Scheduled Jobs
The administration console allows you to schedule various administrative jobs in Confluence, so that they are executed at regular time intervals. The types of jobs which can be scheduled cover:
- Storage optimization jobs to clear Confluence's temporary files and caches
- Index optimization jobs to ensure Confluence's search index is up to date
- Mail queue optimization jobs to ensure Confluence's mail queue is maintained and notifications have been sent.
![]() You'll need System Administrator permissions in order to edit and manually run jobs.
You'll need System Administrator permissions in order to edit and manually run jobs.
Accessing Confluence's scheduled jobs configuration
To access Confluence's Scheduled Jobs configuration page:
Go to Administration menu
 , then General Configuration > Scheduled Jobs
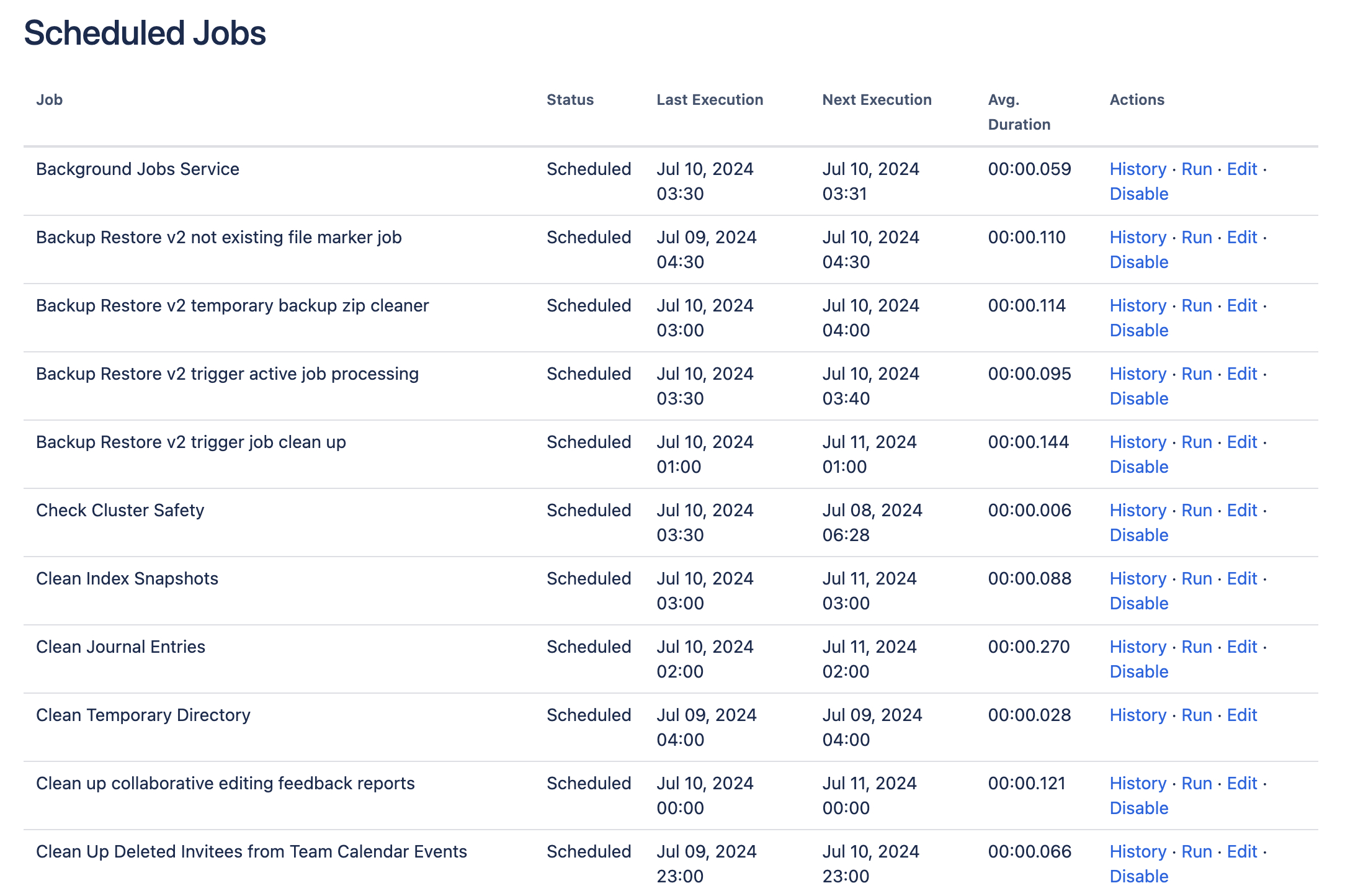
, then General Configuration > Scheduled JobsAll scheduled jobs are listed with:
Status - the job's status, which is either 'Scheduled' (it it is currently enabled) or 'Disabled'.
