Assets for Jira - How to validate attributes with regular expressions
Platform notice: Server and Data Center only. This article only applies to Atlassian products on the Server and Data Center platforms.
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Purpose
To validate attribute values when an Asset object is being created either manually or via import, this can be done by using regular expressions which can be configured on the attribute level in the object type view or the object type mapping for import.
This KB contains 4 examples of using regular expressions in different scenarios.
Environment
Jira Service Management Server/Data Center on any version from 5.0.0
Solution
For this example, we use a simple CSV file below. Importing this file should create 2 objects namely Penguin and Koala, each with a 5-digit Employee ID which is the last 5 digits in the CSV file.
Name,Employee ID
Penguin,00012345
Koala,00034567In the object type, we have an Integer type attribute called Employee ID in the object type as shown below.

In the import configuration, we map the data locator and Insight attributes as shown below. More explanation about attribute mapping can be found in Create attribute mapping.

By clicking on the cog icon available on the same row of the mapped attribute, you will be able to configure the regular expression. To validate Employee ID from the source (CSV file) and get the last 5 digits of each value, we use (.{5}$) as the regular expression.

Perform a sync and 2 objects will be created from the example CSV file. As expected, only the last 5 digits of each Employee ID value are retrieved.

If you would like to troubleshoot or to see how the regular expression is applied on value, you may refer to the <(Jira_home or Jira_shared_home)>/log/insight_import.log. This is the log written during the import of the example CSV file.
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-2] | Regexp for Employee ID will be applied on value: 00012345 Match on regexp: (.{5}$)
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-2] | Regexp for Employee ID after match [12345]
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-2] | Regexp for Employee ID will be applied on value: 00012345 Match on regexp: (.{5}$)
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-3] | Regexp for Employee ID will be applied on value: 00034567 Match on regexp: (.{5}$)
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-2] | Regexp for Employee ID after match [12345]
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-3] | Regexp for Employee ID after match [34567]
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-3] | Regexp for Employee ID will be applied on value: 00034567 Match on regexp: (.{5}$)
2021-10-26 10:54:08,162 [insight-InsightImportThreadGroup-worker-thread-3] | Regexp for Employee ID after match [34567]For this example, we have IP addresses from the CSV file below and we would like to have the Network Address (the first 3 octets) to be the Name and the label of the created objects.
IP4,Device ID
10.0.2.15,12
192.168.56.101,17The object type configuration looks like this.

The object type mapping is as shown below.
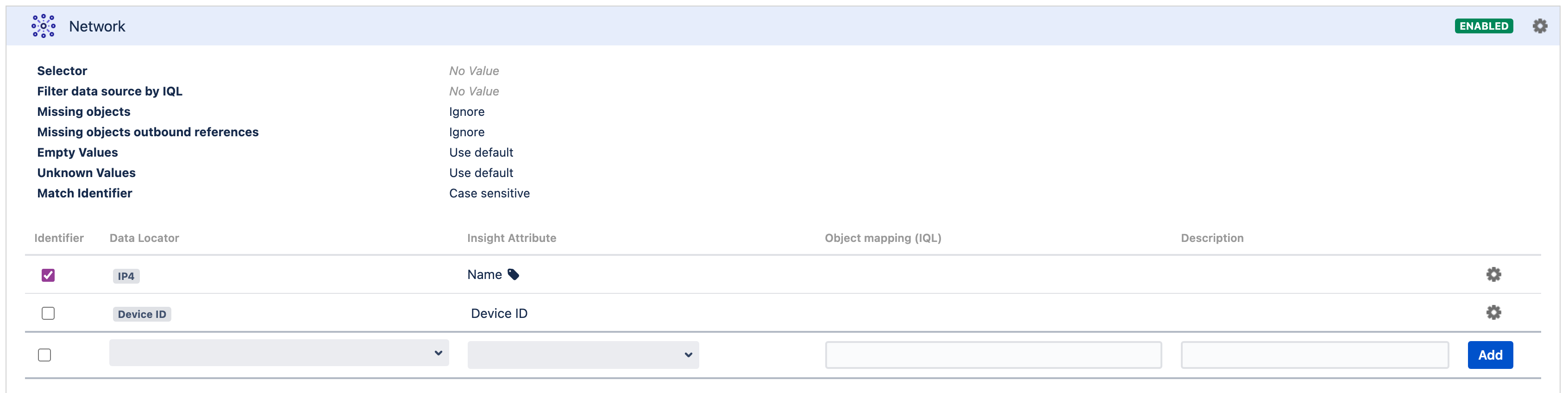
To get just the first 3 octets from each IP address, we use (\d{1,3}.\d{1,3}.\d{1,3}) as the regular expression.

