Service limits
Ensuring your Jira Server instance is running smoothly is the responsibility of any good Jira admin. With our service limits you're covered and 99.9% of you will never experience these limits, they only apply to truly exceptional cases.
| Limit | Server | Example of how to breach this limit |
|---|---|---|
| Components per rule | 65 | More than 65 conditions, branches and actions for one rule |
| New sub-tasks per action | 100 | Triggers the creation of over 100 sub-tasks |
| Issues searched | 1000* | A scheduled JQL search that isn't streamlined enough and returns more than 1000 issues. * In server, this number is derived from the jira.search.views.default.max configuration property. This can be configured and limits the number of issues returned per search globally in Jira. |
| Concurrent scheduled rule executions | 1 | A scheduled rule that takes longer than 5 minutes to execute, scheduled every 5 mins. Only allow a single concurrent execution of this rule is allowed. |
| Items queued by rule | 25000 | See the section below on queued items limit for more information. |
| Items queued globally | 100000 | Similar to queued items per rule but applies to rules in progress across your Jira instance globally. |
| Daily processing time | 120 min | A rule executes every 5 mins and each execution takes longer than 5 seconds (in cloud). This could be the case if your rule talks to slow external systems for example. |
| Hourly processing time | 100 min | Configure several rules that listen for issue events and carry out a bulk operation that executes these rules. This limit only triggers if there are more than 2000 rule executions per hour in cloud and more than 5000 rule executions per hour in server) |
| Loop detection | 10 | This controls how many times a rule can trigger itself (or other rules) in quick succession before execution is stopped and marked as a LOOP. |
If you're running the latest version of Automation for Jira Server, you can use the Service limit breached trigger to setup an automation rule to send out notifications when you are about to breach one of the Processing time limits above.
Breaching limits
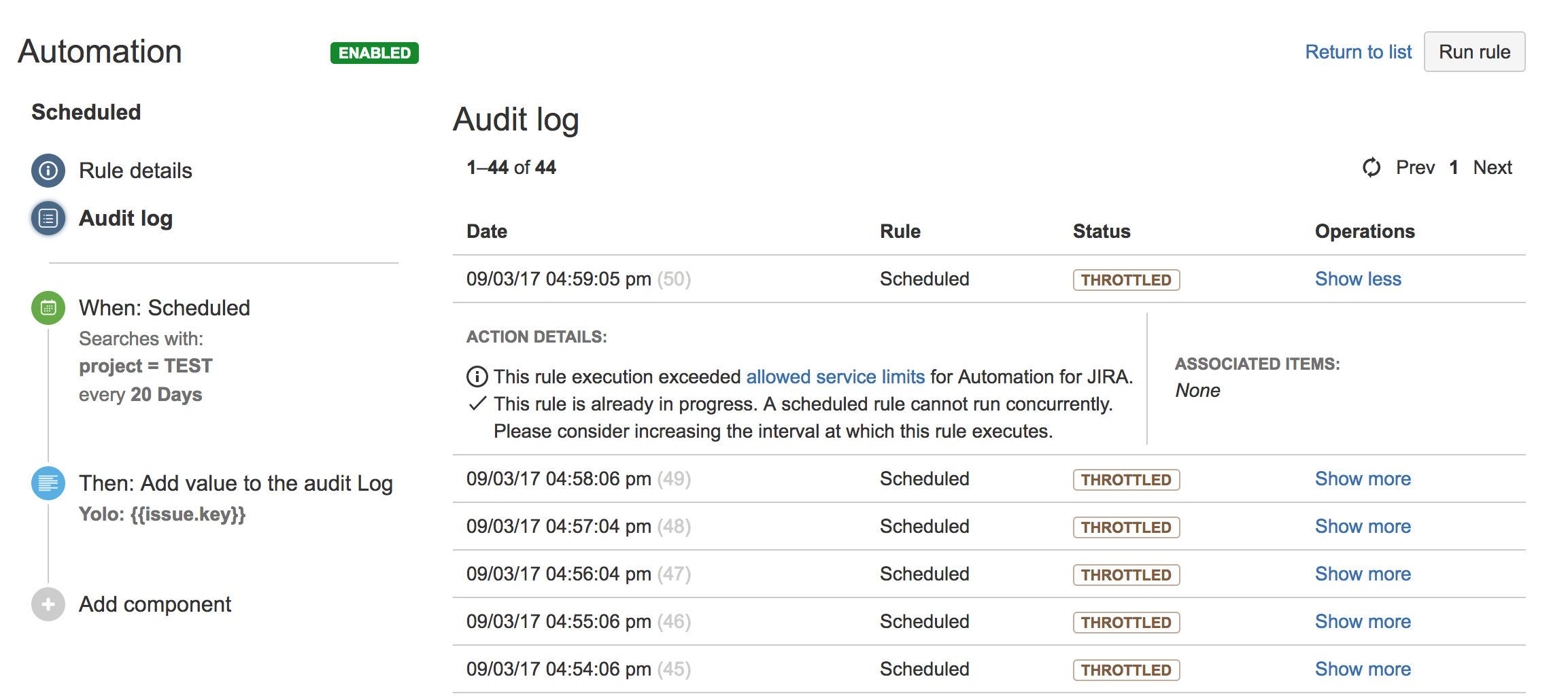
If you see errors like these in your audit log, you're hitting limits:
- The audit item status is THROTTLED
- The audit item contains one of:
- This automation rule spent more than the allowed total time processing in the last day. Maximum allowed processing time over a day is (in minutes):
- Automation for Jira has exceeded the allowed maximum number of rule executions in the last hour
- A JQL search in this automation rule has exceeded the allowed maximum number of issues to retrieve per search. Only the first issues up to the following limit where processed:
When a rule breaches its limit, the audit log contains more details:
Based on the details provided in the audit log you can take several steps to ensure your rules fall below the acceptable limits, such as:
- Reduce the interval at which a scheduled rule executes. For example, only execute a rule every hour instead of every 5 minutes.
- Restrict your JQL query to only search for the issues you care about. E.g. check that the updated time of the issue is within a certain range (like updated > -1w to include only last week's issues).
- Split your automation rule across several rules if you need more components per rule.
- For large, one-off operations that need to edit several thousands of issues, use Jira's bulk change functionality.
Increasing service limits
You can change these values via a REST API.
Use a REST call to increase limits
First, find out what your current limits are using this HTTP REST call:
https://YOUR_JIRA_INSTANCE_URL/rest/cb-automation/latest/configuration/property:
{
"max.processing.time.per.day": "3600",
"rule.rate.per.five.second": "2",
"short.scheduled.interval.issue.limit": "1000",