Last Execution - the date and time when the job was last executed. This field will be empty of the job was never executed.
Next Execution -the date and time when the job is next scheduled to be executed. This field will contain dash symbol ('-') if the job is disabled.
Avg. Duration - the length of time (in milliseconds) that it took to complete the job (the last time it ran).
Actions - Options to edit the job's schedule, run it manually, view the history or disable the job.
Screenshot: Scheduled Jobs
Running a job manually
To run a job manually head to the Scheduled Jobs list and choose Run next to the job. It will run immediately.
Not all jobs can be run manually.
Changing a job's schedule
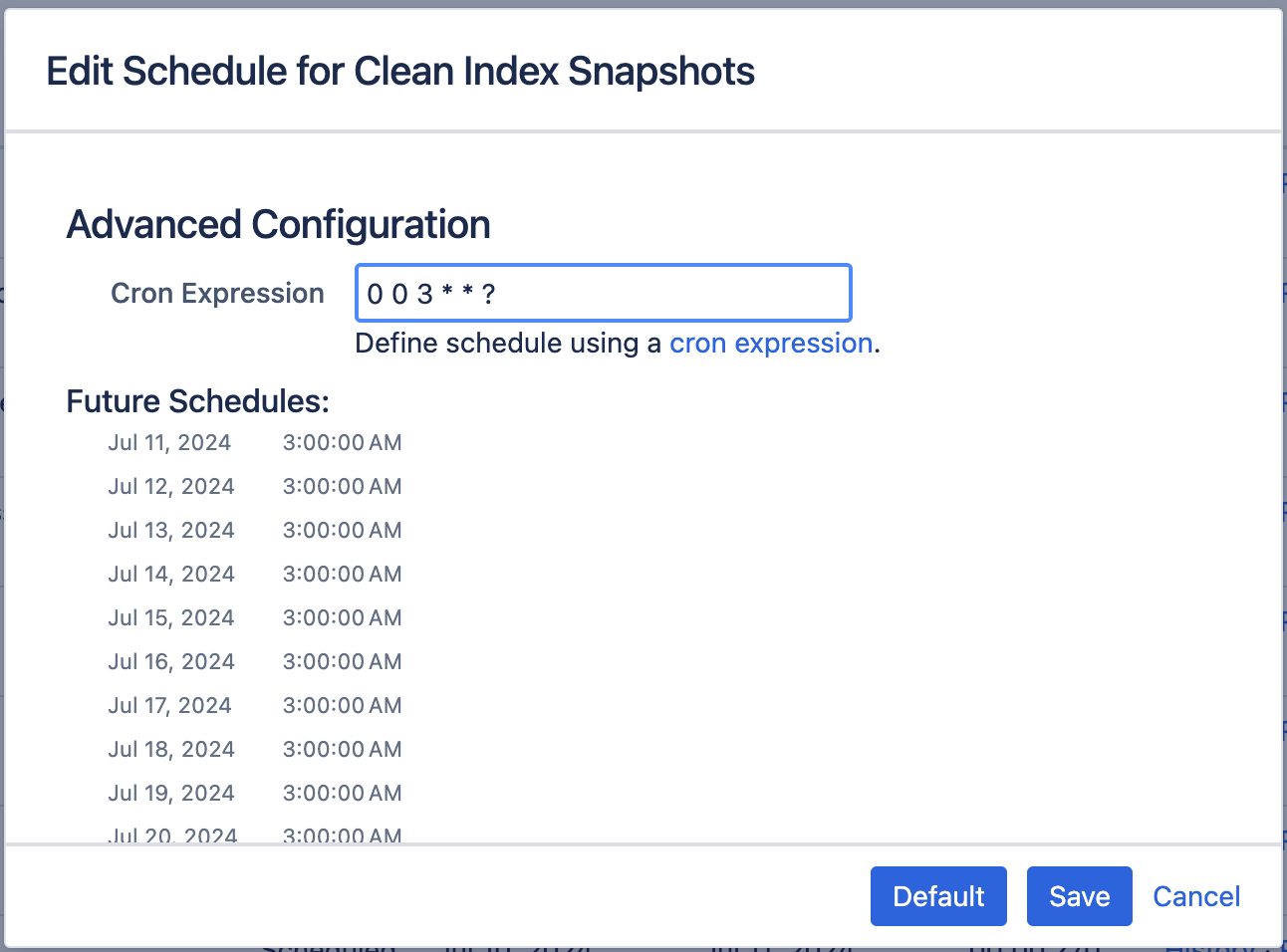
To change a job's schedule:
Choose Edit next to the job you want to change.
