Storing attachments in Amazon S3
By default, all attachments in Jira are stored locally in the file system. You can also configure a custom storage method — Amazon S3 (Simple Storage Service). We recommend using Amazon S3 if your team has large or increasing data needs and requires the ability to scale efficiently.
Before you begin
If you're considering using Amazon S3 for storing attachments, first read through the configuration requirements and current limitations to make sure this storage method is suitable for you. Learn more about Amazon S3 configuration
How S3 attachment storage is set up in Jira
Attachment storage in Amazon S3 is configured in the filestore-config.xml file that should be located in Jira <localhome>.
To use S3 as a target location for attachment data, the filestore attribute in the filestore-config.xml must match the s3-filestore ID.
If you’re already storing avatars in S3, you can configure the filestore-config.xml file to store attachments there as well. To do this, add a new association element with the target attachments.
If you want to store attachments in the same bucket as avatars, the filestore attribute should point to the same bucket where avatars are located.
To use separate buckets for attachments and avatars, define multiple <s3-filestore> elements and reference each of them in the respective association targets.
If you want to use a Jira <sharedhome> directory to store attachments but don’t want to delete the configuration file, just remove the association element with a target of attachments. Jira will default to storing attachments locally if S3 isn't configured in filestore-config.xml or if this file is missing from the <localhome> directory.
Connecting to Amazon S3 dual-stack endpoints
If your Jira installation is on an IPv6-only network, you need to connect to Amazon S3 dual-stack endpoints. Learn more about Amazon S3 dual-stack endpoints
To set up the connection, you need to override the default endpoint with the dual-stack endpoint like this:
<?xml version="1.1" ?>
<filestore-config>
<filestores>
<s3-filestore id="attachmentBucket">
<config>
<bucket-name>dualstack-bucket</bucket-name>
<region>us-east-1</region>
<endpoint-override>https://s3.dualstack.us-east-1.amazonaws.com</endpoint-override>
</config>
</s3-filestore>
</filestores>
<associations>
<association target="attachments" file-store="attachmentBucket" />
</associations>
</filestore-config>You can also use this configuration option to store attachments in a third-party object store that exposes an S3-compatible API. However, we’re not providing direct support for attachments that are stored in an object store other than Amazon S3.
Migrate your attachment data to Amazon S3
If you have existing attachments in the file system and want to use Amazon S3, you need to migrate all attachments to an S3 bucket for Jira to consume.
If you are migrating attachments to S3 and use Assets in Jira Service Management, ensure that the <sharedhome>/data/attachments/insight/ directory is migrated to your S3 bucket along with the <sharedhome>/data/attachments directory.
From Jira Software 9.13 and Jira Service Management 5.13 onwards, if Jira is configured to store attachments in Amazon S3, the Assets app will store its files in the same S3 bucket.
Note that groovy scripts used in Assets automation rules will always be loaded from the filesystem and never from an S3 bucket.
Jira apps can install app-specific data to the <sharedhome>/data/attachments directory. Do not move this data to Amazon S3 unless specified by the app developer, as moving this data might break the app’s functionality.
To migrate your attachments:
Check your Jira version and make sure that you’re on Jira 9.11 or later.
Create and set up a new Amazon S3 bucket for Jira. Learn how to configure Amazon S3 as your data storage method
Migrate your attachment data from its physical location in
<sharedhome>/data/attachments/to the root prefixattachments/in the S3 bucket.The physical location of attachments depends on your environment. For example, clustered environments typically host this data in a network file system (NFS) as a shared mount.
You need to consider your setup and how much data you need to migrate. In general, we recommend using Amazon DataSync for migration.
Wait for the migration to complete.
Configure your Jira nodes one by one by creating a filestore-config.xml file with valid S3 bucket information in the
<localhome>of each node in your Jira cluster. After you provide the relevant configuration, each node will require a restart.
During this process, if attachment files are created on nodes that have yet to be configured for S3, attachments won't be available to already configured nodes. Likewise, those nodes will not have access to attachments created on nodes that are already configured to use S3.Ensure the feature flag is enabled.
