DVCS connector can cause abnormal high CPU usage on database server
Platform notice: Server and Data Center only. This article only applies to Atlassian products on the Server and Data Center platforms.
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
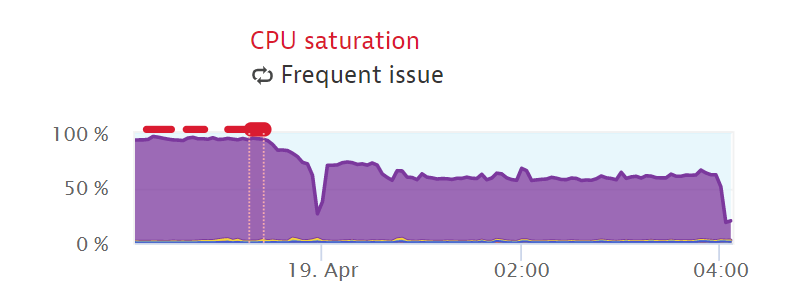
DVCS connector can cause abnormal high CPU on database. If you have DB server monitoring in place, first hint could be seeing very high CPU utilization on the Database server for an elongated period of time:
Environment
Jira Software v8.14.0+ especially when the instance has been upgraded from below 8.14.x
Diagnosis
In general, this issue could first appear as a overall performance issue on Jira data Center where any Database operation might be slow. However, this particular article would apply if you see the following:
- Checking the most expensive queries running during this period on using native DB tools you see this query:
SELECT
COUNT(*)
FROM
AO_E8B6CC_MESSAGE messageMapping
JOIN AO_E8B6CC_MESSAGE_TAG messageTag ON
messageMapping.ID = messageTag.MESSAGE_ID
JOIN AO_E8B6CC_MESSAGE_QUEUE_ITEM messageQueueItem ON
messageMapping.ID = messageQueueItem.MESSAGE_ID
WHERE
messageTag.TAG = 'synchronization-repository-1234'
AND messageQueueItem.STATE IN ( 'PENDING', 'RUNNING', 'SLEEPING' )The expensive query needs to be identified on the DB server and depending on vendor the method to identify would vary. For example:
- For Oracle one could use AWR
- For MySQL you can check the The threads Table
- For Posgres check pg_stat_statements
Cause
When synchronising DVCS repositories, a consumer takes waiting messages for processing. At the end of each message a specific query is run to ensure there are no more messages waiting in DB. When these DB tables are populated with thousands of rows then executing that query becomes very slow.
Here's an example where the the number of rows for each repository grew pretty significantly:
select COUNT(*), TAG from AO_E8B6CC_MESSAGE_TAG Group by TAG ORDER BY COUNT(*) DESC;+----------+----------------------------------+
| COUNT(*) | TAG |
+----------+----------------------------------+
| 5190778 | synchronization-repository-1234 |
| 1255246 | synchronization-repository-5678 |
| 927558 | synchronization-repository-37463 |
| 873410 | synchronization-repository-2365 |
| 349956 | synchronization-repository-8733 |
| 271389 | synchronization-repository-20394 |
| 266690 | synchronization-repository-2358 |
| 265102 | synchronization-repository-3764 |
....Compare the <repoID> of the TAG's viz., synchronization-repository-1234 of the hottest DB query and the largest number of rows of the TAG above with the most number of rows. This should give us a clear idea that we're headed in the right direction.
Solution
Jira's DVCS plugin is a connector type implementation. Jira updates the all the tables AO_E8B6CC_* tables with the information it finds from the DVCS provider e.g., BitBucket, GitHub, GitLab etc. Similarly, the size of these tables viz., AO_E8B6CC_MESSAGE, AO_E8B6CC_MESSAGE_TAG or AO_E8B6CC_MESSAGE_QUEUE_ITEM completely depends on git history of the Organisations and Repositories under them. In large implementations the number of rows of data for each organisation/repository becomes too big to handle quickly by the DB.
