Index startup procedure in Jira 9.4 and later
Platform Notice: Data Center - This article applies to Atlassian products on the Data Center platform.
Note that this knowledge base article was created for the Data Center version of the product. Data Center knowledge base articles for non-Data Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
When a Jira node starts, it needs to acquire a valid index to respond to JQL searches and for other index-related features to work (for example, reports). This page explains how the process behaves in detail.
On this page:
- General concept
- Local index rebuild
- Fetching index snapshot
- Final fallback – full reindex
- Index snapshot after startup
- Index snapshot service
- Synchronization of index acquisition
- Index consistency after Jira startup
- Full reindex upgrade task
- Configurability
- Monitoring
- In-depth chart
- Changelog
- What else to read?
General concept
The following chart shows the course of the index startup procedure every time a new node is started.
Until Jira 11:

From Jira 11 one new check is added before starting Full Reindex.
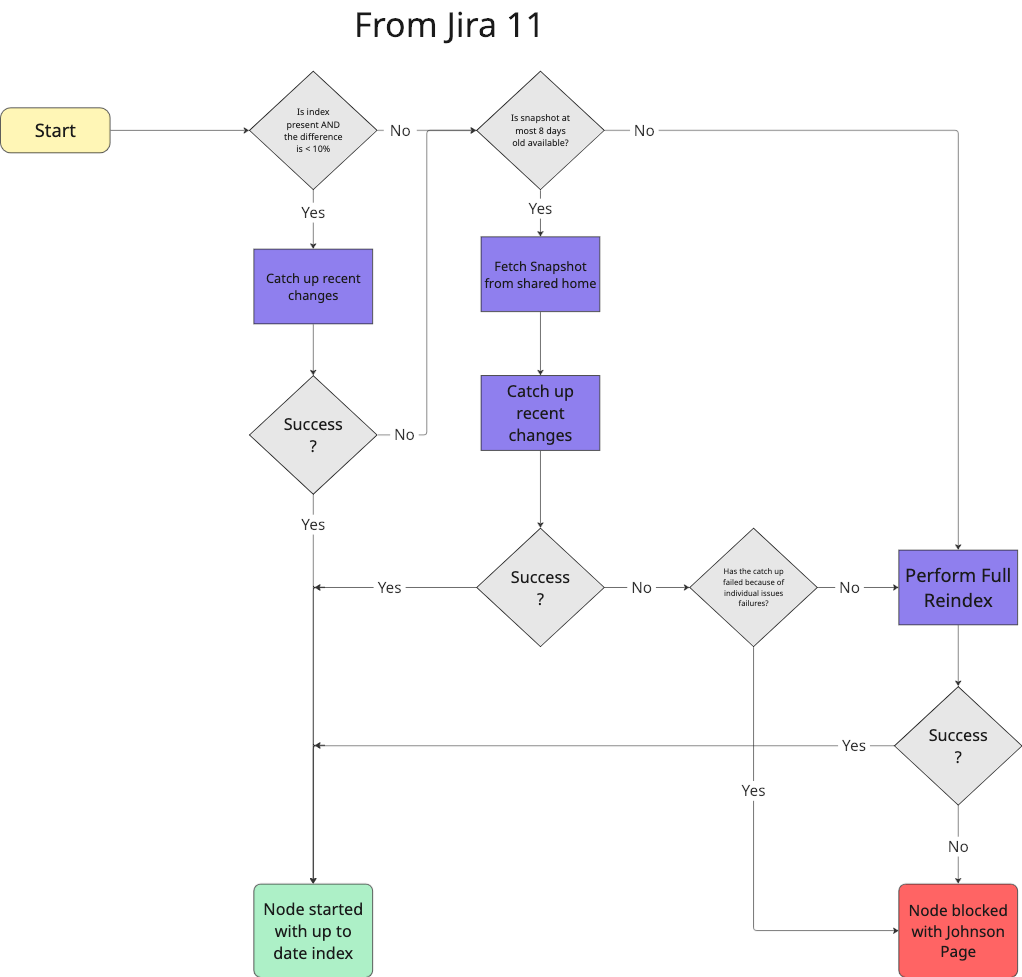
There are two possible states of the index on a starting node:
Case 1 – The node was previously in the cluster and it has an index in its local home.
Case 2 – The node starts with the fresh local home and there is no index in the local home.
In Case 1, the index will get refreshed by catching up with recent changes if possible.
In Case 2, the index needs to be restored from the index snapshot in the shared home. A node will fetch it from the shared home, unpack it to local directories, and catch up with the changes that aren’t present in the snapshot.
If the local index can’t be rebuilt or an error occurs, the process will fall back to acquiring the index through the index snapshot. If the index can’t be acquired through the snapshot, the node will acquire an index by performing a full foreground reindex.
Local index rebuild
If the local index exists, Jira will check how far behind the database it's lagging:
If the difference is less than the value of
-Dcom.atlassian.jira.index.consistency.tolerance.percentage, Jira will catch up on the missing changes locally. For this operation to be as fast as possible, it will be performed in multiple threads holding an exclusive index write lock.If it’s greater than the value of
-Dcom.atlassian.jira.index.consistency.tolerance.percentage, Jira will fall back to acquiring the index by fetching the index snapshot.
