Confluence Indexing Troubleshooting Guide
Platform notice: Server and Data Center only. This article only applies to Atlassian products on the Server and Data Center platforms.
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Confluence Data Center and server indexing is used by search, dashboard, some macros, user mentions and other places in confluence where information about your content or reference to content are required. Confluence Data Center and server index is running on Apache Lucene engine and is made up of:
- a content index which contains content such as the text of pages, blog posts, and comments
- a change index which contains data about each change, such as when a page was last edited.

Index Troubleshooting Flowchart
The following flowchart should be used when dealing with unknown Indexing issues as an aid in determining the cause of a problem.
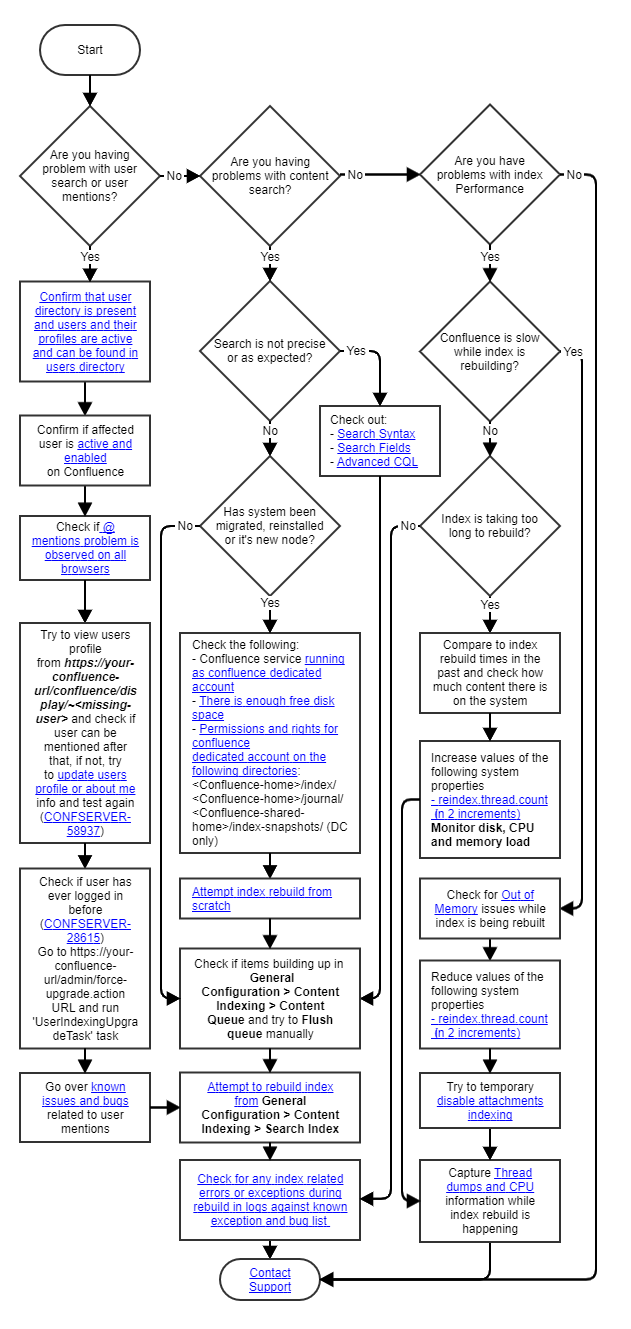
Terminology
- "Index Rebuild" or "re-indexing" refers to action of rebuilding index from
 > General Configuration > Content Indexing using existing index files
> General Configuration > Content Indexing using existing index files - "Index Rebuild from scratch" refers to action of deleting existing index files from file system and building new index using new files
- "Index Building" or "indexing" refers to day to day operations of confluence of building and maintaining index of existing and new content
User Mentions, profiles and Indexing
There are a few known issues that result in users not getting indexed after being added, most can be addressed by one of the actions outlined in Unable to @ mention certain users in Confluence KB:
Go to <your-confluence-url>/confluence/display/~<missing-user> to view users profile
Go to <your-confluence-url>/admin/force-upgrade.action URL and run 'UserIndexingUpgradeTask' task
Go to <your-confluence-url>/confluence/admin/users/edituser.action?username=<missing-user> and update their about me or any other info
- Go to > General Configuration > Content Indexing and rebuild index from there as very new users might simply haven't been indexed yet
- Attempt to rebuild index from scratch if possible, most issues can be solved this way
Browsers local storage or cache also plays role in user mentions, as it stores people you mention frequently for faster results, so testing on different browsers is important.
Useful KB articles
Content indexing, search and macros
Rebuilding, Logging and Internals
Index and Confluence search are dependent on content permissions, when you search Confluence for specific keyword, entire confluence index is searched and restrictions are applied on the results based on permissions on content, so problems with ancestor tables will have impact on index and index rebuild, so do check for them when facing rebuild problems
Although most errors and warnings related to indexing normally get logged, sometimes enabling debug logging and looking at what was logged during search or index building or rebuilding is very helpful to investigation.