Enter the new day or time to run the job as a cron expression - there's more info about cron expressions below. There are also some jobs that can only be scheduled to run at regular intervals in seconds, we call these simple jobs.
Save your changes to the job's schedule, or Revert back to the default setting.
Not all jobs' schedules are configurable.
Screenshot: Configuring a job scheduled using cron expressions
Screenshot: Configuring a simple job schedule using seconds
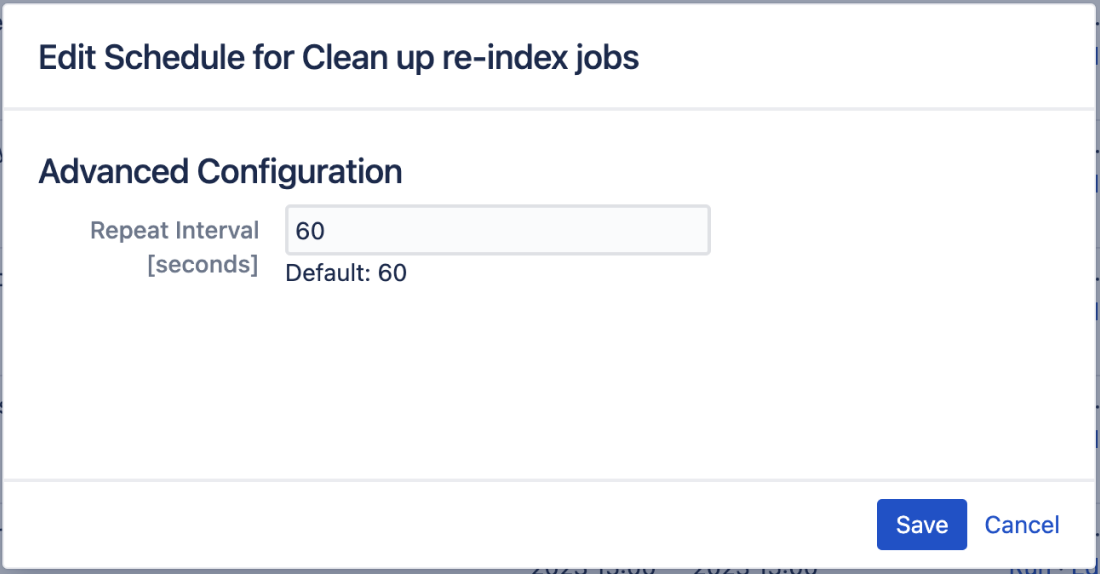
When you enable or edit a simple job, it won't run immediately after it has been enabled. Instead, it'll run at interval seconds, where interval seconds is the interval you've set.
For example, if you enable the simple job "Clean up re-index jobs" to run every 60 seconds, the first time it will run is 60 seconds after you save the schedule, and then every 60 seconds thereafter.
