The CSV export from the Jira issue search page generates an empty file
Platform notice: Server and Data Center only. This article only applies to Atlassian products on the Server and Data Center platforms.
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
The CSV export from the Jira issue search page results in an empty file when the number of results from the search is high (for example, several thousand issues).
The problem is more likely to occur when choosing the option Export > CSV (All fields), as shown in the screenshot below:
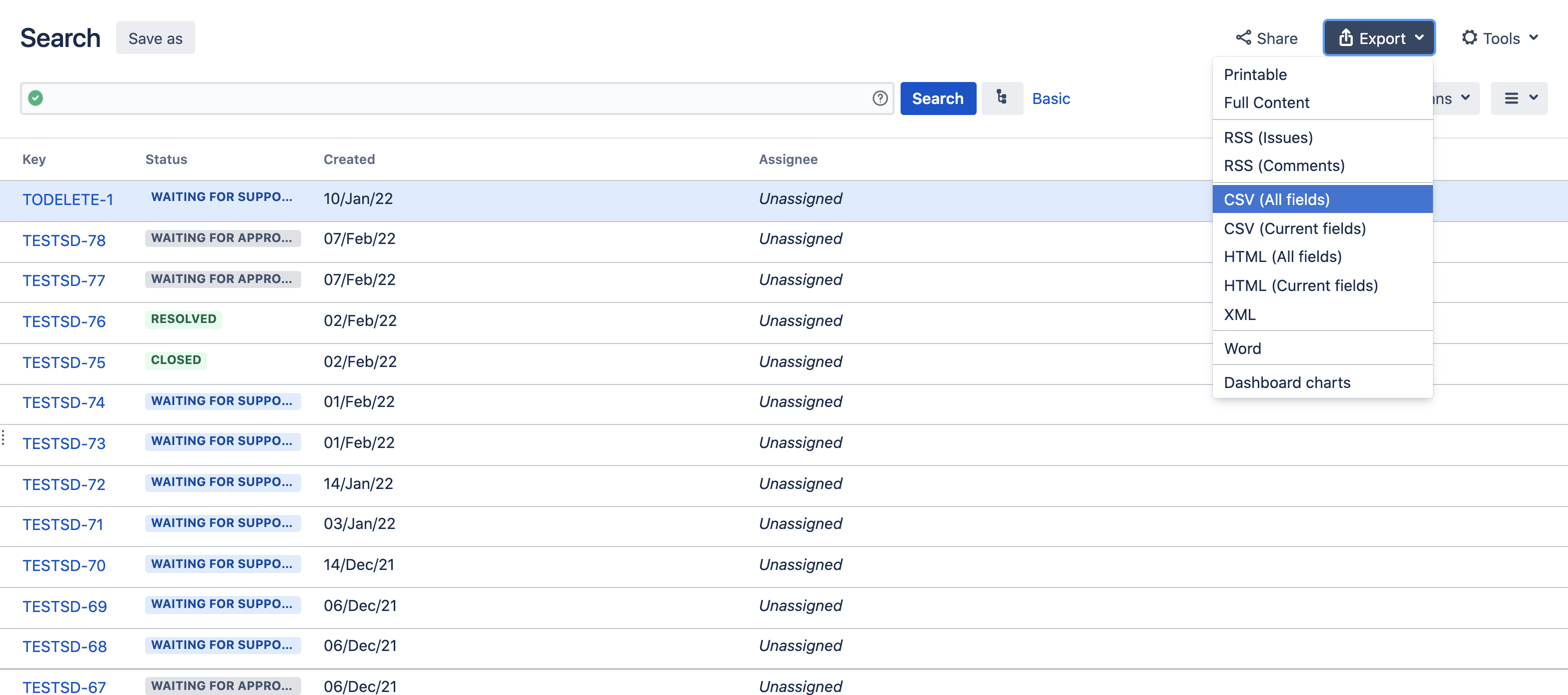
Environment
Any Jira Server/Data Center version 7.x and higher.
