Attachment Storage Configuration
By default Confluence stores attachments in the home directory (e.g. in a file system).
If you have upgraded from an earlier Confluence version you may still be storing attachments in your database or WebDAV. These storage methods are no longer supported.
See below for instructions to migrate to a supported storage method.
Attachment storage methods
Local file system
By default, Confluence stores attachments in the attachments directory within the configured Confluence home folder.
S3 object storage
Starting from Confluence 8.1, you can also store your attachment data on Amazon S3 object storage. We recommend this method if your team has large or increasing data needs and requires the ability to scale efficiently. Learn more about configuring S3 object storage.
Database (deprecated)
Confluence 5.4 and earlier gave administrators the option to store attachments in the database that Confluence is configured to use. We have since deprecated this method of attachment storage.
If you are still using this attachment storage method, you will not be able to successfully upgrade to Confluence 8.8 or later. Before proceeding with your upgrade, migrate your attachments to the local file system. We have provided instructions on how to do this below.
Migrating to a supported attachment storage option
From your database to the file system
If you are still storing attachments on your database, you can migrate to storing attachments in the file system. When migrating attachments from your database to a file system, the attachments are removed from the database after migration.
When the migration occurs, all other users will be locked out of the Confluence instance. This is to prevent modification of attachments while the migration occurs. Access will be restored as soon as the migration is complete.
To improve logging during the migration, add the package com.atlassian.confluence.pages.persistence.dao with level DEBUG. See Configuring Logging for more information.
To migrate, follow the steps below:
- Go to Administration
 > General Configuration > Attachment storage.
> General Configuration > Attachment storage. - Select Edit to modify the configuration.
- Select Locally in Confluence home directory.
- Select Save to save the changes.
- A screen will appear, asking you to confirm your changes. Selecting Migrate will take you to a screen that displays the progress of the migration.
Screenshot: migration warning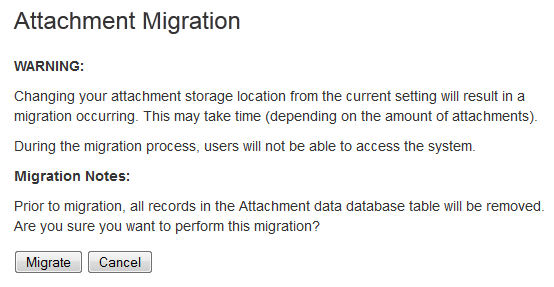
If you're already storing attachments in a file system, the Attachment Storage option won't appear in the admin console - this is because you're already using the only supported storage method, and don't need to migrate.
Troubleshooting
It is a known issue that the form and checkbox to select Locally in Confluence home directory is disabled. If you are unable to check the box, see Unable to select form to migrate attachments from Confluence database to file system for a workaround.
From the file system to S3 object storage
If you have existing attachment data and you want to use Amazon S3, you should migrate attachments to an S3 bucket for Confluence to consume.
To migrate, follow the steps below:
- Check that you're using Confluence 8.1 or newer.
- Check that the migration to
v4hierarchical attachment storage structure is complete. Learn how to do this - Create a new Amazon S3 bucket for Confluence (follow step 1 on Configuring S3 object storage).
Migrate the
v4attachment data (${confluenceHome}/attachments/v4) from its physical source to the root prefixconfluence/attachments/in the S3 bucket.
For example:File system ${confluenceHome}/attachments/v4/14/0/327689/327689.1S3 <S3_Bucket>/confluence/attachments/v4/14/0/327689/327689.1The physical location of this data is dependent on your environment. For example, clustered environments typically host this data in a network file system (NFS) as a shared mount. You'll need to consider you setup and the amount of attachment data that needs to be migrated. In general, we recommend using Amazon DataSync for migration. Learn how to do this
Wait for the migration to complete.
Configure your Confluence node(s) one by one with AWS authentication details and your S3 configuration (follow steps 2 and 3 on Configuring S3 object storage).
- Consider putting Confluence into read-only mode to avoid data creation until all node(s) are configured for S3.
After providing the relevant configuration, each node will require a restart.
During this process, if attachments are created on nodes that have yet to be configured for S3, then the attachment data won't be available to those nodes that have been configured for S3.
- Verify that Confluence is using S3 object storage with the following steps:
Go to Administration
> General Configuration > System InformationNext to Attachment Storage Type, you'll see S3
Additionally, next to Java Runtime Arguments, both the bucket name and region system properties and their respective values will be visible.
Re-run the original DataSync job to perform a final sync. This should be done after all the nodes have been configured to ensure all attachment data is migrated.
![]() At this stage, attachment data will be read and written from AWS S3.
At this stage, attachment data will be read and written from AWS S3.
DataSync does not alter or remove the source file system data. So, if you no longer need the attachment data stored on the file system, you'll need to clean this up manually.
Troubleshooting
As the source file system data is not altered or removed by DataSync, Confluence can be reverted back to reading and writing attachment data from the file system. To do this, remove the configuration below from your setenv.sh and/or confluence.cfg.xml, and restart Confluence:
confluence.filestore.attachments.s3.bucket.nameconfluence.filestore.attachments.s3.bucket.region
If you are reverting back to the original file system, any data written to S3 will need to be synced back to the file system manually by the Confluence administrator.