Infrastructure recommendations for Enterprise Jira Service Management instances on AWS
On this page
The AWS Quick Start template as a method of deployment is no longer supported by Atlassian. You can still use the template, but we won't maintain or update it.
We recommend deploying your Data Center products on a Kubernetes cluster using our Helm charts for a more efficient and robust infrastructure and operational setup. Learn more about deploying on Kubernetes.
AWS now recommends switching launch configurations, which our AWS Quick Start template uses, to launch templates. We won’t do this switch, however, as we’ve ended our support for the AWS Quick Start template. This means you're no longer able to create launch configurations using this template.
In Jira Data Center size profiles, we presented simple guidelines for finding out if your instance was Small, Medium, Large, or XLarge. We based these size profiles on different Server and Data Center case studies, covering instances of varying infrastructure sizes and configurations. Knowing your load profile is useful for planning for your company's growth, looking for inflated metrics, or simply reviewing your infrastructure's suitability.
As your load grows closer to Large or XLarge, you should routinely evaluate your infrastructure. Once your environment starts to experience performance or stability issues, consider migrating to a clustered (or cluster-ready) infrastructure. When you do, keep in mind that it may not be always clear how to do that effectively – for example, adding more application nodes to a growing Medium-sized instance doesn't always improve performance (in fact, the opposite might happen).
To help you plan your infrastructure set-up or growth, we ran a series of performance tests on typical Medium, Large, and XLarge instances. We designed these tests to get useful, data-driven recommendations for your clustered deployment's application and database nodes. These recommendations can help you plan a suitable clustered environment, one that is adequate for the size of your projected content and traffic.
Newer AWS Compute templates
This article refers to previously tested AWS templates (c5,c4,m4). Similar, certified enterprise-grade templates such as m6i have been run internally against newer versions of Jira but performance and cost-per-hour for newer templates is not quantified on this page.
The recommendations on this page are based on older versions of Jira (8.5).
Performance results depend on many factors such as third-party apps, data, traffic, or instance type. Hence, the performance we achieved might not be replicable to your environment.
Make sure you read through the methodology of our tests to learn the details of these recommendations.
For details on monitoring performance, see Jira Data Center sample deployment and monitoring strategy.
Summary of recommendations
Based on the analysis of the benchmarks and configurations from the tests we’ve run, we came up with the following cost-effective and fault-tolerant recommendations for Jira Large and Jira XL application nodes and database nodes.
Read more about our testing methodology.
Recommendations for best performance and reliability - Jira L
For Large profile customers, we recommend c4.8xlarge 3 nodes for Jira 8.5, which guarantees best performance and fault tolerance. The test results show that having powerful hardware with fewer nodes will provide the most optimal performance.
For Jira 8.13, we recommend c5.9xlarge 3 nodes, which guarantees best performance and fault tolerance. The test results show that having relatively powerful hardware with fewer nodes will provide the most optimal performance.
We also recommend m4.2xlarge (8.13) or m4.4xlarge (8.5) as the minimum database requirement that achieves the desired throughput.
Application nodes | Database node | Apdex | Cost per hour1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.9xlarge x 3 | m4.2xlarge | 0.859 | 4.99 |
| Jira 8.5 | c4.8xlarge x 3 | m4.4xlarge | 0.742 | 7.16 |
Instance details:
- m4.2xlarge = 8 vCPU and 32 GiB RAM
- c4.8xlarge = 36 vCPU and 60 GiB RAM
- c5.9xlarge = 36 vCPU and 72 GiB RAM
- m4.4xlarge = 16 vCPU and 64 GiB RAM
Recommendations for cost-effectiveness and optimal performance - Jira L
For Jira 8.5, the test results show that having powerful hardware with fewer nodes will provide the most optimal performance. The instance type used - c4.8xlarge - has 36 CPUs and 60 GB of RAM. Having two or three nodes of this type ensures good performance at a reasonable cost. We also recommend m4.xlarge as the minimum database requirement that achieves the desired throughput.
For Jira 8.13, the test results show that less powerful hardware provides optimal performance at low cost. The instance type used - c5.2xlarge - has 8 CPUs and 16 GB of RAM. Having 3 or 4 nodes of this type ensures good performance at a reasonable cost. We also recommend m4.xlarge as the minimum database requirement that achieves the desired throughput.
Application nodes | Database node | Apdex | Cost per hour1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.841 | 1.22 |
| Jira 8.5 | c4.8xlarge x 2 | m4.xlarge | 0.742 | 4.97 |
Instance details:
- c4.8xlarge = 36 vCPU and 60 GiB RAM
- c5.2xlarge = 8 vCPU and 16 GiB RAM
- m4.xlarge = 4 vCPU and 16 GiB RAM
Recommendations for best performance and reliability - Jira XLarge
The test results show that having powerful hardware the most optimal performance. Hence, for XLarge profile customers for whom performance takes priority over cost, we recommend c5.9xlarge 6 nodes for Jira 8.5. This number of nodes guarantees best performance, throughput, and fault tolerance. The instance type used (c5.9xlarge) has 36 CPUs and 72 GB of RAM. We also recommend m4.4xlarge as the minimum database requirement that achieves the desired throughput.