We can approach this problem in multiple different ways. It's best to contact Atlassian Support and partner with us in order to analyze the situation and chalk out an action plan. However, We have added the options below in the order that we think should be attempted:
Important Clarification: Choose One Solution at a Time
Each of the following solutions is an independent approach to resolve the issue of prolonged synchronization time and high CPU usage on the database server due to the DVCS connector. It is crucial to choose and implement only one of these solutions based on your specific situation and the characteristics of your Jira instance. Do not perform these solutions sequentially. Assess the impact, feasibility, and potential data loss associated with each solution before proceeding.
Method #1: Force a Full Sync:
Depending on the repository size and complexity a Full Sync can sometimes take days to finish. On top of that REST API Rate Limiting on the DVCS provider viz., GitHub can slow the sync down.
First thing to try would be to force a Full sync for the repository id synchronization-repository-1234:
- Hold the shift key on the sync logo and hit Full sync

We expect a full sync to delete the old data from the DB tables and re-sync them. However, this method might not be optimal when there are millions of rows per repository.
Method #2: Truncate the affected DB Tables:
Please make sure you have the latest DB backup to meet your company RPO and compliance. We should have a last-known-state of the DB that we can come back to in case things don't go as per plan.
We can TRUNCATE those 3 tables AO_E8B6CC_MESSAGE_TAG, AO_E8B6CC_MESSAGE_QUEUE_ITEM and AO_E8B6CC_MESSAGE.
- This would be the fastest but lossy method
- However, this would mean we'll have to run a soft sync for repos that were being synced before, as some Git items (commits/branches/PRs) will not be imported to Jira.
- Please run the following queries in your Jira DB and export the output to a file.
SELECT COUNT(1) FROM "AO_E8B6CC_MESSAGE";SELECT COUNT(1) FROM "AO_E8B6CC_MESSAGE_QUEUE_ITEM";SELECT COUNT(1) FROM "AO_E8B6CC_MESSAGE_TAG";SELECT COUNT(1), "QUEUE", "RETRIES_COUNT", "STATE" FROM "AO_E8B6CC_MESSAGE_QUEUE_ITEM" GROUP BY "QUEUE", "RETRIES_COUNT", "STATE";SELECT COUNT(1), "TAG" FROM "AO_E8B6CC_MESSAGE_TAG" JOIN "AO_E8B6CC_MESSAGE" ON "AO_E8B6CC_MESSAGE"."ID" = "AO_E8B6CC_MESSAGE_TAG"."MESSAGE_ID" GROUP BY "TAG";SELECT count(1), "SYNC_STATUS", "SYNC_TYPE" FROM public."AO_E8B6CC_SYNC_AUDIT_LOG" GROUP BY "SYNC_STATUS", "SYNC_TYPE";EXPLAIN SELECT COUNT(*) FROM "AO_E8B6CC_MESSAGE" messageMapping JOIN "AO_E8B6CC_MESSAGE_TAG" messageTag ON messageMapping."ID" = messageTag."MESSAGE_ID" JOIN "AO_E8B6CC_MESSAGE_QUEUE_ITEM" messageQueueItem ON messageMapping."ID" = messageQueueItem."MESSAGE_ID" WHERE messageTag."TAG" = '' AND messageQueueItem."STATE" in ('PENDING', 'RUNNING', 'SLEEPING');EXPLAIN SELECT COUNT(*) FROM "AO_E8B6CC_MESSAGE" messageMapping JOIN "AO_E8B6CC_MESSAGE_TAG" messageTag ON messageMapping."ID" = messageTag."MESSAGE_ID" JOIN "AO_E8B6CC_MESSAGE_QUEUE_ITEM" messageQueueItem ON messageMapping."ID" = messageQueueItem."MESSAGE_ID" WHERE messageTag."TAG" = (SELECT "TAG" FROM "AO_E8B6CC_MESSAGE_TAG" ORDER BY "TAG" ASC LIMIT 1) AND messageQueueItem."STATE" in ('PENDING', 'RUNNING', 'SLEEPING');EXPLAIN SELECT COUNT(*) FROM "AO_E8B6CC_MESSAGE" messageMapping JOIN "AO_E8B6CC_MESSAGE_TAG" messageTag ON messageMapping."ID" = messageTag."MESSAGE_ID" JOIN "AO_E8B6CC_MESSAGE_QUEUE_ITEM" messageQueueItem ON messageMapping."ID" = messageQueueItem."MESSAGE_ID" WHERE messageQueueItem."STATE" in ('PENDING', 'RUNNING', 'SLEEPING');  Backup the following tables:
Backup the following tables:AO_E8B6CC_MESSAGE_TAG; AO_E8B6CC_MESSAGE_QUEUE_ITEM; AO_E8B6CC_MESSAGE;
- Enable logging one hour before truncating the tables (next step) so we can inspect the current state of Jira. After performing the truncation, leave it enabled for at one hour and then disable.