Disabling or re-enabling a job
By default, all jobs in Confluence are enabled.
Use the Disable / Enable links in the action column to disable and re-enable each job.
Not all jobs in Confluence can be disabled.
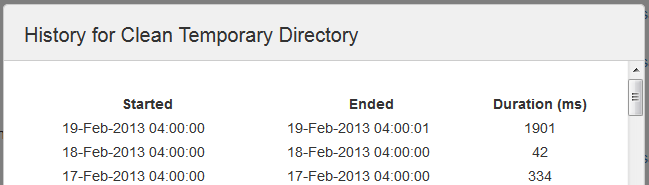
Viewing a job's execution history
To see when a job was last run, and how long the job took to run, click the History link beside the job.
If a job has not run at least once the History link won't appear.
Screenshot: Job Execution History
![]() Execution history is not available in Confluence Data Center.
Execution history is not available in Confluence Data Center.
Jobs overview
Here's a summary of some of the scheduled jobs that you may want to adjust.
Job Name | Description | Execution Behavior | Default Schedule |
|---|---|---|---|
| Backup Restore v2, not existing file marker job | Checks if backup files exist and, if not, marks backup entries in the database. | Per cluster | At 4:30am every day |
| Backup Restore v2 temporary backup zip cleaner | Cleans up any backup XML files saved to the restore directory for 72 hours or longer. If a user has chosen to save a backup permanently, it will not be deleted as part of this scheduled job. | Per cluster | Every hour |
| Backup Restore v2 trigger job clean up | Cleans up any backup or restore jobs (including metadata and related files) done on the site 14 days ago or longer. If a user has chosen to save a backup permanently, it will not be deleted as part of this scheduled job. | Per cluster | At 1am every day |
Check Cluster Safety | For clustered Confluence installations, this job ensures that only one Confluence instance in the cluster writes to the database at a time. For standard (non-clustered) editions of Confluence, this job is useful for alerting customers who have accidentally connected a second Confluence instance to a Confluence database which is already in use. | Per cluster | Every 30 seconds |
Clean Journal Entries | Periodically clears journal entries that have already been processed to ensure that its size does not grow indefinitely. | Per cluster | At 2am every day |
Clean Temporary Directory | Cleans up temporary files generated in the | Per node | At 4am every day |
Clear Expired Mail Errors | Clears notification errors in the mail error queue. A notification error is sent to the mail error queue whenever the notification fails to be sent due to an error. | Per cluster | At 3am every day |
Clear Expired Remember Me Tokens | Clears all expired 'Remember Me' tokens from the Confluence site. Remember Me tokens expire after two weeks. | Per cluster | On the 20th of each month |
Email Daily Reports | Emails a daily summary report of all Confluence changes to all subscribers. | Per cluster | At 12am every day |
Flush Change Index Queue | Flushes the Change Index Queue so Confluence's search results stay up to date. | Per node | Every minute |
Flush Content Index Queue | Flushes the Content Index Queue so Confluence's search results stay up to date. | Per node | Every minute |
Flush Edge Index Queue | Flushes the Edge Index Queue so Confluence's search results stay up to date. | Per node | Every 30 seconds |
Flush Local Task Queue | Flushes the local task queue. (These are internal Confluence tasks that are typically flushed at a high frequency.) | Per node | Every minute |
Flush Mail Queue | Sends notifications that have been queued up in the mail queue. This doesn't include batched notifications. Edit the Send batched notifications job if you also want to change how often notifications are sent for changes to a page or blog post. | Per node | Every minute |
Send batched notifications | Sends email notifications containing all changes to a page or blog post since the last time the job ran. Increase the time for fewer emails or reduce the time if more immediate notifications are important in your site. | Per cluster | Every 10 minutes |
Flush Task Queue | Flushes the task queue. (These are internal Confluence tasks that are typically flushed at a high frequency.) | Per node | Every minute |
Send Recommended Updates Email | Triggers sending recommended update emails to users. The job runs hourly, but users will receive the notification weekly or daily, depending on the setting in their profile, at a time that matches their timezone. | Per cluster | Hourly |
Purge Old Job Run Details | Confluence stores the details of each scheduled job that is run in the
You can override these settings using the following system properties; | Per cluster | at 11pm every day |
