Confluence Data Center Technical Overview
Confluence Data Center enables you to configure a cluster similar to the one pictured here with:
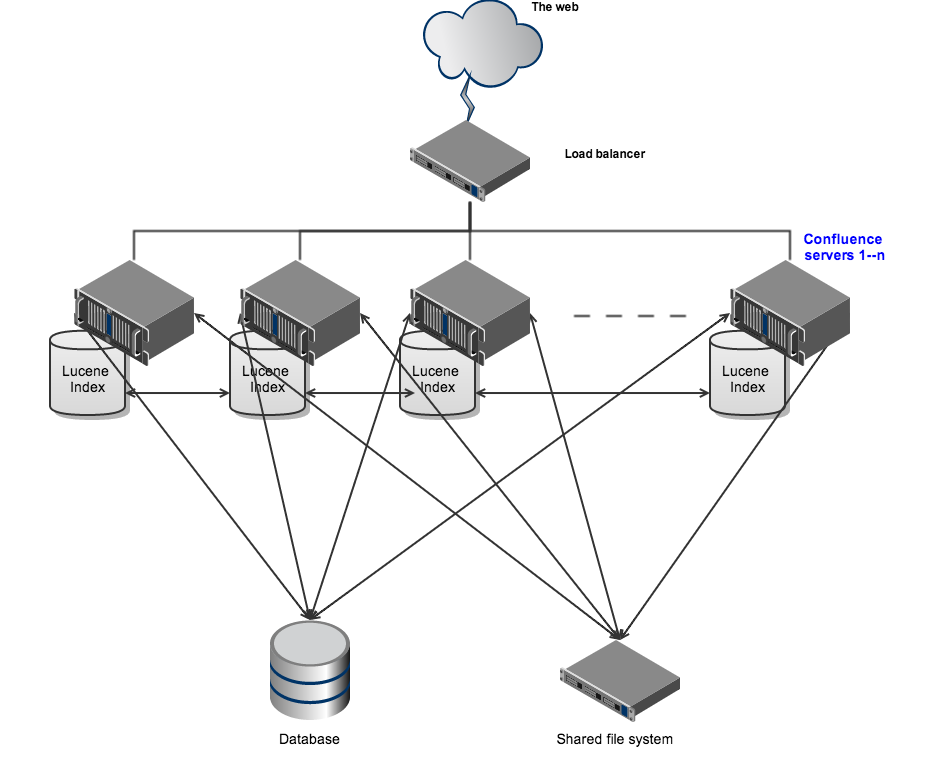
- Multiple server nodes that store:
- logs
- caches
- Lucene indexes
- configuration files
- plugins
- A shared file system that stores:
- attachments
- avatars / profile pictures
- icons
- export files
- import files
- plugins
- A database that all nodes read and write to.
- A load balancer to evenly direct requests to each node.
All nodes are active and process requests. A user will access the same node for all requests until their session times out, they log out or a node is removed from the cluster.
Licensing
Your Data Center license is based on the number of users in your cluster, rather than the number of nodes. You can monitor the available license seats in the License page.
If you wanted to automate this process (for example to send alerts when you are nearing full allocation) you can use the REST API.
Home directories
Confluence has a concept of a local home and shared home. Each node has a local home that contains logs, caches, Lucene indexes and configuration files. Everything else is stored in the shared home, which is accessible to each node in the cluster. Attachments, icons and avatars are stored in the shared home as are export and import files.
Add-ons can choose whether to store data in the local or shared home, depending on the needs of the add-on.
If you are currently storing attachments in your database you can continue to do so, but this is not available for new installations.
Caching
Confluence uses a distributed cache that is managed using Hazelcast. Data is evenly partitioned across all the nodes in a cluster, instead of being replicated on each node. This allows for better horizontal scalability, and requires less storage and processing power than a fully replicated cache.
Because of this caching solution, to minimise latency, your nodes should be located in the same physical location.
Indexes
A full copy of the Confluence indexes are stored on each node individually. A journal service keeps each index in synch. If you need to reindex Confluence for any reason, this is done on one node, and then picked up by the other nodes automatically.
When you first set up your cluster, you will copy the local home directory, including the indexes, from the first node to each new node.
When adding a new node to an existing cluster, you will copy the local home directory of an existing node to the new node. When you start the new node, Confluence will check if the index is current, and if not, request a recovery snapshot of the index from a running node (with a matching build number) and extract it into the index directory before continuing the start up process. If the snapshot can't be generated or is not received by the new node in time, existing index files will be removed, and Confluence will perform a full re-index.
If a node is disconnected from the cluster for a short amount of time (hours), it will be able to use the journal service to bring its copy of the index up-to-date when it rejoins the cluster. If a node is down for a significant amount of time (days) its Lucene index will have become stale, and it will request a recovery snapshot from an existing node as part of the startup process.
Cluster safety mechanism
A scheduled task, ClusterSafetyJob, runs every 30 seconds in Confluence. In a cluster, this job is run on one node only. The scheduled task operates on a safety number – a randomly generated number that is stored both in the database and in the distributed cache used across the cluster. The ClusterSafetyJob compares the value in the database with the one in the cache, and if the value differs, Confluence will shut the node down - this is known as cluster split-brain. This safety mechanism is used to ensure your cluster nodes cannot get into an inconsistent state.
