Failed to propagate index in Confluence Data Center 7.7 and later
Platform Notice: Data Center - This article applies to Atlassian products on the Data Center platform.
Note that this knowledge base article was created for the Data Center version of the product. Data Center knowledge base articles for non-Data Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Problem
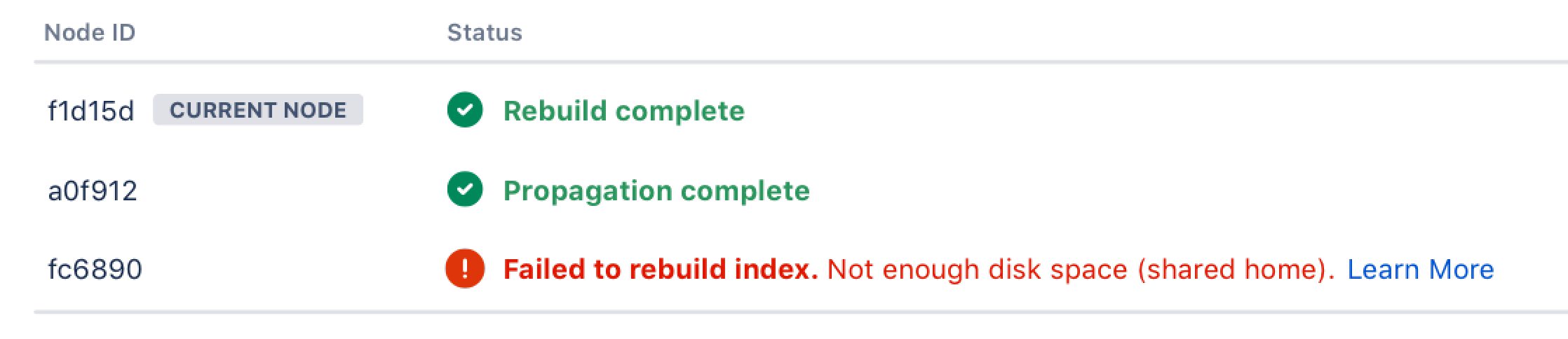
When rebuilding the search index in Confluence Data Center 7.7 or later, one of the following errors appear when Confluence attempts to propagate the index to other nodes in the cluster.
Not enough disk space (local home)
Not enough disk space (shared home)
Can't access shared home
Can't write to local home
Screenshot: A propagation error shown on the Content Indexing screen.
Cause
When you rebuild the search index in a cluster, Confluence will store a snapshot of the newly rebuilt index (from the node you triggered the rebuild on) in the shared home directory, and use that snapshot to propagate the new index to the other nodes in the cluster, one by one. The existing index files are not removed until after propagation is complete.
This will fail if the user account used to run Confluence can't write to the local home directory, access the shared home directory, or if there's not enough free disk space to accomodate two full copies of the index.
Resolution
First, you'll need to resolve the root cause of the problem:
- Make sure the user you use to run Confluence (the dedicated Confluence user) has adequate permission to access and write to your shared home and local home directories.
- Check there's adequate disk space available in the shared home, and each local home directory. You'll need to allow enough space for at least two full copies of the index.
Next you can re-try the propagation. For the purposes of the steps below, we'll assume you have a two node cluster. The index was rebuilt successfully on node 1, but failed to propagate to node 2.
To re-try the propagation:
- On node 2, go to
<local-home>/journaland delete the file namedsystem-maintenance. - Either restart Confluence on Node 2, or:
- Access Confluence on Node 2.
- Go to Administration menu
 , then General Configuration > Cache Management.
, then General Configuration > Cache Management. - Choose Flush All.
After 10 seconds, Confluence will try to propagate the snapshot to node 2.
Note that Confluence's index recovery feature will not automatically recover a snapshot created by the rebuild index process. Index recovery is designed to help when a node has been out of the cluster for several days, and the journal isn't able to bring it up to date. Simply restarting Confluence on the affected node won't recover a newly rebuilt index.