Perform a sync and 2 objects will be created from the example CSV file. As expected, 2 objects with Name that is the first 3 octets of the IP address are created.

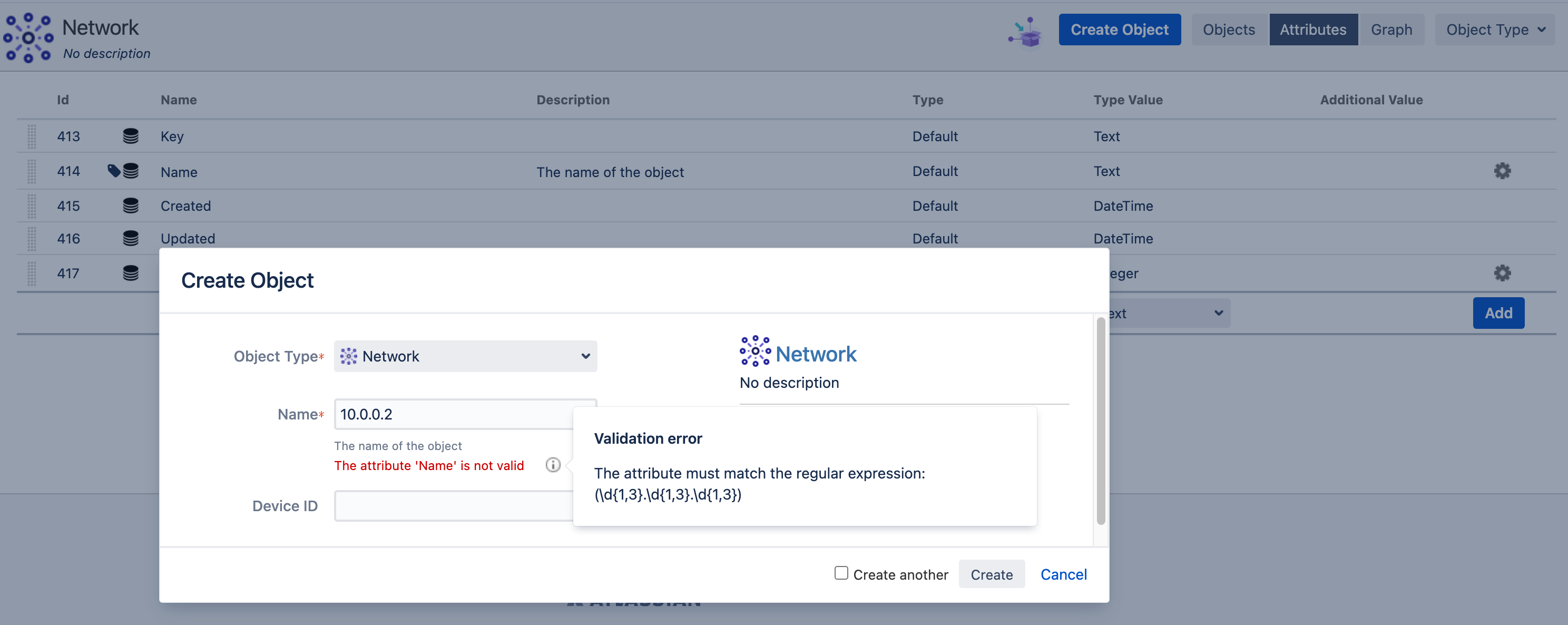
The same regular expression can also be used on the object type level, so that the object name will be validated too when an object is being created manually.