If cluster split-brain does occur, you need to ensure proper network connectivity between the clustered nodes. Most likely multicast traffic is being blocked or not routed correctly.
This mechanism also exists in standalone Confluence.
Balancing uptime and data integrity
By changing how often the cluster safety scheduled job runs and the duration of the Hazelcast heartbeat (which controls how long a node can be out of communication before it's removed from the cluster) you can fine tune the balance between uptime and data integrity in your cluster. In most cases the default values will be appropriate, but there are some circumstances where you may decide to trade off data integrity for increased uptime for example.
Cluster locks and event handling
Where an action must only run on one node, for example a scheduled job or sending daily email notifications, Confluence uses a cluster lock to ensure the action is only performed on one node.
Similarly, some actions need to be performed on one node, and then published to others. Event handling ensures that Confluence only publishes cluster events when the current transaction is committed and complete. This is to ensure that any data stored in the database will be available to other instances in the cluster when the event is received and processed. Event broadcasting is done only for certain events, like enabling or disabling an add-on.
Cluster node discovery
When configuring your cluster nodes you can either supply the IP address of each cluster node, or a multicast address.
If you're using multicast:
Confluence will broadcast a join request on the multicast network address. Confluence must be able to open a UDP port on this multicast address, or it won't be able to find the other cluster nodes. Once the nodes are discovered, each responds with a unicast (normal) IP address and port where it can be contacted for cache updates. Confluence must be able to open a UDP port for regular communication with the other nodes.
A multicast address can be auto-generated from the cluster name, or you can enter your own, during the set-up of the first node.
Infrastructure and hardware requirements
The choice of hardware is up to you. Below are some areas to think about when planning your hardware and infrastructure requirements.
Servers
We recommend your servers have at least 4GB of physical RAM. A high number of concurrent users means that a lot of RAM will be consumed. You usually don't need to assign more than 4GB per JVM process, but can fine tune the settings as required.
You should also not run any additional applications (other than core operating system services) on the same servers as Confluence. Running Confluence, JIRA and Bamboo on a dedicated Atlassian software server works well for small installations but is discouraged when running at scale.
Confluence Data Center can be run successfully on virtual machines. If you're using multicast, you can't run Confluence Data Center in Amazon Web Services (AWS) environments as AWS doesn't currently support multicast traffic.
Cluster nodes
Your Data Center license does not restrict the number of nodes in your cluster. We have tested the performance and stability with up to 4 nodes.
Each node does not need to be identical, but for consistent performance we recommend they are as close as possible. All cluster nodes must:
- be located in the same data center
- run the same Confluence version
- have the same OS, Java and application server version
- have the same memory configuration (both the JVM and the physical memory) (recommended)
- be configured with the same time zone (and keep the current time synchronized). Using ntpd or a similar service is a good way to ensure this.
![]() You must ensure the clocks on your cluster nodes don't diverge, as it can result in a range of problems with your cluster.
You must ensure the clocks on your cluster nodes don't diverge, as it can result in a range of problems with your cluster.
Database
The most important requirement for the cluster database is that it have sufficient connections available to support the number of nodes. For example, if each Confluence instance has a connection pool of 20 connections and you expect to run a cluster with four nodes, your database server must allow at least 80 connections to the Confluence database. In practice, you may require more than the minimum for debugging or administrative purposes.
You should also ensure your intended database is listed in the current Supported Platforms. The load on an average cluster solution is higher than on a standalone installation, so it is crucial to use the a supported database.
Shared home directory and storage requirements
All cluster nodes must have access to a shared directory in the same path. NFS and SMB/CIFS shares are supported as the locations of the shared directory. As this directory will contain large amount of data (including attachments and backups) it should be generously sized, and you should have a plan for how to increase the available disk space when required.
Load balancers
We suggest using the load balancer you are most familiar with. The load balancer needs to support ‘session affinity’.
Network adapters
Use separate network adapters for communication between servers. The Confluence cluster nodes should have a separate physical network (i.e. separate NICs) for inter-server communication. This is the best way to get the cluster to run fast and reliably. Performance problems are likely to occur if you connect cluster nodes via a network that has lots of other data streaming through it.
Additional requirements for high availability
Confluence Data Center removes the application server as a single point of failure. You can further minimise single points of failure by ensuring your load balancer, database and shared file system are also highly available.
Plugins and add-ons
The process for installing add-ons in Confluence Data Center is the same as for a standalone instance of Confluence. You will not need to stop the cluster, or bring down any nodes to install or update an add-on.
The Atlassian Marketplace indicates add-ons that are compatible with Confluence Data Center.
Add-on licenses for Data Center are sold at the single server rate, but must match or exceed your Confluence Data Center license tier. For example, if you are looking to have 3,000 people using Confluence Data Center, then you would buy any add-ons at the 2-001-10,000 user tier.
If you have developed your own plugins for Confluence you should refer to our developer documentation on How do I ensure my add-on works properly in a cluster? to find out how you can confirm your plugin is cluster compatible.
Ready to get started?
Contact us to speak with an Atlassian or get started with Data Center today.