Verify that Jira is using S3 object storage:
In the upper-right corner of the screen, select Administration
 > System.
> System.Under Advanced (in the left-side panel), select Attachments. To access the page directly, use the
ggshortcut or press the full stop.and search for “Attachments”.Next to the Attachments location, you should see Amazon S3, as well as the region and bucket you specified in filestore-config.xml.

Make sure all the nodes have been configured and all attachments are migrated, and then re-run the original DataSync job to perform a final sync.
All attachments should now be read and written from Amazon S3.
DataSync doesn’t change or remove the source file system data. If you no longer need attachments located in the file system, you need to remove this data manually.
Switching back to local attachment storage
As the source file system data is not changed or removed by DataSync, Jira can be reverted back to reading and writing attachment data from the file system. To do this, remove the filestore-config.xml files from your <localhome> directories and restart Jira. You can also delete the <association> element targeting attachments.
If you are reverting back to the original file system, any data written to S3 must be synced back to the file system manually by the Jira administrator.
Configure Amazon S3 to store attachments
If you’re ready to proceed with Amazon S3 configuration, follow the instructions from the Configuring Amazon S3 as your data storage method.
Connect your S3 bucket with Jira
After you configure S3 object storage, you need to connect the created S3 bucket with your Jira instance:
In the Jira application home directory of one of your Jira installation nodes, create a
filestore-config.xmlfile. The Jira application home directory should be set to the value of theJIRA_HOMEenvironment variable. Learn about the contents of the Jira application home directoryIn the
filestore-config.xmlfile, define which S3 bucket will be used by Jira to store attachments and avatars. Learn more about storing avatars in S3Sample
filestore-config.xmlfile:<?xml version="1.1" ?> <filestore-config> <filestores> <s3-filestore id="attachmentBucket"> <config> <bucket-name>example-co-jira-attachment-bucket</bucket-name> <region>ap-southeast-4</region> </config> </s3-filestore> </filestores> <associations> <association target="attachments" file-store="attachmentBucket" /> </associations> </filestore-config>If you’re running a clustered installation, copy the
filestore-config.xmlfile to the Jira application home directory of the other nodes.Start or restart all Jira nodes.
When Jira starts up, it will check your bucket configurations, such as bucket connectivity, name and region validity, and bucket permissions. Learn about potential errors and how to fix them
To verify that Jira is using Amazon S3 object storage:
In the upper-right corner of the screen, select Administration
> System.Under Advanced settings (the left-side panel), select Attachments.