Here's an example to show how the value is getting validated when an object is being created manually.
For this example, we use a simple CSV file below. Importing this file should create two objects namely AAA0001 and AZZ0001. We filter the objects with a "S" at the third position of a string. The Regex will capture only strings (Names) where the 3rd character is neither s or S.
Name
AZS0001
AZZ0001
AAA0001
Since Name is set to be the Label of objects (by default) - no object will be created for AZS0001
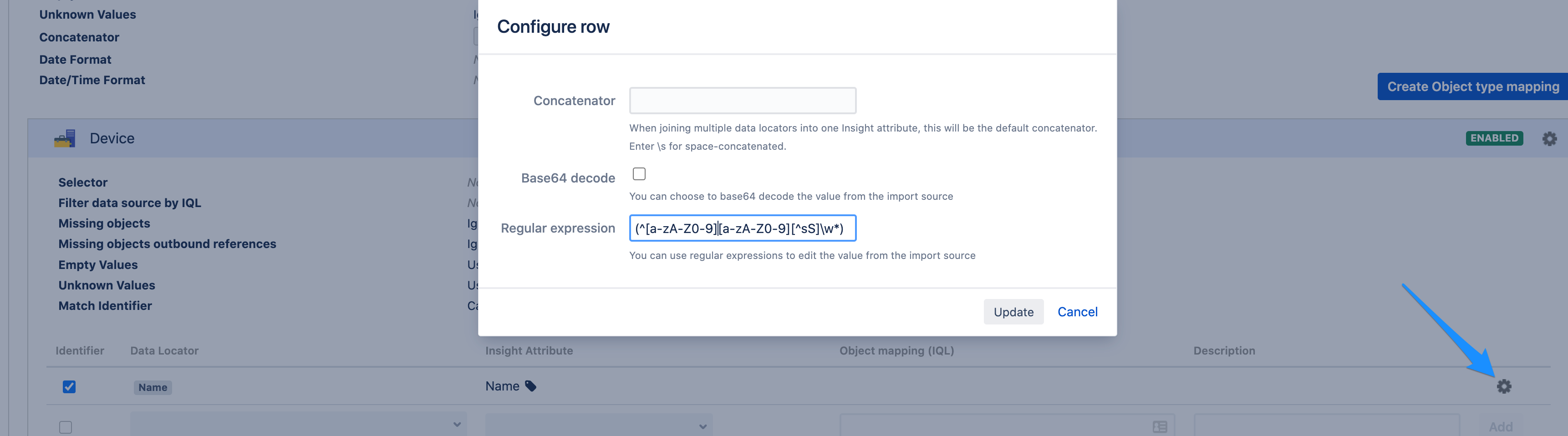
In the import configuration, we map the data locator and Insight attributes as shown below. More explanation about attribute mapping can be found in Create attribute mapping. 
By clicking on the cog icon available on the same row of the mapped attribute, you will be able to configure the regular expression. To capture only strings (Names) where the 3rd character is neither s or S, we use (^[a-zA-Z0-9][a-zA-Z0-9][^sS]\w*) as the regular expression.
Perform a sync and 2 objects will be created from the example CSV file.

The same regular expression can also be used on the object type level, so that the object name will be validated too when an object is being created manually.
Note: Using the REGEX in the Attribute configuration but not on the Import Attribute Map - will also result the objects not created, but this will also add an error entry to the Import Log, <(Jira_home or Jira_shared_home)>/log/insight_import.log.
The Process Result will show an error. Using the REGEX in both places will complete the import successfully (no errors) and will prevent Users creating objects manually, with an s/S as 3rd character.
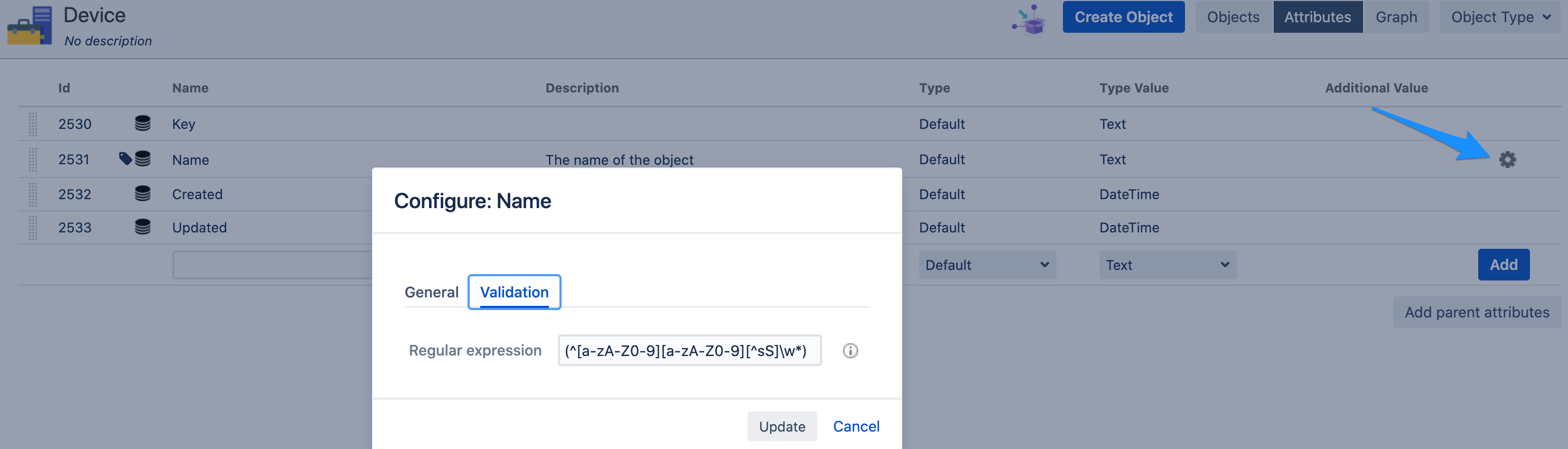
Here's an example to show how the value is getting validated when an object is being created manually.