Diagnosis
- Usually the following symptom is observed: the CSV export takes a long time (at least 30 seconds) to run and eventually completes. However, when opening the CSV file, it is completely empty
When checking the Tomcat Access logs located in the directory <JIRA_INSTALLATION_FOLDER>/logs, we can see that the CSV export actually completed on the Jira application side, but took a very long time to complete. In the example below, we can see that it took 658058ms (>10min) to complete:
XX.XXX.XX.XX 860x2358317x1 someuser [24/Jan/2022:14:31:43 +0100] "GET /jira/sr/jira.issueviews:searchrequest-csv-all-fields/XXXXX/SearchRequest-XXXXX.csv?delimiter=; HTTP/2.0" 200 8184 658058 "<JIRA_BASE_URL>/jira/browse/ABC-123?filter=XXXXX" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36" "3mfyv2"When checking the catalina.out file located in the directory <JIRA_INSTALLATION_FOLDER>/logs, we can see that the request handling the CSV export seems to be "stuck". It is actually detected as "stuck" by Tomcat, since it is taking more than 2 minutes to complete:
24-Jan-2022 14:22:53.700 WARNING [ContainerBackgroundProcessor[StandardEngine[Catalina]]] org.apache.catalina.valves.StuckThreadDetectionValve.notifyStuckThreadDetected Thread [ajp-nio-0.0.0.0-18009-exec-1439 url: /jira/sr/jira.issueviews:searchrequest-csv-all-fields/XXXXX/SearchRequest-XXXXX.csv; user: someuser] (id=[287982]) has been active for [128,532] milliseconds (since [1/24/22 2:20 PM]) to serve the same request for [<JIRA_BASE_URL>/jira/sr/jira.issueviews:searchrequest-csv-all-fields/XXXXX/SearchRequest-XXXXX.csv?delimiter=;] and may be stuck (configured threshold for this StuckThreadDetectionValve is [120] seconds). There is/are [1] thread(s) in total that are monitored by this Valve and may be stuck. java.lang.Throwable at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:171) at java.net.SocketInputStream.read(SocketInputStream.java:141) at sun.security.ssl.InputRecord.readFully(InputRecord.java:465) at sun.security.ssl.InputRecord.read(InputRecord.java:503) at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:975) at sun.security.ssl.SSLSocketImpl.readDataRecord(SSLSocketImpl.java:933) at sun.security.ssl.AppInputStream.read(AppInputStream.java:105) at java.io.FilterInputStream.read(FilterInputStream.java:133) at com.mysql.cj.protocol.FullReadInputStream.readFully(FullReadInputStream.java:64) ... at com.atlassian.jira.issue.export.customfield.DefaultCsvIssueExporter.getFieldExportRepresentationForCustomField(DefaultCsvIssueExporter.java:148) at com.atlassian.jira.issue.export.customfield.DefaultCsvIssueExporter.getFieldExportRepresentation(DefaultCsvIssueExporter.java:123) at com.atlassian.jira.issue.export.customfield.DefaultCsvIssueExporter.getLayout(DefaultCsvIssueExporter.java:98)When taking thread dumps during the CSV export, we can see a long running thread related to the CSV export, and which involves a class coming from the 3rd party add-on Git Integration for Jira developed by BigBrassBand (notice the class com.bigbrassband.jira.git.services involved in the stack trace from both examples):
Example 1
"ajp-nio-0.0.0.0-18009-exec-1605 url: /jira/sr/jira.issueviews:searchrequest-csv-all-fields/XXXXX/SearchRequest-XXXXX.csv url:/jira/sr/jira.i...hRequest-47406.csv username:someuser" #322853 daemon prio=5 os_prio=0 tid=0x00007fa99c005000 nid=0x1e5186 runnable [0x00007fa92f40f000] java.lang.Thread.State: RUNNABLE at org.apache.lucene.codecs.blocktree.SegmentTermsEnumFrame.<init>(SegmentTermsEnumFrame.java:47) at org.apache.lucene.codecs.blocktree.SegmentTermsEnum.getFrame(SegmentTermsEnum.java:215) at org.apache.lucene.codecs.blocktree.SegmentTermsEnum.pushFrame(SegmentTermsEnum.java:241) at org.apache.lucene.codecs.blocktree.SegmentTermsEnum.seekExact(SegmentTermsEnum.java:471) at org.apache.lucene.search.TermQuery$TermWeight.getTermsEnum(TermQuery.java:127) at org.apache.lucene.search.TermQuery$TermWeight.scorer(TermQuery.java:90) at org.apache.lucene.search.Weight.scorerSupplier(Weight.java:113) at org.apache.lucene.search.LRUQueryCache$CachingWrapperWeight.scorerSupplier(LRUQueryCache.java:720) at org.apache.lucene.search.BooleanWeight.scorerSupplier(BooleanWeight.java:329) at org.apache.lucene.search.BooleanWeight.scorer(BooleanWeight.java:295) at org.apache.lucene.search.Weight.bulkScorer(Weight.java:147) at org.apache.lucene.search.BooleanWeight.bulkScorer(BooleanWeight.java:289) at org.apache.lucene.search.LRUQueryCache$CachingWrapperWeight.bulkScorer(LRUQueryCache.java:795) at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:657) at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:462) at com.bigbrassband.jira.git.utils.lucene.LuceneHelper.collectDocIds(LuceneHelper.java:57) at com.bigbrassband.jira.git.services.indexer.revisions.IndexManagerImpl.collectAnswerForQuery(IndexManagerImpl.java:216) at com.bigbrassband.jira.git.services.indexer.revisions.RevisionsIndexManagerImpl.getRevisionInfoByIssues(RevisionsIndexManagerImpl.java:585) at com.bigbrassband.jira.git.services.indexer.revisions.RevisionsIndexManagerImpl.getLogEntriesByIssuesNoCommit(RevisionsIndexManagerImpl.java:445) at com.xiplink.jira.git.jql.GitBranchCF$BranchLoader.load(GitBranchCF.java:60) at com.xiplink.jira.git.jql.GitBranchCF$BranchLoader.load(GitBranchCF.java:53) at com.atlassian.cache.memory.MemoryCacheManager$2.load(MemoryCacheManager.java:192)Example 2
