for example, Example: |
| affected_versions | Type: String Description: JSON Array of Affected Version Names. Field is null if there are no labels. Example: |
| fix_versions | Type: String Description: JSON array of fix version names. Field is null if there are no labels. Example: |
| security_level | Type: String Description: Security level name. NOTE: This can change between data exports. Example: |
| Type: Number Description: Unique identifier of the user who archived the issue, regardless of directory. Example: Schema: Version 1 and later (requires Jira 8.19 or later) |
| Type: Date Description: UTC timezone date this issue was archived (ISO string). Example: Schema: Version 1 and later (requires Jira 8.19 or later) |
Fields schema
JIRA SOFTWARE JIRA SERVICE MANAGEMENT
issue_fields CSV file and every custom field is displayed on a separate row. To map a custom field to its corresponding issue, use the issue_id from this file and find its matching ID from the Issues file. User-generated custom fields, and fields provided by apps are generally included, as long as they are an exportable type (fields that implement ExportableCustomFieldsType).
If a custom field contains no data, it will not be exported.
| Field | Description |
|---|---|
| issue_id | Type: Number Description: ID to link to the corresponding issue in Issues data schema. Example: |
| field_id | Type: String Description: Pre-defined IDs of the Jira Software and Jira Service Management fields. Example: |
| field_name | Type: String Description: Name of the field Example: |
| field_value | Type: Number, String, JSON array Description: Value of the field Examples: |
| The following Jira Software fields relate to non-epic issues. | |
| sprint | Type: JSON Description: Sprints that the issue is currently in or has been in. All date and times are formatted as an ISO string with UTC timezone. Example: |
| epic_link_id | Type: Number Description: ID of the epic linked to this issue Example: |
| story_points | Type: Number Description: Number of story points associated with this issue Example: |
| The following Jira Software fields relate to epics | |
| epic_color | Type: String Description: Color of the epic Example: |
| epic_name | Type: String Description: Name of the epic Example: |
| epic_status | Type: String Description: Status of the epic Example: |
| The following fields relate to Jira Service Management | |
| customer_request_type | Type: String Description: Customer Request Type for a JSM Customer Request Example: |
| organizations | Type: String Description: List of organizations assigned to a given JSM Issue. Organizations are entities that admins can organize customers into. Example: ["org1", "org2"] |
| request_participants | Type: Number Description: List of users IDs assigned as request participants for a given JSM Issue. Example: Schema: Version 2 and later |
| satisfaction_comment | Type: String Description: Comment given as part of a JSM Issue Satisfaction survey Example: |
| satisfaction_rating | Type: String Description: Rating given as part of a JSM Issue Satisfaction survey Example: |
| satisfaction_scale | Type: String Description: Scale (max rating) the given satisfaction rating is based upon Example: |
| satisfaction_date | Type: Date Description: Date the Satisfaction survey was completed Example: |
Issue history schema
JIRA SOFTWARE JIRA SERVICE MANAGEMENT
issue_history CSV file. Only history after the export fromDate will be included.Use the issue_id field to join this table to the Issues and Fields tables.
| Field | Description |
|---|---|
| Type: Number Description: Unique ID of this issue. Link to the corresponding issue in the issues table. Example: |
| Type: Number Description: Identifier for the change, or group of changes that were made at the same time. Combine this with field to identify a single change. Example: |
| Type: Number Description: Unique identifier for the user who made the change. Example: |
| Type: String Description: Unique identifier of the author of the change as a unique string. Example: |
| Type: Date Description: UTC timezone date of this change (ISO string), truncated to minutes. Example: |
| Type: String Description: The name of the field that was changed. Example: assignee |
| Type: Number Description: The type of field that was changed, either jira or custom Example: |
| Type: String Description: Identifier for the value of the field before the change. Limited to 2000 characters. Example: |
| Type: String Description: Value of the field before the change, as a string. Limited to 2000 characters. Example: |
| Type: String Description: Identifier for the value of the field after the change. Limited to 2000 characters. Example: |
| Type: String Description: Value of the field after the change, as a string. Limited to 2000 characters. Example: |
| Type: String Description: Any additional information associated with the change, in JSON format. Example: |
Note that exporting issue history can take some time, and there’s a small chance that an issue may be updated after the details for that issue have been fetched. This can lead to the updated date in the issues file being earlier than the last change in the issue history file.
Note that when you create a new entity (e.g. a new issue link), the from / from_string fields will be empty and the to / to_string fields will have the value they were created with. If you delete an entity, there will be empty values in the from / from_string and the to / to_string fields. If you change any values, you should see the values on both sides.
Issue links schema
JIRA SOFTWARE JIRA SERVICE MANAGEMENT
issue_links CSV file. Field | Description |
|---|---|
| Type: Number Description: Unique ID of the source issue. Example: |
| Type: Number Description: Unique ID of the destination issue. Example: |
| Type: Number Description: Unique ID of the issue link type. Example: |
| Type: Number Description: Issue link type, such as blocks, duplicates, relates to. Example: |
Users schema
JIRA SOFTWARE JIRA SERVICE MANAGEMENT
users CSV file. Field | Description |
|---|---|
| Type: String Description: ID of the user Example: Schema: Version 2 and later |
| Type: URL Description: Base URL of the current instance. Example: Schema: Version 2 and later |
| Type: String Description: User name of the user. Example: Schema: Version 2 and later |
| Type: String Description: Full name of the user. Example: Schema: Version 2 and later |
| Type: Email Description: Email address of the user Example: Schema: Version 2 and later |
Disabled user accounts are not included in the export.