For Jira 8.13, we recommend c5.4xlarge 2 nodes. This number of nodes guarantees best performance, throughput, and fault tolerance. The instance type used (c5.4xlarge) has 16 CPUs and 32 GB of RAM. We also recommend m4.4xlarge as the minimum database requirement that achieves the desired throughput.
Application nodes | Database node | Apdex | Cost per hour1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.4xlarge x 2 | m4.4xlarge | 0.918 | 2.16 |
| Jira 8.5 | c5.9xlarge x 6 | m4.4xlarge | 0.803 | 11.51 |
Instance details:
- m4.4xlarge = 16 vCPU and 64 GiB RAM
- c5.9xlarge = 36 vCPU and 72 GiB RAM
- c5.4xlarge = 16 vCPU and 32 GiB RAM
Recommendations for cost-effectiveness and optimal performance - Jira XLarge
Interestingly, for Jira 8.13, c5.2xlarge instance 8 CPUs and 16 GB RAM) at 3 nodes performed only slightly worse than c5.4xlarge still reaching an Apdex higher than 0.70. This behaviour was consistent throughout the tests. Hence, for XLarge profile customers for whom cost effectiveness is key, we recommend c5.2xlarge 3 or 4 nodes, where 4 nodes are preferred for better fault tolerance.
This behavior could also be observed for Jira 8.5, where c5.4xlarge performed nicely in terms of the Apdex and throughput. This is why, if you're considering Jira 8.5, we recommend c5.4xlarge 6 or 7 nodes, where 7 nodes are preferred for better fault tolerance. However, it's worth noting that c5.9xlarge achieved a similar Apdex at 3 nodes, which is only slightly more expensive than the c5.4xlarge.
We recommend m4.xlarge as the minimum database requirement that achieves the desired throughput for Jira 8.5 and Jira 8.13.
Application nodes | Database node | Apdex | Cost per hour1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.905 | 1.22 |
| Jira 8.5 | c5.4xlarge x 6 | m4.xlarge | 0.720 | 4.96 |
Instance details:
- m4.xlarge = 4 vCPU and 16 GiB RAM
- c5.4xlarge = 16 vCPU and 32 GiB RAM
- c5.2xlarge = 8 vCPU and 16 GiB RAM
Cost per hour
1 In our recommendations, we quote a cost per hour to help you compare the relative price of each configuration. We calculate the cost of the entire Jira instance including all subcomponents, such as the application load balancer.
These figures are in US dollars (USD) for Region:Ohio, and were correct as of October 2020.
Approach
We ran all of our tests in AWS (Amazon Web Services) environments. This allowed us to easily define and automate many tests, giving us a large and reliable sample of test results.
Each part of our test infrastructure is a standard AWS component available to all AWS users. This means you can easily deploy our recommended configurations. You can use AWS Quick Starts for deploying Jira Data Center to do so.
Since we used standard AWS components, you can look up their specifications in the AWS documentation. This lets you find equivalent components and configurations if you prefer to use a different cloud platform or bespoke clustered solution.
Considerations
We gathered a large sample of benchmarks for analysis and we designed tests that could be easily set up and replicated. As such, when referencing our benchmarks and recommendations for your infrastructure plans, consider the following:
We didn't install apps on our test instances, as our focus was finding the right configurations for the core product. When designing your infrastructure, you need to account for the performance impact of any apps you want to install.
For the Large test, we used MySQL 5.6.42 with the default settings, except for the maximum number of connections, which was increased to 151 connections.For the XLarge test, we also increased the buffer pool to 40 G and the log file size to 2GB.
Our test environment used a dedicated AWS infrastructure hosted on the same subnet. This helped minimize network latency.
Methodology
Each test run involved applying the same amount of traffic to the same Jira data set, but on a different AWS environment. We ran two series of tests: one to determine optimal configurations for the Jira application node, and the other for the database node.
Test series 1: Our first test series sought to find out which (and how many) AWS virtual machine types to use for the application node.
For the tests on the Large instance, we used a single m4.2xlarge, m4.4xlarge, and m4.xlarge node for the database depending on the Jira version.
For XLarge, we used an m4.4xlarge/m4.xlarge node for the database depending on the Jira version.
Test series 2: Our second test series benchmarked different virtual machine types for the database. Here, we tested different virtual machine types against the two application node configurations that proved best-performing in Test series 1.
For L, these were two and three c4.8xlarge for Jira 8.5 and three c5.2xlarge and c5.9xlarge for Jira 8.13.
For XLarge 8.13, these were three c5.2xlarge and two c5.4xlarge. These application node configurations yielded the highest Apdex. For XLarge 8.5, these were six c5.9xlarge.
To help ensure the reliability of our benchmarks, we tested each configuration two times. We ran the first and second test series on two Long Term Support releases available to us at the time – Jira Data Center 8.13 and Jira Data Center 8.5.
Data set in the Large instance tests
Load profile in the Large instance tests
Data set in the XLarge instance tests
Load profile in the XLarge instance tests
Benchmark
For each test run, we used an Apdex of 0.7 as our threshold for acceptable performance. This Apdex assumes that a 1-second response time is our Tolerating threshold, while anything above 4 seconds is our Frustrated threshold.
Note that the Apdex represented here may not directly match what might be observed in production. The testing environment didn’t have any apps or custom integrations with a consistent peak load, which may be different from your running production instance.
Architecture
We tested each configuration on a freshly-deployed instance of Jira Data Center on AWS.
| Large instance | XLarge instance |
|---|---|
|
|