- TRACE logging for
com.atlassian.jira.plugins.dvcs.service - DEBUG logging for
com.atlassian.jira.plugins.dvcs.sync
- TRACE logging for
Truncate the following tables. This can be done with Jira online.
truncate table AO_E8B6CC_MESSAGE_TAG;truncate table AO_E8B6CC_MESSAGE_QUEUE_ITEM;truncate table AO_E8B6CC_MESSAGE;- If the following feature flags are present in your system, please remove them so we can have the syncs happening again:
dvcs.connector.full-synchronization.disableddvcs.connector.pr-synchronization.disableddvcs.connector.synchronization.disabled
- Do a rolling restart of Jira (one node at the time).
- Manually run soft sync for repos that were being synced before, as some GitHub items (commits/branches/PRs) will not be imported to Jira.
Method #3: Remove the affected Repository(s) and add them back:
- Check in the feature flags dvcs.connector.polling.synchronization.enabled is disabled
- Make sure there's no active sync running for the repository:
If there's a sync currently running for the identified repository, please abort the sync with the following REST API call:
POST <JIRA_BASE_URL>/rest/dvcs-connector-internal/1.0/repository/{id}/abortRunningSync
- Remove the affected repository from the DVCS accounts
- Add the repository back to DVCS
This should remove legacy (pre-v8.14.x) polling webhooks (/rest/bitbucket/1.0/repository/<repository id>/sync) and add new non-polling webhook (/rest/bitbucket/1.0/webhook/dvcs_type).
Jira 8.14 release contains many improvements to existing DVCS functionality like:
Non polling web-hooks
Pagination for the dvcs repository page
Moving some operations to background threads
Gitlab support
However, existing DVCS webhooks do not get upgraded to the Non-Polling webhooks automatically. This was a conscious decision taken by our Development Team in order to reduce potential performance impact. If all repositories auto-upgraded to the new webhook, it would mean all repositories would need a full sync which can sometimes take days.
- Check repository on DVCS provider (viz., GitHub) if new webhooks exists. If yes please check also if old ones are removed.
- If the old webhooks still exist please remove them manually.
Using this query check if number of messages on queue is decreasing (synchronization-repository-1234 id might have changed. use the relevant
<NEW_REPOSITORY_ID>):SELECT COUNT(*) FROM public."AO_E8B6CC_MESSAGE" messageMapping JOIN public."AO_E8B6CC_MESSAGE_TAG" messageTag ON messageMapping."ID" = messageTag."MESSAGE_ID" JOIN public."AO_E8B6CC_MESSAGE_QUEUE_ITEM" messageQueueItem ON messageMapping."ID" = messageQueueItem."MESSAGE_ID" WHERE messageTag."TAG" = 'synchronization-repository-<NEW_REPOSITORY_ID>' AND messageQueueItem."STATE" in ( 'PENDING' , 'RUNNING', 'SLEEPING')- Run full sync on the newly added repo.