Confluence Data Center disaster recovery
Confluence Data Center is the only Atlassian-supported high-availability solution for Confluence.
This page demonstrates how you can use Confluence Data Center 5.9 or later in implementing and managing a disaster recovery strategy for Confluence. It doesn't, however, cover the broader business practices, like setting the key objectives (RTO, RPO & RCO1), and standard operating procedures.
What's the difference between high availability and disaster recovery?
The terms "high availability", "disaster recovery" and "failover" can often be confused. For the purposes of this page, we've defined them as follows:
- High availability – A strategy to provide a specific level of availability. In Confluence's case, access to the application and an acceptable response time. Automated correction and failover (within the same location) are usually part of high-availability planning.
- Disaster recovery – A strategy to resume operations in an alternate data center (usually in another geographic location), if the main data center becomes unavailable (i.e. a disaster). Failover (to another location) is a fundamental part of disaster recovery.
- Failover – is when one machine takes over from another machine, when the aforementioned machines fails. This could be within the same data center or from one data center to another. Failover is usually part of both high availability and disaster recovery planning.
Overview
Before you start, configure and set up your Confluence Data Center. See Set up a Confluence Data Center cluster.
This page describes what is generally referred to as a 'cold standby' strategy, which means the standby Confluence instance isn't continuously running and that you need to take some administrative steps to start the standby instance and ensure it's in a suitable state to service the business needs of your organization.
Maintaining a runbook
The detailed steps will vary from organization to organization and, as such, we recommend you keep a full runbook of steps on file, away from the production system it references. Make your runbook detailed enough such that anyone in the relevant team should be able to complete the steps and recover your service, regardless of prior knowledge or experience. We expect any runbook to contain steps that cover the following parts of the disaster recovery process:
- Detection of the problem
- Isolation of the current production environment and bringing it down gracefully
- Synchronization of data between failed production and intended recovery point
- Warm up instructions for the recovery instance
- Documentation, communication, and escalation guidelines
The major components you need to consider in your disaster recovery plan are:
| Confluence installation | Your standby site should have exactly the same version of Confluence installed as your production site. |
|---|---|
| Database | This is the primary source of truth for Confluence and contains most of the Confluence data (except for attachments, avatars, etc). You need to replicate your database and continuously keep it up to date to satisfy your RPO1 |
| Attachments | All attachments are stored in the Confluence Data Center shared home directory and should be replicated to the standby instance. If Amazon S3 object storage is used for storing attachment data, then it should be handled separately. |
| Search Index | The search index isn't a primary source of truth, and can always be recreated from the database. For large installations, though, this can be quite time consuming and the functionality of Confluence will be greatly reduced until the index is fully recovered. Confluence Data Center stores Lucene search index backups in the shared home directory, which are covered by the shared home directory replication. If you are using OpenSearch, you will need to employ a different strategy using snapshots. See Step 2. Implement a data replication strategy for more details. |
| Apps | User installed apps are stored in the database and are covered by the database replication. |
| Other data | A few other non-critical items are stored in the Confluence Data Center shared home. Ensure they're also replicated to your standby instance. |
Set up a standby system
Step 1. Install Confluence Data Center
Install the same version of Confluence on your standby system. Configure the system to attach to the standby database.
DO NOT start the standby Confluence system
Starting Confluence would write data to the database and shared home, which you do not want to do.
You may want to test the installation, in which case you should temporarily connect it to a different database and different shared home directory and start Confluence to make sure it works as expected. Don't forget to update the database configuration to point to the standby database and the shared home directory configuration to point to the standby shared home directory after your testing.
Step 2. Implement a data replication strategy
Replicating data to your standby location is crucial to a cold standby failover strategy. You don't want to fail over to your standby Confluence ins tance and find that it's out of date or that it takes many hours to re-index.
| Database | All of the following Confluence supported database suppliers provide their own database replication solutions: You need to implement a database replication strategy that meets your RTO, RPO and RCO1. |
|---|---|
| Files | You also need to implement a file server replication strategy for the Confluence shared home directory that meets your RTO, RPO and RCO1. |
| Object Storage | If you are using Amazon S3 object storage for attachments, you will need to implement a replication strategy for these. |
| OpenSearch Index | If your Confluence instance is configured to use an OpenSearch cluster that is installed and managed on-premises, you can configure Cross Cluster replication. Alternatively, you can take regular snapshots and then use a file server replication strategy for copying to a cold standby. See the OpenSearch documentation on how to setup automatic or manual snapshots on your OpenSearch cluster. If your Confluence instance is using a managed service like AWS OpenSearch cluster, configure the replication as supported by the service provider. |
Clustering considerations
For your clustered environment you need to be aware of the following, in addition to the information above:
| Standby cluster | There's no need for the configuration of the standby cluster to reflect that of the live cluster. It may contain more or fewer nodes, depending on your requirements and budget. Fewer nodes may result in lower throughput, but that may be acceptable depending on your circumstances. |
|---|---|
| File locations | Where we mention |
| Starting the standby cluster | It's important to initially start only one node of the cluster, allow it to recover the search index, and check it's working correctly before starting additional nodes. |
Disaster recovery testing
You should exercise extreme care when testing any disaster recovery plan. Simple mistakes may cause your live instance to be corrupted, for example, if testing updates are inserted into your production database. You may detrimentally impact your ability to recover from a real disaster, while testing your disaster recovery plan.
The key is to keep the main data center as isolated as possible from the disaster recovery testing.
This procedure will ensure that the standby environment will have all the right data, but as the testing environment is completely separate from the standby environment, possible configuration problems on the standby instance are not covered.