Configuration details for Jira Large
Configuration details for Jira XLarge
Test details: Large instance
Our first test series sought to find out which (and how many) AWS virtual machine types to use for the application node. For this series of tests, we benchmarked the following virtual machine types for the Jira application node:
c5.2xlarge
c5.4xlarge
c4.8xlarge
c5.18xlarge
We used a single m4.2xlarge, m4.4xlarge or m4.xlarge node for the database, depending on the Jira version.
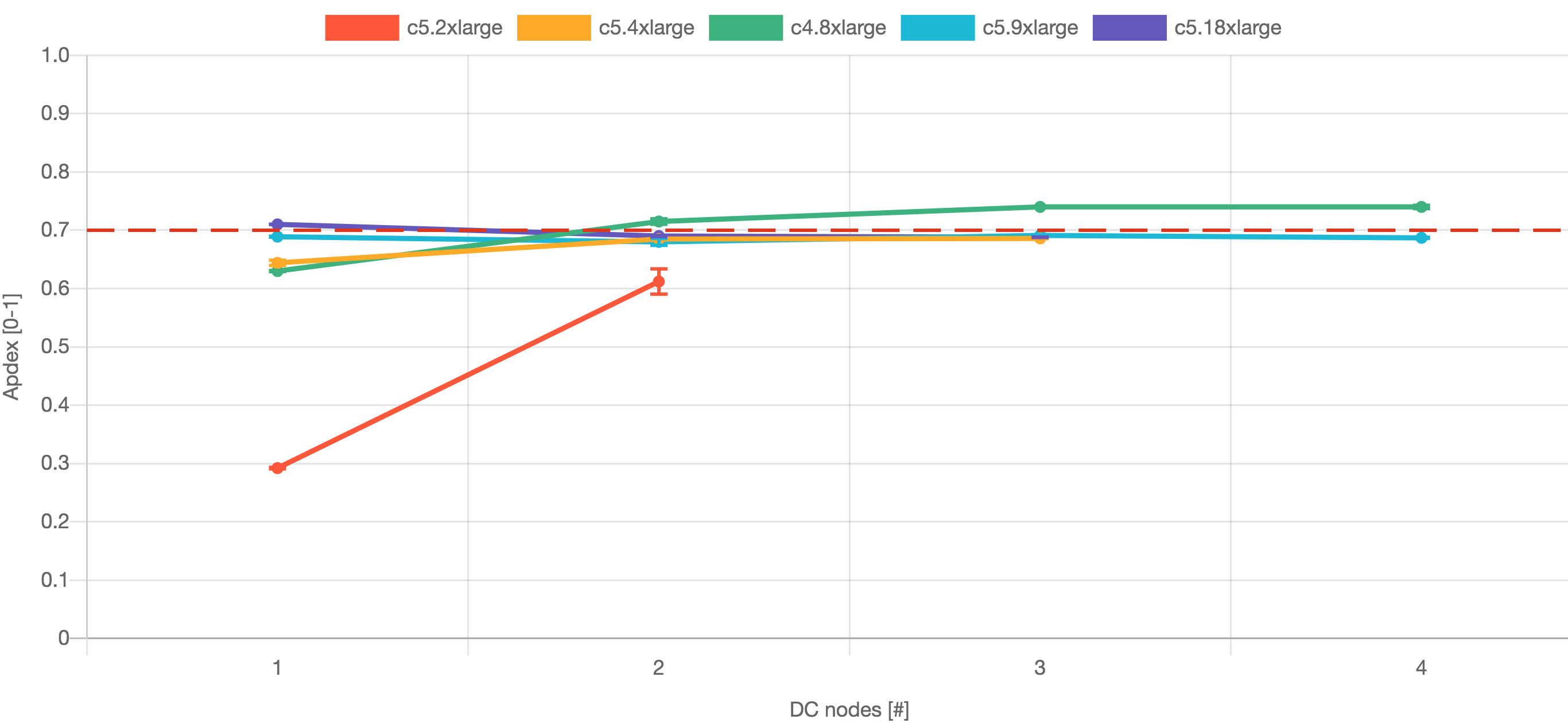
The following graph shows the actual Apdex benchmarks from each test:
| Jira 8.13 – Apdex |
|---|
|