Next to the Attachments storage location, you'll see that attachments are stored in S3. Here you can also check the S3 bucket name and region.
Troubleshooting S3 attachment storage
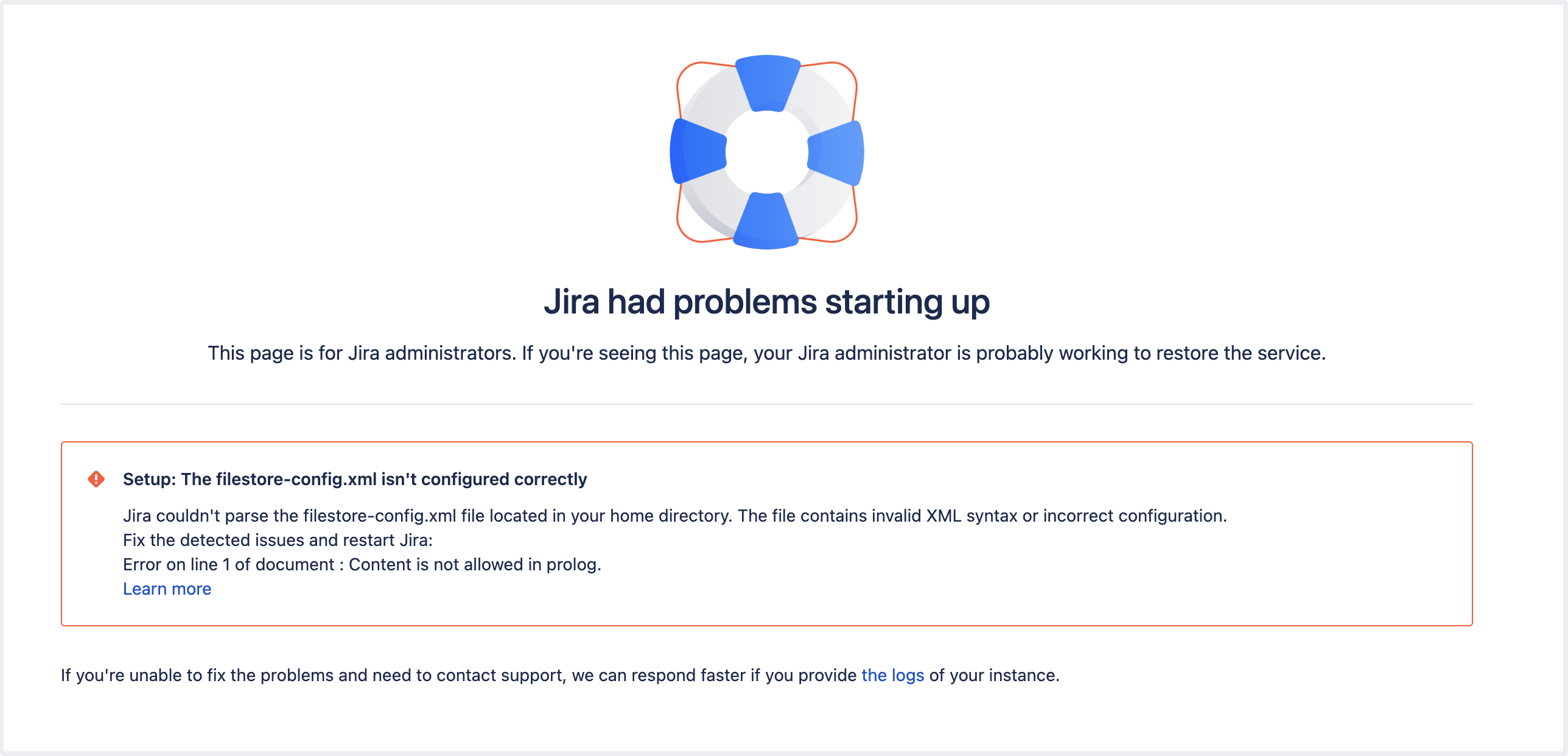
When Jira starts up, it runs a series of checks to make sure there are no issues with the filestore-config.xml file. If there are any errors during the file parsing, Jira won't start and will display an error message.
If there are problems connecting to or performing operations on S3, Jira will also detect them and flag the Attachment Filestore instance health check as failing.
The following sections list the problems that can happen during S3 configuration along with the resolution steps. The issues are mainly related to improper S3 configuration, permissions, or authentication.
Jira startup failures
You can also find more details about the problems by checking Jira logs at <localhome>/log/atlassian-jira.log. Learn how to access Jira logs
| Problem | Root cause & resolution |
|---|---|
Couldn’t parse
| The Ensure that the file consists of valid XML. |
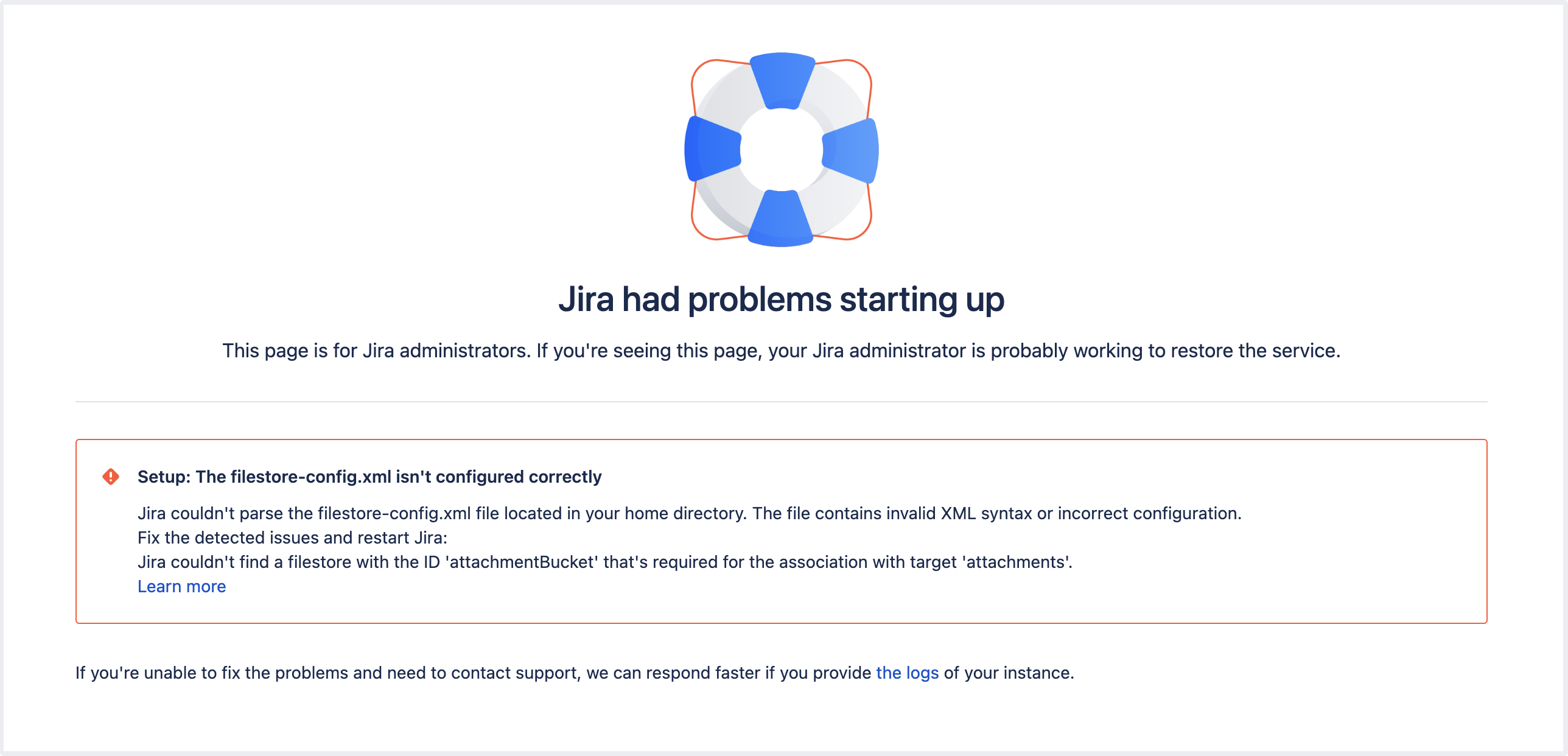
Invalid
| The If you provide an |
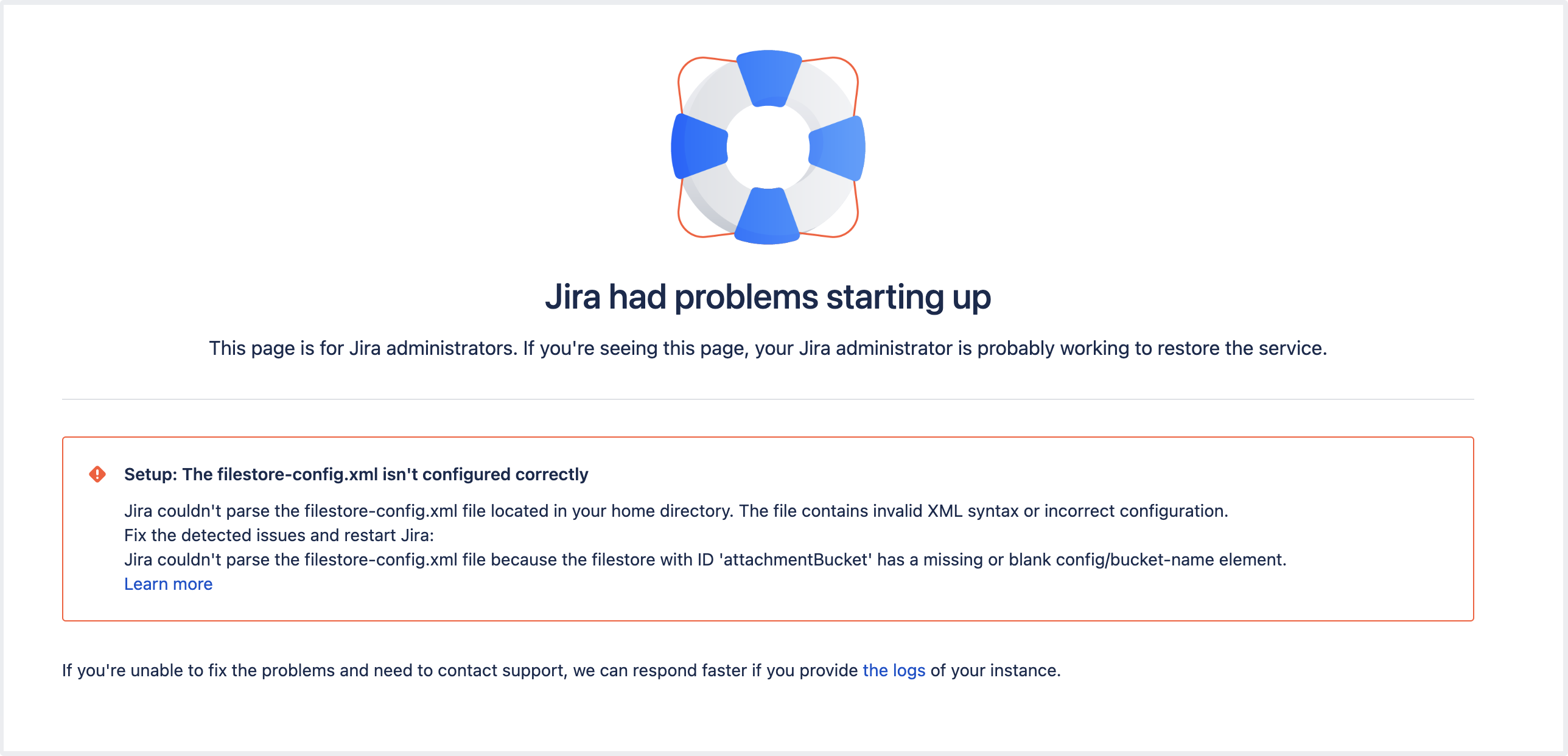
Missing
| An |
Health check failures
Learn more about the instance health checks and how they are performed. Learn more about instance health checks
| Problem | Root cause & resolution |
|---|---|
Unable to list the contents of attachment storage
| This health check can fail due to the following reasons.