SLA Cycle data schema
JIRA SERVICE MANAGEMENT
sla_cycles CSV file. Each issue can have multiple SLAs, where each SLA cycle (Ongoing and/or Completed) is displayed on a separate row. To map an SLA to its corresponding issue, use the issue_id from this file and find its matching ID from the Issues file.| Field | Description |
|---|---|
| issue_id | Type: Number Description: ID to link to the corresponding issue in Issues data schema Example: |
| sla_id | Type: Number Description: ID of the SLA of which the SLA cycle belongs to Example: |
| sla_name | Type: String Description: Name of the SLA of which the cycle belongs to. Example: |
| cycle_type | Type: String Description: Whether current SLA cycle is Example: |
| start_time | Type: Date Description: Timestamp of when the SLA cycle started Example: |
| stop_time | Type: Date Description: Timestamp of when the SLA cycle transitioned from Example: |
| paused | Type: Boolean Description: Notes whether the SLA cycle is paused or not. Can be true, false, or empty. Only available for Example: |
| remaining_time | Type: Number Description: Represents the time (in milliseconds) remaining before the expected SLA limit is breached. Remaining times are calculated and updated every 30 minutes. Therefore, the outputted value may not represent the actual current remaining time. Example: |
| elapsed_time | Type: Number Description: Represents the time (in milliseconds) that has passed since the SLA cycle started. Example: |
| goal_duration | Type: Number Description: Represents time (in milliseconds) taken to complete the current cycle. Only available for Example: |
Approvals schema
JIRA SERVICE MANAGEMENT
approvals_<job_id>_<schema_version>_<timestamp>.csv CSV file. Field | Description |
|---|---|
| Type: Number Description: Unique ID of the issue. (foreign key) Example: Schema: Version 2 and later |
| Type: String Description: Workflow stage where approval is required. Example: Schema: Version 2 and later |
| Type: String Description: Current state of the approval. Can be Example: Schema: Version 2 and later |
| Type: Date Description: UTC timezone date that this issue required approval (ISO string) Example: Schema: Version 2 and later |
| Type: Date Description: UTC timezone date that the approval step was completed (ISO string) Example: Schema: Version 2 and later |
| Type: Boolean Description: Indicates whether the approval decision was made by the system automatically ( Example: Schema: Version 2 and later |
| Type: JSON array Description: Unique identifiers of the users who approved the request. Example: Schema: Version 2 and later |
| Type: JSON array Description: Unique identifiers of the users who rejected the request. Example: Schema: Version 2 and later |
| Type: JSON array Description: Unique identifiers of the users who were listed as approvers but who did not approve or reject the request. Example: Schema: Version 2 and later |
Canned responses schema
JIRA SERVICE MANAGEMENT
canned_responses_<job_id>_<schema_version>_<timestamp>.csv CSV file. Field | Description |
|---|---|
| Type: Number Description: Unique ID of the canned response. Example: Schema: Version 2 and later |
| Type: String Description: Unique ID of the project. Example: Schema: Version 2 and later |
| Type: Number Description: Unique ID of the service desk the canned response is associated with. Example: Schema: Version 2 and later |
| Type: String Description: Title of the canned response. Example: Schema: Version 2 and later |
| Type: Date Description: UTC timezone date that the canned response was last updated (ISO string) Example: Schema: Version 2 and later |
| Type: Number Description: Number of times the canned response has been used. Example: Schema: Version 2 and later |
| Type: Number Description: Unique ID of the user who created the canned response. Example: Schema: Version 2 and later |
| Type: Number Description: Unique ID of the user who last updated the canned response. Example: Schema: Version 2 and later |
Knowledge base schema
JIRA SERVICE MANAGEMENT
knowledge_base_<job_id>_<schema_version>_<timestamp>.csv CSV file. Field | Description |
|---|---|
| Type: Number Description: Key of the project this knowledge base is connected to. Example: Schema: Version 2 and later |
| Type: Number Description: Unique ID of the service desk the knowledge base space is associated with. Example: Schema: Version 2 and later |
| Type: Date Description: Time of the event. Example: Schema: Version 2 and later |
| Type: String Description: Key of the event, includes:
Example: Schema: Version 2 and later |
| Type: Number Description: Unique page ID of the Confluence knowledge base article. Example: Schema: Version 2 and later |
| Type: String Description: Unique identifier of the Confluence space. Example: Schema: Version 2 and later |
| Type: String Description: Page title of the Confluence knowledge base article. Example: Schema: Version 2 and later |
| Type: String Description: Unique identifier of the application link that connects your Jira application and Confluence. Example: Schema: Version 2 and later |
| Type: String Description: Unique key for the Jira issue that the knowledge base article was shared in. Example: Schema: Version 2 and later |