| Jira 8.5 – Apdex |
|---|
|
| Jira 8.13 – throughput |
|---|
|

| Jira 8.5 – throughput |
|---|
|
| Jira 8.13 – how often do users see failed actions? |
|---|
|

| Jira 8.5 – how often do users see failed actions? |
|---|
|
| Jira 8.13 – maximum action error |
|---|
|

| Jira 8.5 – maximum action error |
|---|
|

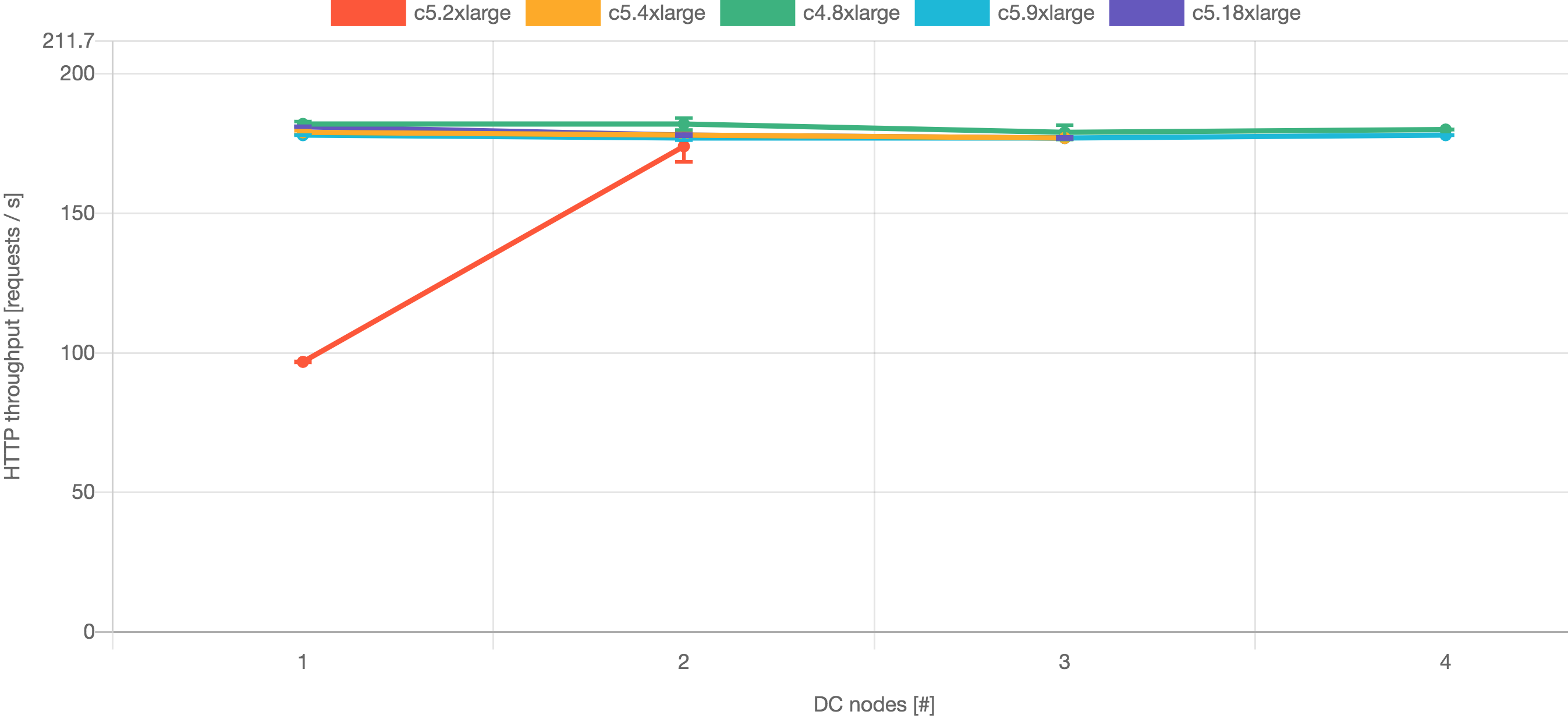
These results show that the best performance for Jira 8.5 came from c4.8xlarge nodes. You'll need at least three nodes for high availability for Jira 8.5. For Jira 8.13 the best performance came from c5.9xlarge nodes. You'll need at least two nodes for high availability for Jira 8.13.
The hardware spec for c4.8xlarge, is 36 CPUs and 60GB RAM. The tests using bigger hardware, c5.18xlarge, showed no performance improvements fro Jira 8.5. Also, no performance improvements were observed by adding additional nodes.
