Upgrade from Crowd Server to Crowd Data Center
If you're a current Crowd Server customer looking to upgrade to Crowd Data Center, this page will help you create a free trial license and set up Data Center. There are several ways to get started with Crowd Data Center, depending on your current setup.
If you have no existing Crowd Server data to migrate, check out how to install Crowd Data Center.
Before you begin
Before you install Crowd Data Center, take a look at the specifics below.
What is Crowd Data Center? | |
| How do I get it? | |
What are the prerequisites? | |
| Do I need a load balancer? |
1. Enable Crowd Data Center on your existing Crowd Server instance
Crowd Data Center is available for Crowd 3.0 and later. If you're not on this version yet, install or upgrade your Crowd instance. See Crowd installation and upgrade guide.
License
It’s your Crowd license that determines the type of Crowd you have: Server or Data Center. Crowd will auto-detect the license type when you enter your license key, and automatically unlock any license-specific features.
To upgrade from Crowd Server to Crowd Data Center, you will need a Data Center license. You can either purchase a full Data Center license or get a free trial license for 30 days. When your 30-day trial finishes, you’ll have the option to purchase a Data Center license and carry on using Crowd Data Center without losing any data you’ve created during the trial. If you decide Crowd Data Center is not for you, you can easily revert to your existing Server license.
Upgrade your Crowd license
To upgrade from Crowd Server to Crowd Data Center:
Go to Administration
 > Licensing to enter your license key. Once successful, you should see that Data Center is now available but you need to restart Crowd before you can start using it.
> Licensing to enter your license key. Once successful, you should see that Data Center is now available but you need to restart Crowd before you can start using it.Stop Crowd now. Before restarting, you will need to set up the shared home directory.
2. Set up the shared directory
Crowd Data Center requires that the <CROWD HOME>/shared directory can be read and written by all the machines running Crowd Data Center.
When installing Crowd Server <CROWD HOME>/shared is created as a normal directory. To use Crowd Data Center:
- Stop Crowd.
- Backup your Crowd home directory before making any changes.
Prepare a shared, network-accessible directory.
For this example we will assume the you are using Linux, and the shared directory is available at
/mnt/nfs/crowdMove
<CROWD HOME>/sharedto the shared directory you've prepared:mv <CROWD_HOME>/shared /mnt/nfs/crowdMount or create a symbolic link at
<CROWD_HOME>/sharedthat points to the copied directory:ln -s /mnt/nfs/crowd/shared <CROWD_HOME>/shared- Check if
<CROWD_HOME>/shared/crowd.cfg.xmlexists and is accessible from the machine running Crowd to verify you have configured the directory correctly. - Start Crowd again.
3. Add the first Crowd node to your load balancer
Before you begin
You must enable clustering in Crowd first. To do that, in your shared directory edit the crowd.cfg.xml file and set the crowd.clustering.enabled property to true and restart Crowd.
The load balancer distributes the traffic between the nodes. If a node stops working, the remaining nodes will take over its workload, and your users won't even notice it.
- First, add your load balancer as a trusted proxy server in Crowd. See Configuring Trusted Proxy Servers.
Add the first node to the load balancer.
- Restart the node, and then try opening different pages in Crowd. If the load balancer is working properly, you should have no problems with accessing Crowd.
In Crowd, go to
 > Clustering. The node should be listed as part of the cluster.
> Clustering. The node should be listed as part of the cluster. 
If your load balancer supports health checks, configure it to perform a check on
http://<crowd-node>:8095/<context-path>/status, where<crowd-node>is the node's hostname or IP address, and<context-path>is the Crowd's context path (e.g./crowd). If the node doesn't respond with a200 OKresponse within a reasonable time, the load balancer shouldn't direct any traffic to this node.- After you've added the node to the load balancer, configure the Crowd's base URL to also point to the load balancer. Go to > General, and enter the URL of your load balancer as Base URL.

4. Add the remaining nodes to the cluster
- Copy the Crowd installation directory to the new node.