Property Entry Gardening | When a page is created from a blueprint, some data is left behind in the os_property table after the page is published. This job cleans up leftover data, which could contain personally identifiable information. | Per cluster | At 12am every day |
Clean up unpublished Blueprint Page Entities | This job cleans up metadata stored about draft pages created from blueprints, which could contain personally identifiable information. | Per cluster | At 2:23am every day |
Synchrony data eviction (soft) | Evicts Synchrony data for any content that has not been modified in the last 3 days, and does not have an active editor session. See How to remove Synchrony data for more information. | Per cluster | Every 10 minutes |
Synchrony data eviction (hard) | Evicts Synchrony data for any content that is 15 days or older, regardless of whether it has been modified more recently. See How to remove Synchrony data for more information. | Per cluster | Disabled by default |
| Versions Removal (Soft) | Deletes any historical page or attachment versions that don't meet the retention rules. Deletion happens in batches to minimise performance impact. After changing a retention rule, the job may need to run multiple times before all historical versions are removed. This job will only impact Confluence Data Center instances where retention rules are customizable. | Per cluster | Every 10 minutes |
| Versions Removal (Hard) | Deletes any historical page or attachment versions that don't meet the retention rules in one go, rather than in batches. This job can be run manually when required, but may have an impact on your site performance. This job will only impact Confluence Data Center instances where retention rules are customizable. | Per cluster | Disabled by default |
| Trash Removal (Soft) | Purges any items from Space's trash that don't meet the retention rules. Deletion happens in batches to minimize performance impact. After changing a retention rule, the job may need to run multiple times before all trash is removed. This job will only impact Confluence Data Center instances where retention rules are customizable. | Per cluster | Every 10 minutes |
| Trash Removal (Hard) | Purges any items from Space's trash that don't meet the retention rules in one go, rather than in batches. This job can be run manually when required, but may have an impact on your site performance. This job will only impact Confluence Data Center instances where retention rules are customizable. | Per cluster | Disabled by default |
Type of jobs
There are some jobs you can schedule to repeat at intervals defined by a simple values like seconds. We call these simple jobs. When you edit/enable these simple jobs, they won't be executed instantly. Instead, they'll run at interval seconds, where interval seconds is the interval
For example, if the Check Cluster Safety job is set to repeat every 30 seconds, when it's enabled, it will be scheduled to run in interval seconds plus 30 seconds, which is 30 + 30 = 60 seconds.
Now you want to edit the Check Cluster Safety job to repeat every 40 seconds, when it's enabled, it will be scheduled to run in interval seconds plus 40 seconds, which is 40 + 30 =
Cron expressions
A cron expression is a string of 6-7 'time interval' fields that defines the frequency with which a job is executed. Each of these fields can be expressed as either a numerical value or a special character and each field is separated by at least one space or tab character.
The table below is shows the order of time interval fields in a cron expression and each field's permitted numerical values.
You can specify a special character instead of a numerical value for any field in the cron expression to provide flexibility in defining a job's frequency. Common special characters include:
'*' — a 'wild card' that indicates 'all permitted values'.
'?' — indicates 'ignore this time interval' in the cron expression. That is, the cron expression will not be bound by the time interval (such as 'Month', 'Day of week' or 'Year') to which this character is specified.
For more information about cron expressions, please refer to the Cron Trigger tutorial on the Quartz website.
Order in cron | Time interval | Permitted | Required? |
|---|---|---|---|
1 | Seconds | 0-59 | Yes |
2 | Minutes | 0-59 | Yes |
3 | Hours | 0-23 | Yes |
4 | Day of month | 1-31 | Yes |
5 | Month | 1-12 or JAN-DEC | Yes |
6 | Day of week | 1-7 or SUN-SAT | Yes |
7 | Year | 1970-2099 | No |
* Excluding special characters.