The hardware spec for c5.9xlarge is 36 CPUs and 72 GB RAM. The tests using bigger hardware, c5.18xlarge, showed no performance improvements fro Jira 8.13. Only negligible performance improvement was observed by adding an additional node.
In conclusion, for Large profile customers, we recommend c4.8xlarge 3 or 4 nodes for Jira 8.5 and c5.9xlarge 2 or 3 nodes for Jira 8.13.
See Amazon EC2 C4 Instances for more information about these nodes.
Source: Jira hardware exploration.
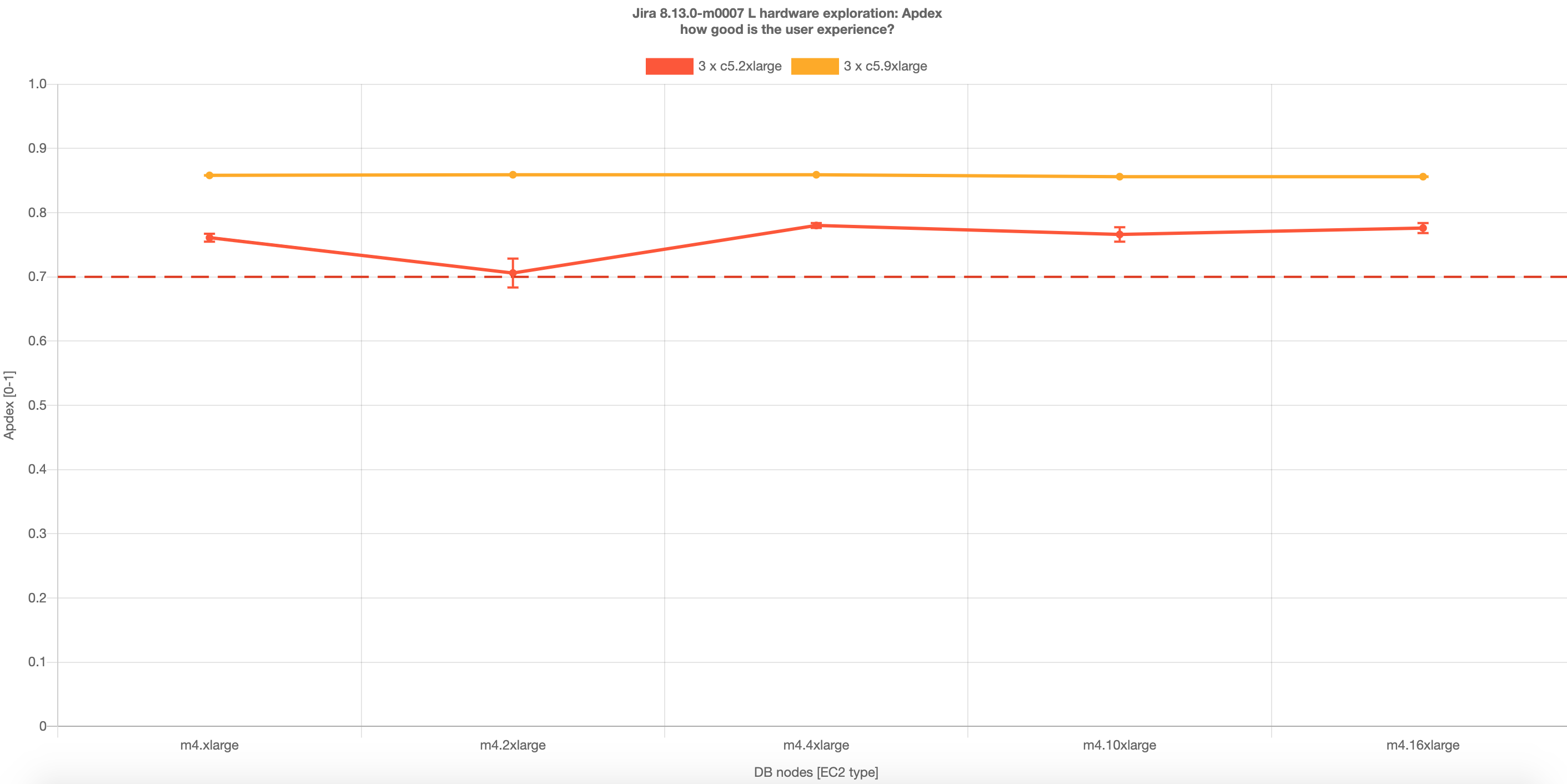
From the series of tests, we determined that when it came to the Jira application node, using c4.8xlarge 3 or 4 nodes provided the best Apdex results. Using this information, we moved on to testing this configuration against the database node.
Here, we benchmarked the following virtual machine types for the database node against both Jira application node configurations:
m4.16xlarge
m4.xlarge
m4.2xlarge
- m4.4xlarge
- m4.10xlarge
| Jira 8.13 – Apex |
|---|
|
| Jira 8.5 – Apdex |
|---|
|