"ajp-nio-0.0.0.0-18009-exec-1605 url: /jira/sr/jira.issueviews:searchrequest-csv-all-fields/XXXXX/SearchRequest-XXXXX.csv url:/jira/sr/jira.i...hRequest-XXXXX.csv username:someuser" #322853 daemon prio=5 os_prio=0 tid=0x00007fa99c005000 nid=0x1e5186 runnable [0x00007fa92f410000] java.lang.Thread.State: RUNNABLE at org.apache.lucene.codecs.blocktree.SegmentTermsEnumFrame.scanToTermNonLeaf(SegmentTermsEnumFrame.java:718) at org.apache.lucene.codecs.blocktree.SegmentTermsEnumFrame.scanToTerm(SegmentTermsEnumFrame.java:481) at org.apache.lucene.codecs.blocktree.SegmentTermsEnum.seekExact(SegmentTermsEnum.java:509) at org.apache.lucene.search.TermQuery$TermWeight.getTermsEnum(TermQuery.java:127) at org.apache.lucene.search.TermQuery$TermWeight.scorer(TermQuery.java:90) at org.apache.lucene.search.Weight.scorerSupplier(Weight.java:113) at org.apache.lucene.search.LRUQueryCache$CachingWrapperWeight.scorerSupplier(LRUQueryCache.java:720) at org.apache.lucene.search.BooleanWeight.scorerSupplier(BooleanWeight.java:329) at org.apache.lucene.search.BooleanWeight.scorer(BooleanWeight.java:295) at org.apache.lucene.search.Weight.bulkScorer(Weight.java:147) at org.apache.lucene.search.BooleanWeight.bulkScorer(BooleanWeight.java:289) at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:657) at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:462) at com.bigbrassband.jira.git.services.indexer.revisions.IndexManagerImpl.collectAnswerForQuery(IndexManagerImpl.java:192) at com.bigbrassband.jira.git.services.indexer.revisions.IndexManagerImpl.collectAnswerForQuery(IndexManagerImpl.java:181) at com.bigbrassband.jira.git.services.indexer.revisions.IndexManagerImpl.hasAnswerForQuery(IndexManagerImpl.java:172) at com.bigbrassband.jira.git.services.indexer.revisions.RevisionsIndexManagerImpl.getRevisionInfoByIssues(RevisionsIndexManagerImpl.java:583) at com.bigbrassband.jira.git.services.indexer.revisions.RevisionsIndexManagerImpl.hasLogEntriesByIssues(RevisionsIndexManagerImpl.java:610) at com.bigbrassband.jira.git.services.indexer.revisions.GitPluginIndexManagerImpl.hasLogEntriesByIssues(GitPluginIndexManagerImpl.java:197) at com.bigbrassband.jira.git.services.indexer.revisions.GitPluginIndexManagerImpl.hasLogEntriesByIssue(GitPluginIndexManagerImpl.java:192) at com.xiplink.jira.git.jql.GitCommitsReferencedCF.getValueFromIssue(GitCommitsReferencedCF.java:55) at com.xiplink.jira.git.jql.GitCommitsReferencedCF.getValueFromIssue(GitCommitsReferencedCF.java:17) at com.atlassian.jira.issue.export.customfield.DefaultCsvIssueExporter.getFieldExportRepresentationForCustomField(DefaultCsvIssueExporter.java:148)
- When disabling the add-on Git Integration for Jira from the page ⚙ > Manage Apps > Manage Apps, the CSV export completes quickly and the CSV file is not empty
Cause
The slowness of the CSV export and the empty CSV file is coming from fields coming from the add-on Git Integration for Jira:
- when trying to export an issue search as a CSV file with all the fields, the Jira application tries to extract the values from all the fields which are available for each of the thousands of issues returned by the JQL search
- some of these fields are coming from the 3rd party add-on Git Integration for Jira
- this add-on has its own way to retrieve the value of its own fields, which requires to use the indexes that this add-on manages as per Git Integration for Jira FAQ - Reindexing
- as a result, during the CSV export process, for each Jira issue the add-on tries to perform some indexing operation which is very heavy and requires a lot of CPU
- the whole CSV export ends up taking a very long time to complete
- eventually, the CSV export might be canceled either by the browser (depending on the browser timeout value) or the reverse proxy/load balancer that the Jira application is running behind, and an empty CSV file will be generated
Solution
Temporary solutions:
- Disable the add-on Git Integration for Jira from the page ⚙ > Manage Apps > Manage Apps, whenever you need to export an issue search using the option CSV (All fields)
- Alternatively, modify the columns showing in the issue search page so that no fields coming from the add-on Git Integration for Jira are selected, and then choose the option CSV (Current fields) to do the export
Long term solution:
- Reach out to the add-on support team using their support portal for further assistance, since this add-on is not supported by Atlassian