How to update the Confluence attribute type values of Assets objects on Jira Service Management Data Center post Confluence Data Center migration
Platform Notice: Data Center - This article applies to Atlassian products on the Data Center platform.
Note that this knowledge base article was created for the Data Center version of the product. Data Center knowledge base articles for non-Data Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
In Assets, there's a Confluence attribute type that enables a link from an Assets object to a Confluence page. If the Confluence page is migrated from one Data Center instance to another, a manual update on this attribute is needed to keep the validity of the link to the Confluence page. This article explains how to perform a bulk update on the UI via CSV import of Assets.
Environment
Verified on Jira Service Management Data Center 5.12.x
Solution
The solution consists of a few parts.
Get the page information from both the source and target Confluence database
The SQL query below returns the page ID, page title, and space key. Run this in the source Confluence instance as well as in the target Confluence instance. The combination of the results will be used for the page ID replacement later.
select c.contentid, c.title, s.spacekey
from content c
join spaces s on s.spaceid = c.spaceid
where contenttype = 'PAGE'
and c.content_status = 'current'
and prevver is NULLExample results:
| From the source Confluence instance | From the new Confluence instance |
|---|---|
| |
Export objects to CSV
The second part is to get the CSV file of the objects' Confluence type attributes to be updated.
- Go to the schema and the object type to perform the search (if required) and export from the object type view. This export gives an option to change the format of the metadata.
- Choose "Data consistent" as the export format. The default is "User friendly" which gives us the Confluence page name instead of page ID.
Here's an example row of the exported file. The last column is the Confluence type object type attribute and it has 360454 as the value. In this example, 360454 is the page ID of the Confluence page for the object with key ATL-1234.
Internal Object ID,Key,Name,Created,Updated,Status,Linked Confluence Page 7783,ATL-1234,Jira,2024-07-30T09:43:56.231Z,2024-07-30T09:55:06.630Z,Active,360454
Replace the old page IDs with the new page IDs in the CSV file
The third part is to update the page IDs in the CSV file.
From the example above, 5485293 is the new page ID. We shall update the CSV file with the new page ID.
Internal Object ID,Key,Name,Created,Updated,Status,Linked Confluence Page
7783,ATL-1234,Jira,2024-07-30T09:43:56.231Z,2024-07-30T09:55:06.630Z,Active,5485293Import the updated CSV file to update the Confluence attribute type values
The last part is to import the CSV file into the Assets schema to update the objects. We will use CSV import for this.
- Create the import configuration for CSV import in the desired Assets schema to import from the updated CSV file above.
- Create the object type mapping accordingly.
- Simplify the attribute mapping by setting only the identifier and the Confluence type object type attribute. For example, the following has both the object name and key as the identifier to ensure that the right object is being identified, and only the Linked Confluence Page attribute shall be updated.
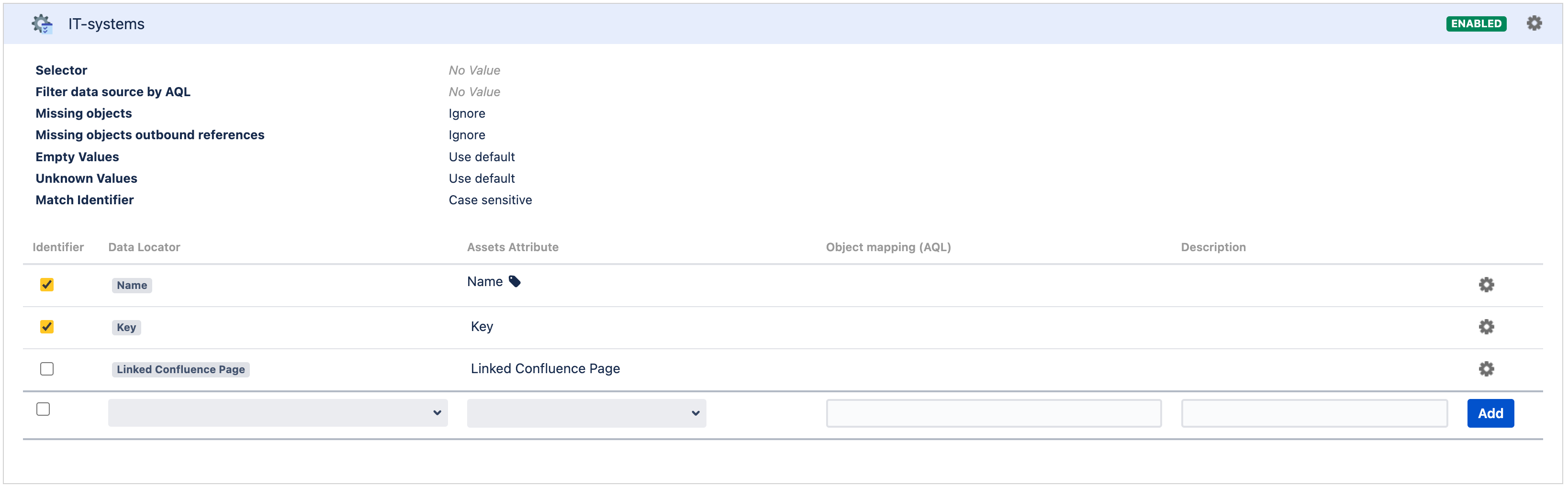
- Run the import and verify if the import successfully updates the objects with the new, valid Confluence pages.