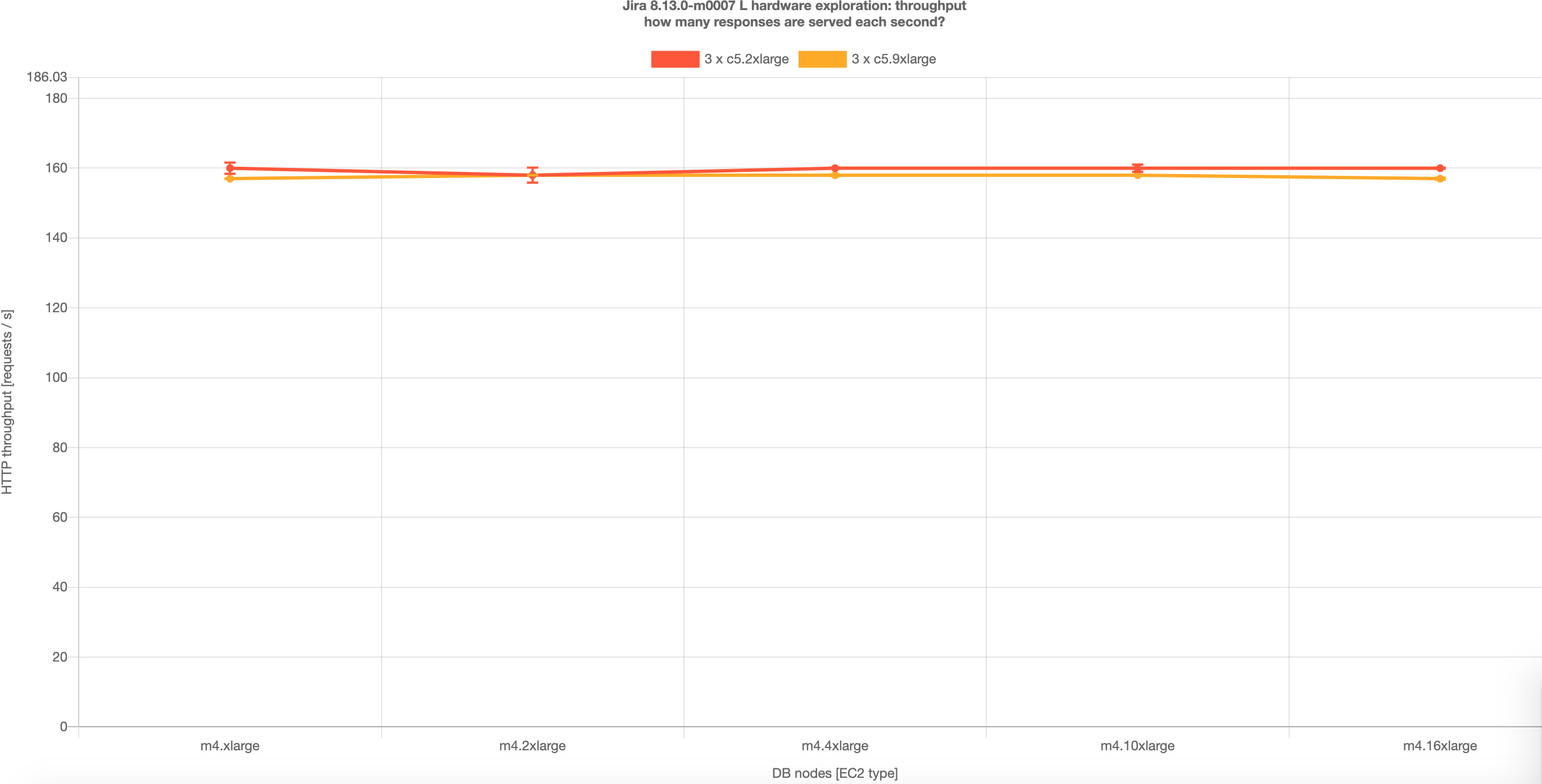
Jira 8.13 – throughput |
|---|
|
| Jira 8.5 – throughput |
|---|
|
| Jira 8.13 – how often do users see failed actions? |
|---|
|
| Jira 8.5 – how often do users see failed actions? |
|---|
|
| Jira 8.13 – max action error |
|---|
|
| Jira 8.5 – max action error |
|---|
|
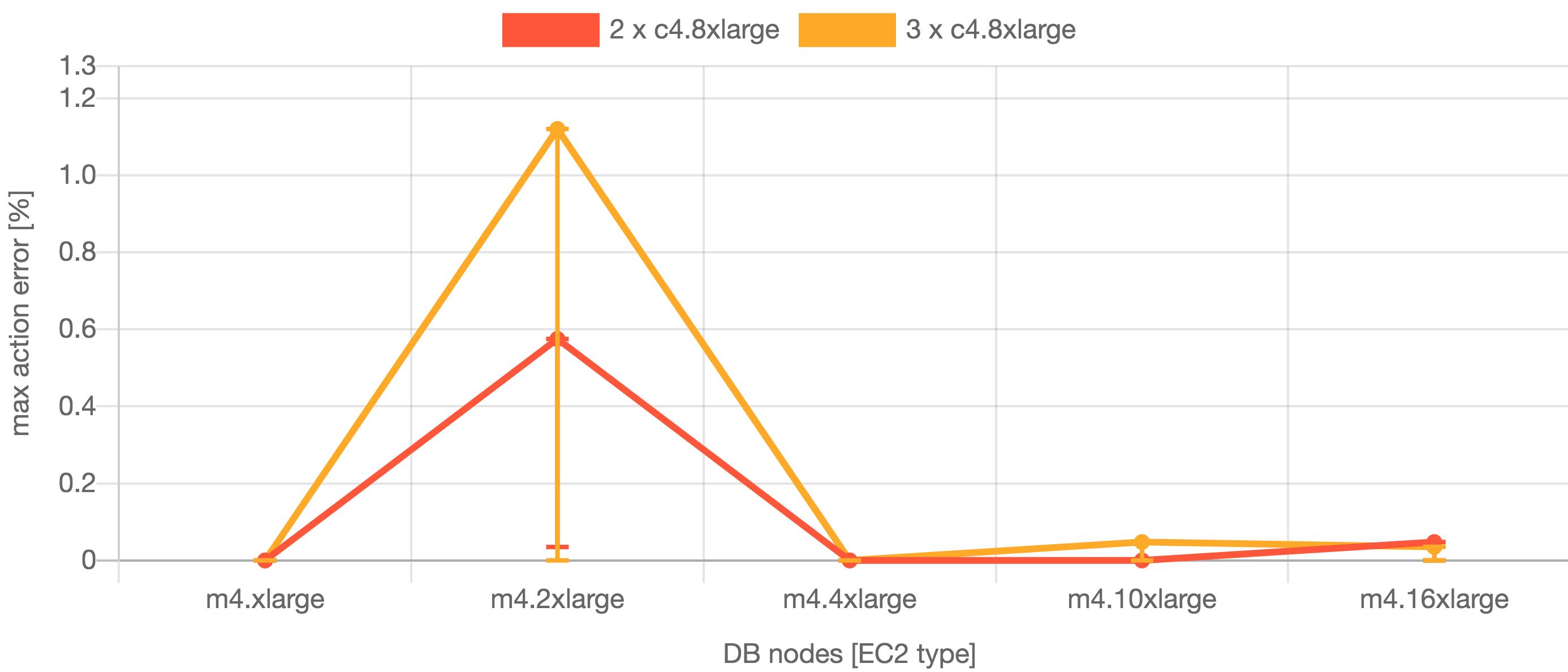
The database connection pool was configured to use the default 20 (minimum and maximum size).
Interestingly, the tests proved that m4.xlarge database produced satisfactory throughput and performance. This suggests that for the Large profile load, we should use m4.xlarge as the minimum database requirement that achieves the desired throughput. However, for better performance m4.4xlarge or m4.2xlarge is recommended.
Source: Jira hardware exploration.
Test details: XLarge instance
Our first test series sought to find out which (and how many) AWS virtual machine types to use for the application node. For this series of tests, we benchmarked the following virtual machine types for the Jira application node:
c5.2xlarge
c5.4xlarge
c4.8xlarge
- c5.9xlarge
c5.18xlarge
We used a single m4.4xlarge node for the database for Jira 8.13. For Jira 8.5 we used m4.xlarge and m4.4xlarge. m4.xlarge was the smallest database to handle the XLarge data set for Jira 8.5.
The following graph shows the actual Apdex benchmarks from each test.
| Jira 8.13 – Apex |
|---|
|