Debug logging:
From Administration >> Logging and Profiling, add the following packages, and set to DEBUG:
com.atlassian.confluence.internal.index.AbstractBatchIndexer
com.atlassian.confluence.search.lucene
com.atlassian.bonnie.search.extractorRefer to Enabling Debug classes for Indexing Troubleshooting KB for details
Starting with Confluence 7.11 indexing related log entries and debug logging will go into their dedicated atlassian-confluence-index.log file.
Prior to Confluence 7.11, log entries will be logged in atlassian-confluence.log
Indexing Jobs and DB
Indexing queue is where all the new and updated content are added to be indexed and can be seen from Administration > Content Indexing > Queue Contents.
It is likely that the Queue Content list will appear empty as Flush Edge Index Queue job is running every 30 second to process those requests, so by the time you check, entries might have already have been processed.
All records to be indexed are also stored inside JOURNALENTRY DB table and each Confluence node or server instance will have a record of last processed entry kept inside <confluence-home>/journal/main_index file. Checking last records inside JOURNALENTRY DB table and comparing them to <confluence-home>/journal/main_index file is a good way to determine which content index job has already processed.
Besides Flush Edge Index Queue job there is also Clean Journal Entries job running once a day, that will cleanup JOURNALENTRY DB table out of entries older than 2 days, so if index job was not properly running for a few days on a node or server instance, it's possible that last indexed entry recorded in main_index file is no longer stored on JOURNALENTRY DB table, if that is the case, index needs to be rebuild.
Index Rebuilding task launches up to 6 threads named "Indexer: <n>". Any errors during this task will be logged by one of those threads.
For example, from Indexer stops with ERROR java.io.IOException: No space left on device KB:
ERROR [Indexer: 1] [internal.index.lucene.LuceneBatchIndexer] doIndex Exception indexing document with id: 12345678
│java.io.IOException: No space left on device Building of index is carried out by Flush Edge Index Queue job which will be handled by Confluence job scheduler, so any related errors or warning occurring during those jobs will typically be logged under "scheduler_Worker-<n>" thread and you would need to look into into message itself to determine the nature of Warning/Error as seen in example from the same KB:
ERROR [scheduler_Worker-10] [org.quartz.core.ErrorLogger] schedulerError Job (DEFAULT.IndexQueueFlusher threw an exception.
org.quartz.SchedulerException: Job threw an unhandled exception. [See nested exception: com.atlassian.bonnie.LuceneException: com.atlassian.confluence.api.service.exceptions.ServiceException: Failed to process entries]
WARN [scheduler_Worker-10] [search.lucene.tasks.AddDocumentIndexTask] perform Error getting document from searchable
java.io.IOException: No space left on device
WARN [scheduler_Worker-1] [search.lucene.tasks.AddDocumentIndexTask] perform Error getting document from searchable
java.io.FileNotFoundException: /opt/confluence/confluence-home/index/_z8ey.fdx (No space left on device) Viewing Index
In some rare situations you might need to check out what is being stored in Lucene index itself, for example, as part of debugging to verify that certain piece of content actually got indexed. You can refer to this guide on ways to do it. ![]() Index issues or corruption can't be fixed from within and rebuilding corrupt index is best and safest option.
Index issues or corruption can't be fixed from within and rebuilding corrupt index is best and safest option.
Performance and Indexing
Confluence Performance Problems
If Confluence is facing performance problems during index rebuild operations, below are some of the things you should check:
- Check if Confluence Node or instance are facing Out of Memory condition, if yes, then follow Fix java.lang.OutOfMemoryError in Confluence KB to address them
- Try to rebuild index from scratch (if not already done it) as corrupt index can add extra load
- Try to temporarily reduce the number of threads Confluence uses by setting reindex.thread.count system property to 4
- If above steps don't produce desired outcome, gather thread dumps and CPU information for Atlassian Support while index rebuild is happening, preferably, after a bit of time has passed from starting the process.
Attachments
Confluence will attempt to extract text from attachments and build index for searchability, depending on what you want to accomplish there are several KBs that cover this feature and potential issues with it.
- How to disable indexing of attachments
- How to Change the Number of Threads Used for Attachment Reindexing
- Confluence reindexing becomes stuck
- Document Contents Are Not Searchable
- Configuring Attachment Size
Optimizing Index with System properties
If you wish for rebuilding index task to complete faster or if day to day index building is not keeping up with newly generate content rate, below parameters might help.![]() Try to focus on one parameter at a time to keep track of changes and control system load.
Try to focus on one parameter at a time to keep track of changes and control system load.
- Set (6) and increase -Dreindex.thread.count system property in steady increments (2) and monitor your Disk, CPU and Memory loads during re-indexing operations
Above parameter will determine how many threads Lucene can open for index rebuild task, useful for trying to improve index rebuild completion time.
- Set (6) and increase -Dreindex.attachments.thread.count system property in steady increments (2) and monitor your Disk, CPU and Memory loads during re-indexing operations
Above parameter will determine how many threads Lucene can open for attachments indexing rebuild, useful for trying to improve index rebuild completion time in systems with a lot of attachments.
- Set (1500) and increase -Dindex.queue.batch.size system property in steady increments (500) and monitor your Disk, CPU and Memory loads during normal operations
Above parameter will determine how many items will be processed by Flush Edge Index Queue job each time, useful if your system is generating a lot of content, and Lucene can't keep up resulting in Queue building up steadily. Can be enabled temporary during migrations or anticipated mass content generation activities.