For this example, we use a simple CSV file below, it can be use for any Assets Import, though. Importing this file should create two objects namely AAA0001 and AZZ0001. The Regex will exclude only the date Sat Jan 01 00:59:59 CET 10000.
Name, Expiration date
AAA0001, 16/04/24 10:01
AZZ0001, Sat Jan 01 00:59:59 CET 10000The object type configuration looks like this:

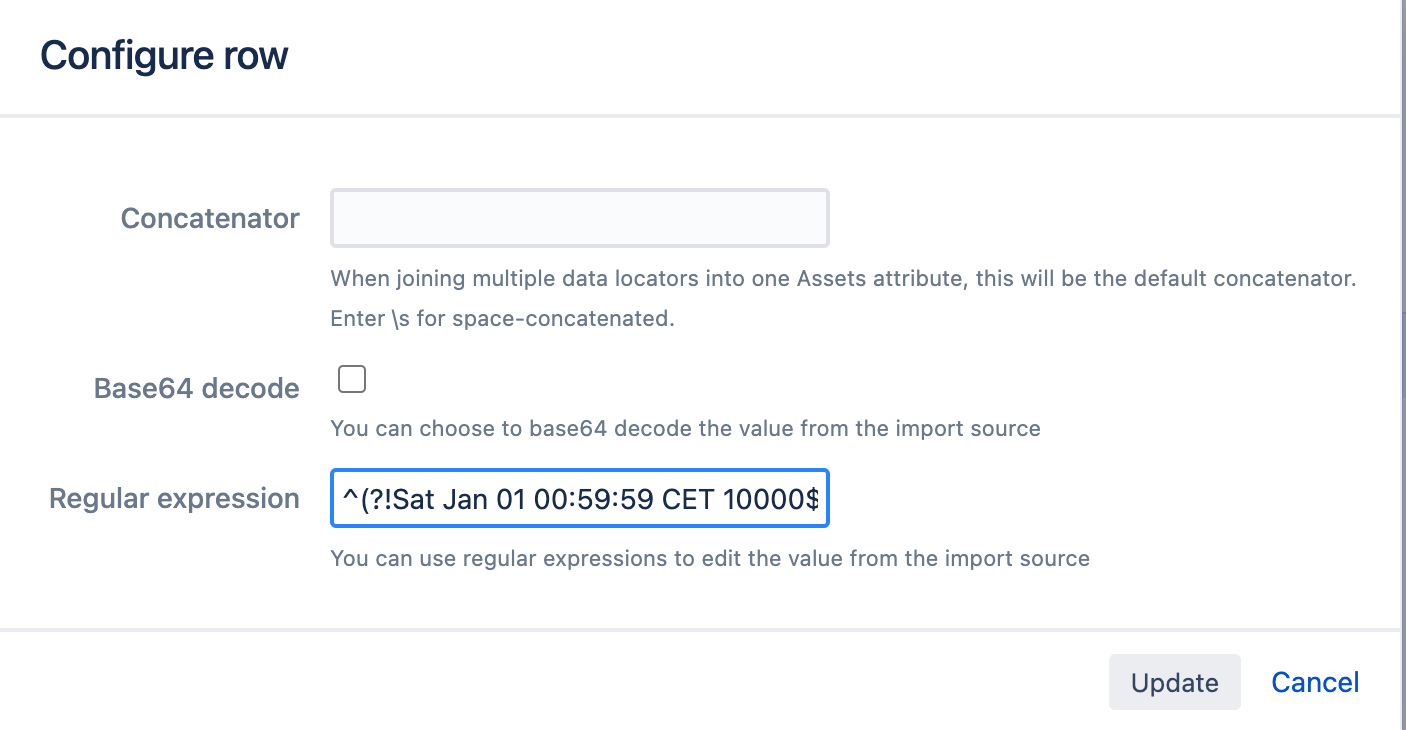
In the import configuration, we map the data locator and Assets attributes as shown below. More information about attribute mapping can be found in Create attribute mapping.

By clicking on the cog icon available on the same row of the mapped attribute, you will be able to configure the regular expression. To exclude only the date Sat Jan 01 00:59:59 CET 10000. we use (^(?!Sat Jan 01 00:59:59 CET 10000$).*$) as the regular expression.
After performing a sync, two objects will be created from the example CSV file. As a result of the regular expression, the 'Expiration date' attribute will be left empty.