| Jira 8.5 – Apex |
|---|
|

| Jira 8.13 – how often do users see failed actions? |
|---|
|

| Jira 8.5 – how often do users see failed actions? |
|---|
|

| Jira 8.13 – throughput |
|---|
|

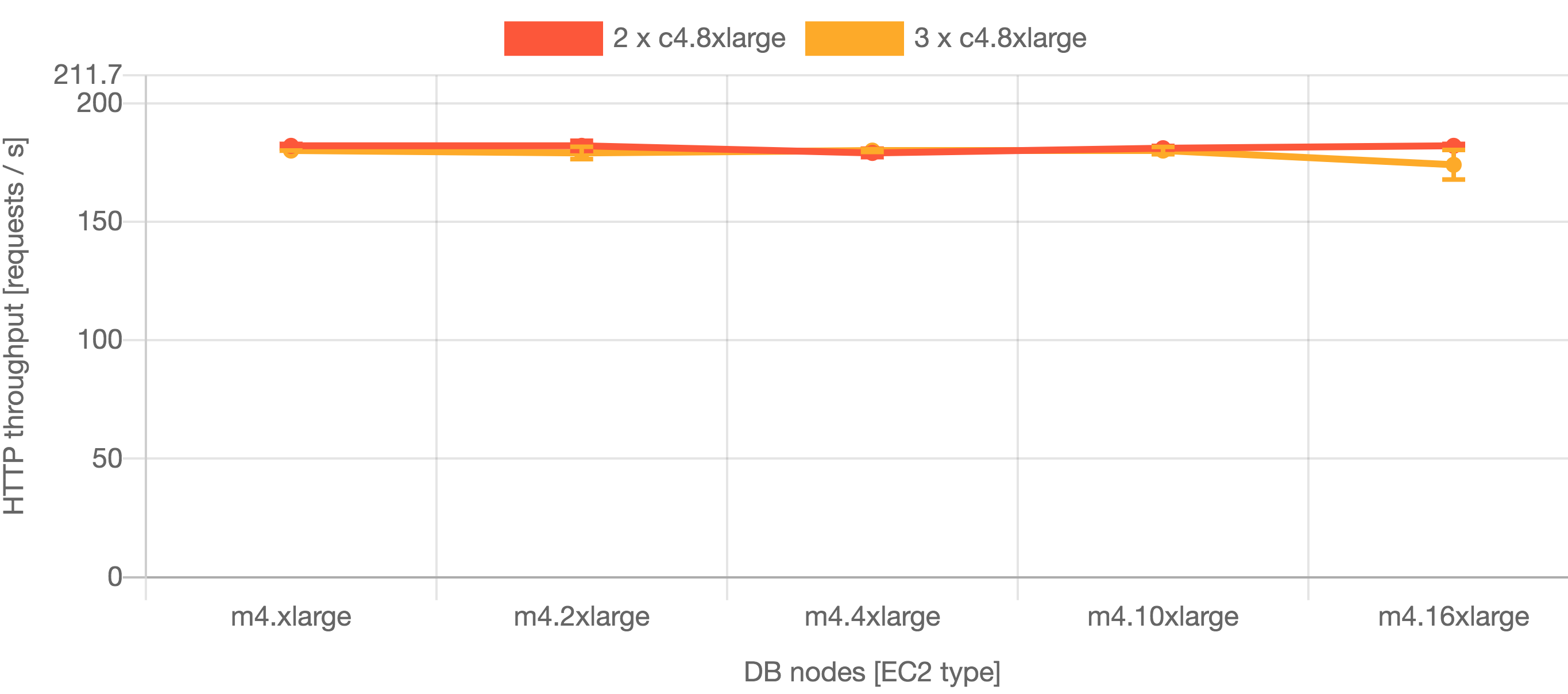
| Jira 8.5 – throughput |
|---|
|

| Jira 8.13 – max error action |
|---|
|

| Jira 8.5 – max error action |
|---|
|

These results show that the best performance came from c5.9xlarge nodes for Jira 8.5 and c5.4xlarge for Jira 8.13 (although the difference between c5.9xlarge and c5.4xlarge was minimal). Based on these results, you need at least three nodes to provide an Apdex over 0.7 for Jira 8.5 and only one for Jira 8.13. Apdex turned out highest at two nodes for Jira 8.13, and and six for Jira 8.5. Additionally, at two nodes for Jira 8.13 and six for Jira 8.5 the instance achieved notable throughput.
It's also noteworthy that for Jira 8.13, 3 c5.2xlarge nodes reached Apdex of 0.905.
The hardware spec for this instance type, c5.9xlarge, is 36 CPUs and 72 GB RAM.
The hardware spec for this instance type, c5.4xlarge, is 16 CPUs and 32 GB RAM.
The hardware spec for this instance type, c5.2xlarge, is 8 CPUs and 16 GB RAM.
For Jira 8.13, the Apdex for a smaller instance, c5.4xlarge reached 0.918 at two nodes, which is only slightly better than the results for c5.9xlarge nodes. Again, at least three nodes are required for HA. The hardware spec for c5.4xlarge is 16 CPUs and 32 GB RAM. For Jira 8.5, c5.4xlarge produced good Apdex at 6 nodes, which is still fairly optimal cost-wise. For this Jira version, c5.9xlarge at 3 nodes produced the same Apdex but slightly worse throughput and this setting is also slightly more expensive.
In conclusion, if cost is no issue, then c5.9xlarge at six nodes for Jira 8.5 and c5.4xlarge at two nodes for Jira 8.13 produces the best performance results.
However, if cost-effectiveness is a concern, then for Jira 8.5 c5.4xlarge at six nodes also seems to be a good option to consider. For Jira 8.13 it's c5.2xlarge at 3 nodes.
See Amazon EC2 C5 Instances for more information about these nodes.
From the series of tests, we determined that when it came to the Jira 8.13 application node, using c5.2xlarge 3 nodes provided the best Apdex results while 2 c5.4xlarge nodes proved to be the most cost-effective option. For Jira 8.5 these were respectively 6 c5.9xlarge and 6 c5.4xlarge. Using this information, we moved on to testing this configuration against the database node.
Here, we benchmarked the following virtual machine types for the database node against both Jira application node configurations:
m4.xlarge
m4.2xlarge
m4.4xlarge
m4.10xlarge
m4.16xlarge
| Jira 8.13 – Apdex |
|---|
|