"max.rules.per.hour": "5000",
"max.issues.per.search": "1000",
"max.queued.items.per.rule": "25000"
}Lets break these down:
| Property | Description |
|---|---|
max.processing.time.per.day | This is the maximum number of seconds a single rule can spend processing in the last 24hr period. That is, if a rule takes 1 min to execute on average and it executes 60 times in a 24 hour limit, then this rule would be throttled. |
rule.rate.per.five.secondmax.rules.per.hour | These control how many rules can be processed. These work like this:
This guarantees that if there's spikes of activity, they'll be throttled. However, if after this spike, activity returns to normal and rules trickle in slowly, then they execute again immediately. For example, you have rule A triggered 10 times in the last 5 seconds: how many times did all rules trigger in the last hour is checked. If this exceeds 5000 for the instance, then this rule execution is throttled. |
max.issues.per.search | This controls how many issues are processed in total by any trigger that runs a search (e.g. JQL or Incoming Webhook trigger). Defaults to jira.search.views.default.max configuration property which can be configured separately. |
short.scheduled.interval.issue.limit | This limit is used to reduce the interval at which large issue searches can be performed using a scheduled trigger. If a query returns more issues than this limit, the UI shows a warning and only allow schedules of, at most, 4 times in a 24 hour period. This is a soft limit, meaning it only applies when configuring a rule. |
automation.processing.thread.pool .size.per.node | This one is a bit different from properties above. It defines the number of threads processing rules off the queue in Jira server. By default, this is 4 threads per server (or per node in data center). Generally this should be plenty for most instances. If you are seeing slow rule executions, you may want to increase this to 8 threads. ⚠️ Warning: Increasing this value can have the opposite effect, and result in worse performance if your DB or app server can't handle the increased load. Only increase this value if you are sure your infrastructure can handle it. |
max.queued.items.per.rule | See queued service limits for more information. |
max.queued.items | Similar to max.queued.items.per.rule but applies globally for your Jira instance across all automation rules currently in progress. |
max.rule.execution.loop.depth | This controls how loops are detected. A rule (or rules) will be allowed to trigger itself or other rules and create an execution chain up to this limit. By default this is 10. So in the simplest case, if you have a rule that triggers itself immediately, then it will be allowed to run 10 times before it's execution is stopped and marked as a LOOP in the audit log. |
To set one of these properties, please use this REST call (the Content-Type must be set to application/json) :
PUT https://<your Jira instance url>/rest/cb-automation/latest/configuration/property
{
"key": "max.processing.time.per.day",
"value": "10000"
}Example curl command:
curl -X PUT -H 'Content-type: application/json' \
-d '{"key": "max.rules.per.hour", "value": "10000"}' \
https://your-instance.com/rest/cb-automation/latest/configuration/propertyQueued items service limit
Automation for Jira Server uses a rule processing queue to manage the execution of automation rules in your instance. Jira has limited capacity available to serve requests from users in the browser, as well as executing 'background' services such as automation rules. To ensure Jira isn't overloaded rendering it unresponsive, automation rule executions are queued and the number of items processed off the queue in parallel are limited. By default, in Cloud only 8 items are processed in parallel per Jira host, and 6 concurrent threads in server (per node for Data Center configurations).