Details on why the check failed are provided in the health check result. If you need further help diagnosing the issue, check the logs in |
Unable to read data from attachment storage
| The
|
Unable to write to attachment storage
| The
|
Unable to delete files from attachment storage
| The
|




Mitigating S3 connection issues for slow or unreliable networks
Jira uses the Amazon S3 CRT asynchronous client to connect to Amazon S3.
The Amazon S3 CRT-based client allows controlling multiple simultaneous threads for a single connection for read and write operations. A Jira admin can configure the client settings to mitigate upload and download failures if the Jira server’s internet connection is unstable or slow.
The Amazon S3 CRT-based client allows tuning several parameters, the most important of which is max-concurrency. By default, max-concurrency is set to 100 threads. It’s been introduced to the Jira filestore configuration filestore-config:
<?xml version="1.1" ?>
<filestore-config>
<filestores>
<s3-filestore id="attachmentBucket">
<config>
<bucket-name>dualstack-bucket</bucket-name>
<region>us-east-1</region>
<max-concurrency>100</max-concurrency>
</config>
</s3-filestore>
</filestores>
<associations>
<association target="attachments" file-store="attachmentBucket" />
</associations>
</filestore-config>The growing number of concurrent connections can increase client throughput. This also implies that your application has to manage more resources simultaneously.