| Jira 8.5 – Apdex |
|---|
|

| Jira 8.13 – how often do users see failed actions? |
|---|
|

| Jira 8.5 – how often do users see failed actions? |
|---|
|

| Jira 8.13 – throughput |
|---|
|

| Jira 8.5 – throughput |
|---|
|

| Jira 8.13 – max action error |
|---|
|

| Jira 8.5 – max action error |
|---|
|

Recommendations for Large Jira instance
We analyzed the benchmarks and configurations from our Large testing phase and came up with the following recommendations that in our opinion are the most cost-effective and fault-tolerant.
For details behind these recommendations see the Large test phase: application nodes and Large test phase: database nodes sections above.
Recommendations for best performance and reliability
Application nodes | Database node | Apdex | Cost per hour1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.9xlarge x 3 | m4.2xlarge | 0.859 | 4.99 |
| Jira 8.5 | c4.8xlarge x 3 | m4.4xlarge | 0.742 | 7.16 |
Interestingly, c5.18xlarge instances (72 CPUs and 144 GB RAM) performed worse than c4.8xlarge for Jira 8.5 and than c5.9xlarge for Jira 8.13. This behaviour was consistent throughout the tests. For Large profile customers, we recommend c5.9xlarge 3 nodes for Jira 8.13 and c4.8xlarge 3 nodes for 8.5, which guarantees best performance and fault tolerance. We also recommend m4.2xlarge as the minimum database requirement that achieves the desired throughput for Jira 8.13 and for Jira 8.5 this is m4.4xlarge.
Recommendations for cost-effectiveness and optimal performance
Application nodes | Database node | Apdex | Cost per hour1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.841 | 1.22 |
| Jira 8.5 | c4.8xlarge x 2 | m4.xlarge | 0.742 | 4.97 |
For Jira 8.5, the test results show that having powerful hardware with fewer nodes will provide the most optimal performance. The instance type used - c4.8xlarge - has 36 CPUs and 60 GB of RAM. Having 2 or 3 nodes of this type ensures good performance at a reasonable cost. We also recommend m4.xlarge as the minimum database requirement that achieves the desired throughput.
For Jira 8.13, the test results show that less powerful hardware provides optimal performance at low cost. The instance type used - c5.2xlarge - has 8 CPUs and 16 GB of RAM. Having 3 or 4 nodes of this type ensures good performance at a reasonable cost. We also recommend m4.xlarge as the minimum database requirement that achieves the desired throughput.
Recommendation for XLarge Jira instance
We analyzed the benchmarks and configurations from our XLarge testing phase and came up with the following recommendations that in our opinion are the most cost-effective and fault-tolerant.
For details behind these recommendations see the XLarge test phase: application nodes and XLarge test phase: database nodes sections above.
Recommendations for best performance and reliability
The test results show that having powerful hardware the most optimal performance. The instance type used - c5.9xlarge - has 36 CPUs and 72 GB of RAM. Hence, for XLarge profile customers for whom performance takes priority over cost, we recommend c5.9xlarge 6 nodes for Jira 8.5. This number of nodes also guarantees fault tolerance and notable throughput. We also recommend m4.4xlarge as the minimum database requirement that achieves the desired throughput.
For Jira 8.13, we recommend c5.4xlarge 2 nodes. This number of nodes also guarantees fault tolerance and notable throughput. We also recommend m4.4xlarge as the minimum database requirement that achieves the desired throughput. The instance used - c5.4xlarge, is 16 CPUs and 32 GB RAM.
Application nodes | Database node | Apdex | Cost per hour 1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.4xlarge x 2 | m4.4xlarge | 0.918 | 2.16 |
| Jira 8.5 | c5.9xlarge x 6 | m4.4xlarge | 0.803 | 11.51 |
Recommendations for cost-effectiveness and optimal performance
Interestingly, for Jira 8.13, c5.2xlarge instance (8 CPUs and 16 GB RAM) at three nodes performed only slightly worse than c5.4xlarge at two nodes still reaching an Apdex higher than 0.70. This behaviour was consistent throughout the tests. Hence, for Jira 8.13 XLarge profile customers for whom cost effectiveness is key, we recommend c5.2xlarge 3 or 4 nodes, where 4 nodes are preferred for better fault tolerance.
For Jira 8.5, where c5.4xlarge performed nicely at six nodes. This is why, if you're considering Jira 8.5, we recommend c5.4xlarge 6 or 7 nodes, where 7 nodes are preferred for better fault tolerance. However, it's worth noting that c5.9xlarge achieved an Apdex higher than 0.70 at 3 nodes, and this solution is only slightly more expensive than the c5.4xlarge at 6 nodes.
We recommend m4.xlarge as the minimum database requirement that achieves the desired throughput for Jira 8.13 and Jira 8.5.
Application nodes | Database node | Apdex | Cost per hour 1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.905 | 1.22 |
| Jira 8.5 | c5.4xlarge x 6 | m4.xlarge | 0.720 | 4.96 |
Cost per hour
1 In our recommendations, we quote a cost per hour to help you compare the relative price of each configuration. We calculate the cost of the entire Jira instance including all subcomponents, such as the application load balancer.
These figures are in US dollars (USD) for Region:Ohio, and were correct as of October 2020.
Instances we use at Atlassian
The table below shows some in-house production instance, which you can refer to.
Use case | Nodes | AWS application node | Description |
|---|---|---|---|
Jira scale testing | 2 | We use this environment to test loads comparable to Large-sized profile across different Jira versions. Each link on Scaling Jira shows a Jira version's response time to specific user actions compared to previous versions. | |
Public-facing Jira Service Desk instance (getsupport.atlassian.com) | 3 | In Jira Data Center sample deployment and monitoring strategy, we describe two real-life Atlassian-managed Jira Data Center instances. Both are Large-sized instances hosting public-facing Atlassian services. They both feature identical architecture but use different application and database nodes. | |
Public-facing Jira Software instance | 3 |
We're here to help
Over time, we may change our recommendations depending on new tests, insights, or improvements in Jira Data Center. Follow this page in case that happens. Contact an Atlassian Technical Account Manager for more guidance on choosing the right configuration for your Data Center instance.
Our Premier Support team performs health checks by meticulously analyzing your application and logs, to ensure that your infrastructure configuration is suitable for your Data Center application. If the health check process reveals any performance gaps, Premier Support will recommend possible changes.