Deploy Data Center products with the AWS Quick Start template
The AWS Quick Start template as a method of deployment is no longer supported by Atlassian. You can still use the template, but we won't maintain or update it.
We recommend deploying your Data Center products on a Kubernetes cluster using our Helm charts for a more efficient and robust infrastructure and operational setup. Learn more about deploying on Kubernetes.
AWS now recommends switching launch configurations, which our AWS Quick Start template uses, to launch templates. We won’t do this switch, however, as we’ve ended our support for the AWS Quick Start template. This means you're no longer able to create launch configurations using this template.
If you decide to deploy your Data Center instance in a clustered environment, consider using Amazon Web Services (AWS). AWS allows you to scale your deployment elastically by resizing and quickly launching additional nodes, and provides a number of managed services that work out of the box with Data Center products. These services make it easier to configure, manage, and maintain your deployment's clustered infrastructure. Learn more about Data Center
Non-clustered VS clustered environment
A single node is adequate for most small or medium size deployments, unless you need specific features that require clustering (for example high availability or zero-downtime upgrades).
If you have an existing Server installation, you can still use its infrastructure when you upgrade to Data Center. Many features exclusive to Data Center (like SAML single sign-on, self-protection via rate limiting, and CDN support) don't require clustered infrastructure. You can start using these Data Center features by simply upgrading your Server installation’s license.
For more information on whether clustering is right for you, check out Data Center architecture and infrastructure options.
Deploying your Data Center instance in a cluster using the AWS Quick Start
The simplest way to deploy your entire Data Center cluster in AWS is by using the Quick Start. The Quick Start launches, configures, and runs the AWS compute, network, storage, and other services required to deploy a specific workload on AWS, using AWS best practices for security and availability.
The Quick Start provides two deployment options, each with its own template. The first option deploys the Atlassian Standard Infrastructure (ASI) and then provisions either your Data Center product into this ASI. The second option only provisions your Data Center product on an existing ASI.
The ASI is a virtual private cloud (VPC) that contains the components required by all Atlassian Data Center applications. For more information, see Atlassian Standard Infrastructure (ASI) on AWS.
The deployment consists of the following components:
Note that the deployment infrastructure is different for Bitbucket. Check out the details below:
Instances/nodes: One or more Amazon Elastic Cloud (EC2) instances as cluster nodes, running your Data Center instance.
Load balancer: An Application Load Balancer (ALB), which works both as a load balancer and SSL-terminating reverse proxy.
Amazon EFS: A shared file system for storing artifacts in a common location, accessible to multiple nodes. The Quick Start architecture implements the shared file system using the highly available Amazon Elastic File System (Amazon EFS) service.
Database: Your choice of shared database instance—Amazon RDS or Amazon Aurora.
Amazon CloudWatch: Basic monitoring and centralized logging through Amazon's native CloudWatch service.
Confluence will use the Java Runtime Engine (JRE) that is bundled with Confluence (/opt/atlassian/confluence/jre/), and not the JRE that is installed on the EC2 instances (/usr/lib/jvm/jre/).
Learn more about Jira products on AWS, Confluence on AWS, Bitbucket on AWS, and Crowd on AWS.
Advanced customizations
To get you up and running as quickly as possible, the Quick Start doesn't allow the same level of customization as a manual installation. You can, however, further customize your deployment through the variables in the Ansible playbooks we use.
All of our AWS Quick Starts use Ansible playbooks to configure specific components of your deployment. These playbooks are available publicly on this repository: https://bitbucket.org/atlassian/dc-deployments-automation.
You can override these configurations by using Ansible variables. Refer to the repository’s README file for more information.
Note about customization in Jira
Jira allows you to apply advanced settings through the jira-config.properties file. You can also use the same file to apply the same settings to an existing Quick Start deployment. Learn how to customize the jira-config.properties file
Launching the Quick Start from your own S3 bucket (recommended)
The fastest way to launch the Quick Start is directly from its AWS S3 bucket. However, when you do, any updates we make to the Quick Start templates will propagate directly to your deployment. These updates sometimes involve adding or removing parameters from the templates. This could introduce unexpected (and possibly breaking) changes to your deployment.
For production environments, we recommend that you copy the Quick Start templates into your own S3 bucket. Then, launch them directly from there. Doing this gives you control over when to propagate Quick Start updates to your deployment.
To launch the Quick Start:
Amazon Aurora database for high availability
The Quick Start also allows you to deploy your Data Center instance with an Amazon Aurora clustered database (instead of RDS).
This cluster will be PostgreSQL-compatible, featuring a primary database writer that replicates to two database readers. You can also set up the writers and readers in separate availability zones for better resiliency.
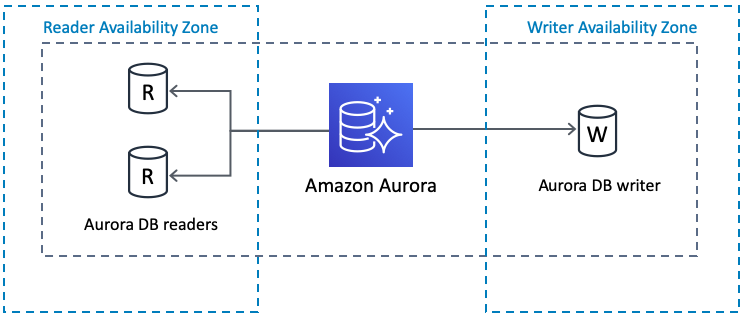
If the writer fails, Aurora automatically promotes one of the readers to take its place. For more information, see Amazon Aurora Features: PostgreSQL-Compatible Edition.
Amazon Aurora clustered databases are supported by:
Amazon CloudWatch for basic monitoring and centralized logging
The Quick Start can also provide you with node monitoring through Amazon CloudWatch. This will allow you to track each node's CPU, disk, and network activity, all from a pre-configured CloudWatch dashboard. The dashboard will be configured to display the latest log output, and you can customize the dashboard later on with additional monitoring and metrics.
By default, Amazon CloudWatch will also collect and store logs from each node into a single, central source. This centralized logging allows you to search and analyze your deployment's log data more easily and effectively. See Analyzing Log Data with CloudWatch Logs Insights and Search Log Data Using Filter Patterns for more information.
Auto Scaling groups
This Quick Start uses Auto Scaling groups, but only to statically control the number of its cluster nodes. We don't recommend that you use Auto Scaling to dynamically scale the size of your cluster. Adding an application node to the cluster usually takes more than 20 minutes, which isn't fast enough to address sudden load spikes.
If you can identify any periods of high and low load, you can schedule the application node cluster to scale accordingly. See Scheduled Scaling for Amazon EC2 Auto Scaling for more information. To study trends in your organization's load, you'll need to monitor the performance of your deployment.
Customizing the AWS Quick Start's CloudFormation templates
To get you up and running as quickly as possible, the Quick Start doesn't allow the same level of customization as a manual installation. Alternatively, you can customize the CloudFormation templates used by the Quick Start to fit your needs. These templates are available from the following repository:
Supported AWS regions
Not all regions offer the services required to run Data Center products. You'll need to choose a region that supports Amazon Elastic File System (EFS). These regions are:
Americas
Northern Virginia
Ohio
Oregon
Northern California
Montreal
Europe/Middle East/Africa
Ireland
Frankfurt
London
Paris
Asia Pacific
Singapore
Tokyo
Sydney
Seoul
Mumbai
This list was last updated on June 20, 2019.
The services offered in each region change from time to time. If your preferred region isn't on this list, check the Regional Product Services table in the AWS documentation to see if it already supports EFS.