Prerequisites
Before you perform any testing, you need to isolate your production data.
| Database |
|
|---|---|
| Attachments, apps, and indexes | You need to ensure that no app updates or index backups occur during the test:
|
| Installation folders |
|
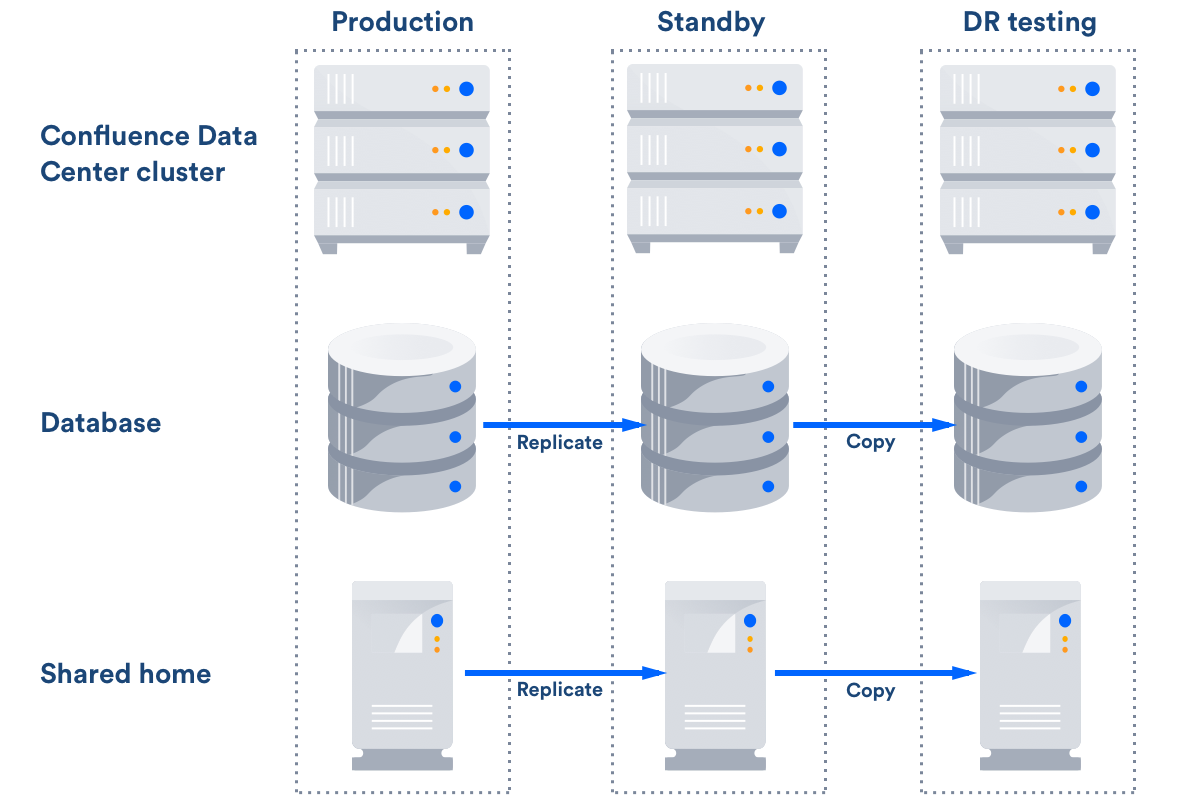
After this you can resume all replication to the standby instance, including the database.
Perform disaster recovery testing
Once you have isolated your production data, follow the steps below to test your disaster recovery plan:
- Ensure that the new database is ready, with the latest snapshot and no replication
- Ensure that the new shared home directory is ready, with the latest snapshot and no replication
- Ensure you have a copy of Confluence on a clean server with the right database and shared home directory settings in
<confluencelocalhome>/confluence.cfg.xml - Ensure you have confluence.home mapped, as it was in the standby instance, in the test server
- Disable email (See
atlassian.mail.senddisabledin Configuring System Properties) - Start Confluence
Handling a failover
In the event your primary site is unavailable, you'll need to fail over to your standby system. The steps are as follows:
- Ensure your live system is shutdown and no longer updating the database
- Ensure the contents of
<confluencesharedhomeis synced to your standby instance> - Perform whatever steps are required to activate your standby database
- Start Confluence on one node in the standby instance
- Wait for Confluence to start and check it is operating as expected
- Start up other Confluence nodes
- Update your DNS, HTTP Proxy, or other front end devices to route traffic to your standby server
Returning to the primary instance
In most cases, you'll want to return to using your primary instance after you've resolved the problems that caused the disaster. This is easiest to achieve if you can schedule a reasonably-sized outage window.
You need to:
- Synchronize your primary database with the state of the secondary
- Synchronize the primary shared home directory with the state of the secondary
Perform the cut over
- Shutdown Confluence on the standby instance
- Ensure the database is synchronized correctly and configured to as required
- Use rsync or a similar utililty to synchronize the shared home directory to the primary server
- Start Confluence
- Check that Confluence is operating as expected
- Update your DNS, HTTP Proxy, or other front end devices to route traffic to your primary server
Other resources
Troubleshooting
If you encounter problems after failing over to your standby instance, check these FAQs for guidance:
Definitions
| RPO | Recovery Point Objective | How up-to-date you require your Confluence instance to be after a failure. |
| RTO | Recovery Time Objective | How quickly you require your standby system to be available after a failure. |
| RCO | Recovery Cost Objective | How much you are willing to spend on your disaster recovery solution. |