The automation rule builder is very powerful and allows users to configure rules that do just about anything. This can result in rules that are very expensive to run. Lets consider a particular scenario with these example issues:
- ABC-120 - Parent development issue with issue type 'Task'
- ABC-121 - Subtask 1
- ABC-122 - Subtask 2
- ABC-123 - Subtask 3
- ABC-124 - Subtask 4
- ABC-125 - Subtask 5
- ABC-130 - Another Parent development issue with issue type 'Task'
- ABC-131 - Subtask 1
- ABC-132 - Subtask 2
- ABC-133 - Subtask 3
- ABC-134 - Subtask 4
- ABC-134 - Subtask 5
Now consider the following rule:

This simple rule, results in 13 individual items in the automation queue. Lets break this down:
- 1 item queued for the initial scheduled trigger execution to run the search
- 2 items queued for the matching parent issues ABC-120 & ABC-130
- Then for each of those items, the related issue's branch queues 5 items each
So that's 1 + 2 + 5 + 5 = 13 items all up.
You can see that these types of rules can quickly add up to a lot of queued items, if for example, the initial scheduled trigger matches a lot of issues, or if the related issue branches match lots of issues (related issue branches can also search for issues by JQL!).
Why are lots of items in the queue bad?
The infrastructure handles lots of items in the queue. However, single rules that insert lots of items, are detrimental for Automation for Jira's performance. We've seen one customer's rule inserting over 100,000 items in the Cloud automation queue and all 8 processors for that customer were busy for hours processing that queue, delaying all their other rules.
To get around this to some extent, certain rule executions are prioritized (e.g. Manual rule triggers are executed first), but this approach can only go so far.
Throttle and disable
When a rule adds an excessive number of items to the queue at the end of its execution, it's recorded in the audit log and then the rule is disabled to prevent future executions:

What types of rules can cause this?
Rules with lots of related issue branches, where each related issue branch matches a significant number of issues. For example,
- Scheduled trigger that matches 100 issues
- Related issues branch that matches 50 issues
- Another related issues branch that matches 80 issues
This results in (approximately) 13,000 items (100 * 50 + 100 * 80).
A rule with a lot of related issue branches (to simulate if conditions):
- Trigger: Issue updated
- Related issue branch with JQL: type = Bug that matches 1000 issues
- Related issue branch with JQL: type = Task that matches 500 issues
- Related issue branch with JQL: type = Feature that matches 2000 issues
This results in 3,500 items or more, depending on the number of branches (1000 + 500 + 2000).
Prevention
Finally you've arrived at the spicy part! Luckily most rules don't execute for quite so many issues on every execution. There's a number of options to help reduce this problem:
- Ensure you use JQL that limits the execution to the smallest possible set of issues. This can be achieved in a number of ways:
- Ensure your JQL search is as specific as possible. E.g. don't just search for issues that match
type = Taskif you only care about issues currently 'In Progress'.type = Task and status = "In Progress"would be a better search - Only include issues that have changed since the last time the rule executed by checking the
Only include issues that have changed since the last time this rule executedcheckbox. For many rules, it's perfectly fine to operate only on this small sub-set
- Ensure your JQL search is as specific as possible. E.g. don't just search for issues that match
- Don't create related issue branches for 'conditional checks'. So the rule above, with many related issue branches checking for
type = Bug,type = Task, etc. could be written more efficiently like this:- Trigger: Issue updated
- Related issue branch with specific JQL to match the issues you're after (related to the trigger issue somehow)
- On this branch use the if/else block to match based on the issue type
In general, the goal is to reduce the overall number of issues a rule fetches, either via the trigger or related issue branches.