The default value of -Dcom.atlassian.jira.index.consistency.tolerance.percentage is 10.
Fetching index snapshot
If a fresh snapshot can be found in the shared home, Jira loads it and catches up with the most recent changes that aren’t present in the snapshot. For the catch-up to be as fast as possible, it happens in multiple threads and holds an index write lock.
By default, the maximum accepted age of a snapshot is eight days and it can be configured with the system property -Dcom.atlassian.jira.startup.max.age.of.usable.index.snapshot.in.hours.
Final fallback – full reindex
If the previous steps fail or can’t be achieved, Jira triggers a full foreground reindex. After the full reindex completes, all other nodes will receive the new version of the index through the propagation of the index snapshot. For more details, see the section “Special case index distribution: full foreground and background reindexes” in How indexing works in Jira.
Only one node at a time can perform an index startup procedure which ensures that two consequently starting nodes won’t need to perform the full reindex.
If for any reason the full reindex fails, the index startup procedure will detect that index couldn’t be acquired. In this case, Jira will be blocked from serving the traffic.
Index snapshot after startup
No matter how the index has been acquired, the starting node will ensure that the index snapshot exists for the needs of nodes starting in the future. A starting node will check if a fresh enough index snapshot exists (at most 8 days old), and will create one if it doesn’t.
Index snapshot service
To make sure that during the startup every node has an available index snapshot, the periodical index snapshot service is enabled in the cluster by default. It's set to take a snapshot of indexes every day at 2 am.
To change this setting, go to Administration > System. In the left-side panel, go to Advanced and select Indexing. Learn more about the configuration for the index recovery schedule
Synchronization of index acquisition
To ensure the reliability of the index procedure, it’s synchronized across the cluster.
Each node has to acquire the com.atlassian.jira.start.index.lock cluster lock for the whole duration of the index startup procedure. If the lock isn’t taken by any other node, Jira will claim it and hold it until the index startup procedure completes. Otherwise, it will wait for the current holder of the lock to finish the startup procedure and then, acquire the lock.
In case you kill the node holding the lock, it'll take five minutes by default for other nodes to consider the lock expired.
Index consistency after Jira startup
The index is guaranteed to be consistent, complete, and ready to use immediately after the start. You don’t need to perform any additional completeness checks.
Full reindex upgrade task
Major indexing changes that happen during major Jira version upgrades (for example, from version 8.x to 9.x) require the full reindex after the upgrade. Full reindex is usually enforced by an upgrade task.
If the index startup procedure detects that a full reindex upgrade task is scheduled, it won’t perform any steps to acquire the index. The index startup procedure will exit, although it won’t block Jira with the Johnson error page.
Configurability
Use the following system properties to customize the index startup flow:
-Dcom.atlassian.jira.index.consistency.tolerance.percentage
Default value:10
When the percentage difference is bigger than the set value Jira won’t attempt to rebuild the local index.-Dcom.atlassian.jira.startup.rebuild.local.index
Default value:true
When set tofalse, Jira won’t attempt to rebuild the local index, no matter how small the difference is.-Dcom.atlassian.jira.startup.max.age.of.usable.index.snapshot.in.hours
Default value:192 = 8 days
Defines an age of a snapshot that is considered fresh enough to be used during the index startup procedure.-Dcom.atlassian.jira.startup.pick.indexsnapshot.from.shared
Default value:true
When set tofalse, Jira won’t attempt to acquire an index using a snapshot even if fresh enough index snapshots exist.-Dcom.atlassian.jira.startup.allow.full.reindex
Default value:true
When set tofalse, Jira won’t attempt to acquire an index by performing a full reindex. Use this property with caution as there is no further fallback.-Dcom.atlassian.jira.startup.ensure.snapshot.exist
Default value:true
When set tofalse, Jira won’t attempt to ensure that the index snapshot exists in the shared home directory after acquiring the index.
Monitoring
The progress of the index startup procedure is logged to the standard atlassian-jira.log.
To search for index startup-related logs, use the following expression:
grep 'DefaultClusterManager\|DefaultIndexRecoveryManager\|[INDEX_START]\|[INDEX_FETCHER]\|DefaultIndexFetcher\|[INDEX-FIXER]' atlassian-jira.logLearn more about logs for different stages of the index startup procedure
In-depth chart
The following chart shows the detailed course of the index startup procedure every time a new node is started. Compared to the general concept chart, this one is expanded with a corner case and more detail.


Changelog
The following table describes the changes implemented in the following versions.
| Version | Update |
|---|---|
Jira 9.4.1 | The default index freshness threshold increased from 25 hours to 192 hours. |
Jira 10.0.0 | The catch up process changed to be parallel also for comments and worklogs. |
Jira 9.12.18 | The catch up process changed to be parallel also for comments and worklogs. (Backport) |
Jira 11.0.0 | If there are some individual issues failures during index catchup after snapshot recovery the full reindex step will be skipped. |