- Create a home directory, like you did for the first node, and mount
sharedas its sub-directory. Edit
crowd-init.properties, and enter the path to the home directory that you just created.- Go to
<installation-directory>/apache-tomcat/conf/Catalina/localhost, and delete theopenidserver.xmlfile. This is needed because currently the CrowdID component doesn't support clustering, and it must be enabled only on the first node. The component will work as usual. - Start Crowd. It will read the configuration from the shared directory, and start without any extra setup.
- Take a look around the new Crowd instance. Verify that user and group management, directory synchronization, and any custom integrations all work as expected.
- Again, verify that the node was added to the cluster. In Crowd, go to
 > Clustering.
> Clustering.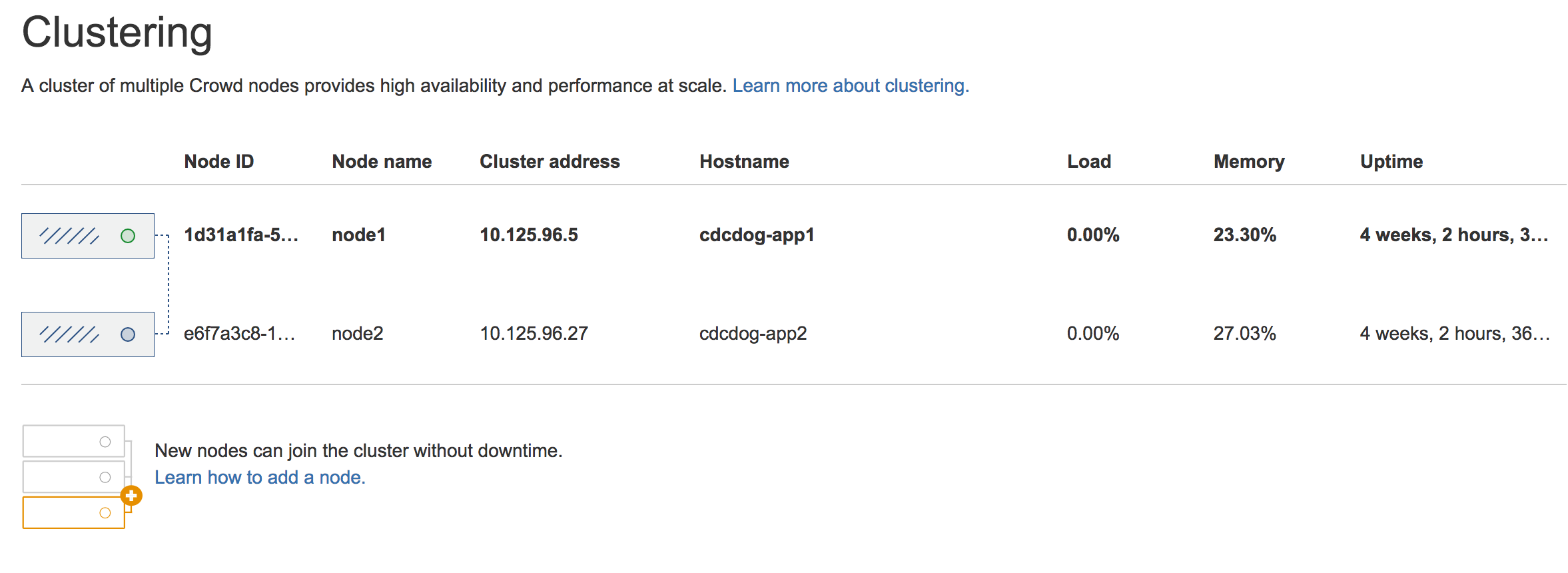
If everything looks fine, you can configure your load balancer to start routing traffic to the new node. Once you do this, you can make a couple of changes in one Crowd instance to see if they're visible in other instances as well.
What else?
Adding node names
When displaying information about your nodes in the Crowd footer or on the ![]() > Clustering page, Crowd Data Center uses random IDs that were generated for your nodes. Instead, you can give them more persistent and readable names by setting the
> Clustering page, Crowd Data Center uses random IDs that were generated for your nodes. Instead, you can give them more persistent and readable names by setting the cluster.node.name system property, like in the following example:
CATALINA_OPTS=-Dcluster.node.name=node-1