Bitbucket Data Center sample deployment and monitoring strategy
At Atlassian, we use several enterprise-scale development tools. Among them is a Bitbucket Data Center instance deployed specifically to meet the global source code management needs of around 6,500 users, and support up to 900,000 monthly builds. During peak load times, the instance can process up to 300 builds per minute.
How we use Bitbucket
This Bitbucket Data Center instance creates a single point of integration for many Atlassian applications, making it easier for a large number of users to consolidate their source control needs with other teams. As of February 2018, this instance hosts approximately 6,500 repositories across 2,500 projects.
High availability is the top monitoring priority of this instance, given the global dependence of so many users on it. At the same time, the instance needs to continuously perform at a healthy level; otherwise, it will start to affect Git-related operations in other integrated applications. This would affect productivity throughout the organization, along with our ability to ship software on time – especially since any slowdown here affects the performance of any integrated Bamboo build servers.
Infrastructure and setup
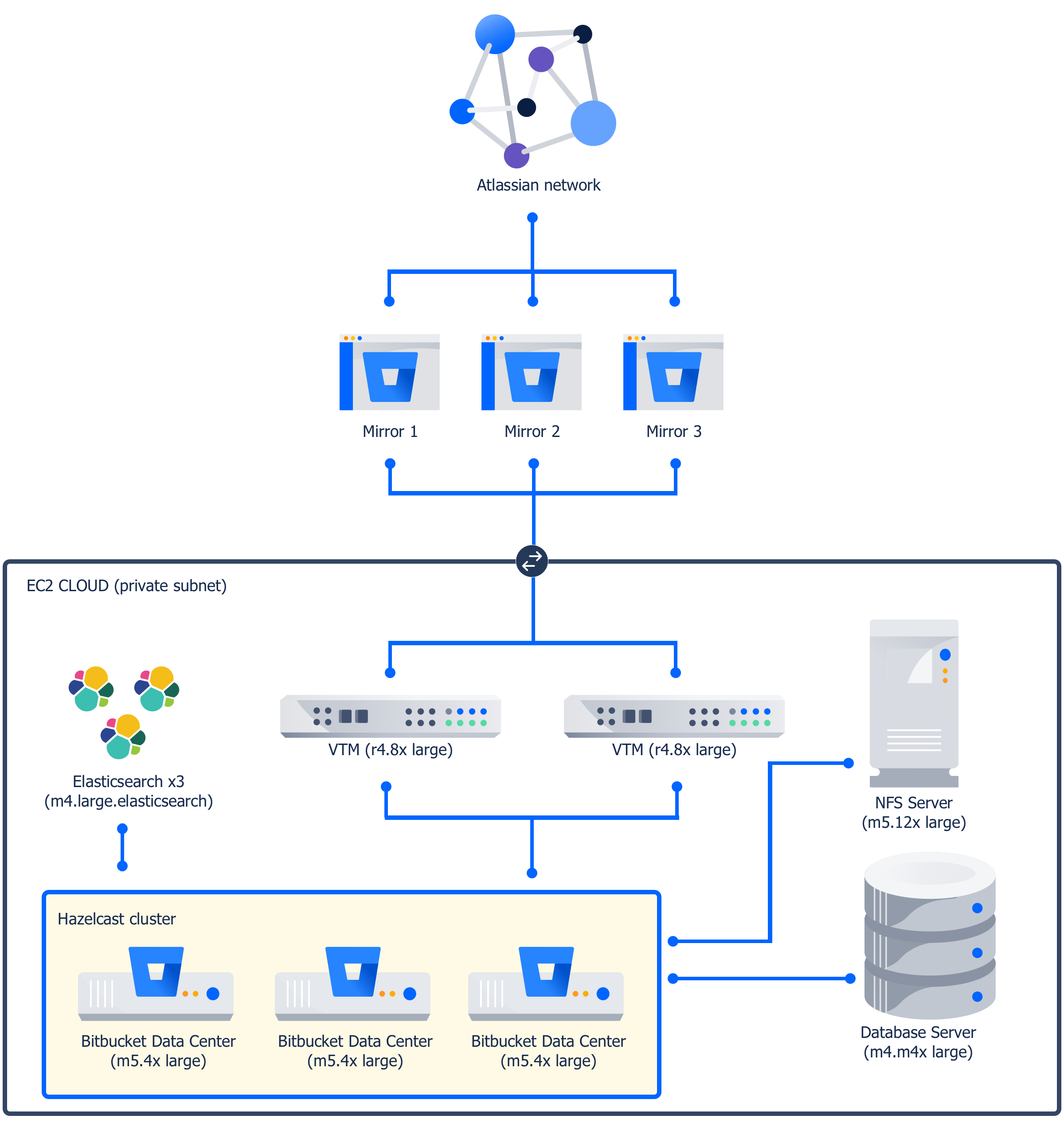
Our Bitbucket Data Center instance is hosted on an EC2 cloud on Amazon Web Services (AWS), composed of the following nodes:
| Function | Instance type | Number |
|---|---|---|
| Bitbucket Data Center application | m5.4xlarge | 3 |
| Dedicated NFS server | m5.12xlarge | 1 |
| Dedicated database (Amazon RDS Postgresql) | m4.2xlarge | 1 |
| Virtual Traffic Manager | r4.8xlarge | 2 |
| Elasticsearch instances | m4.large.elasticsearch | 3 |
We use the AWS EC2 discovery plugin for Hazelcast to discover nodes within our EC2 Cloud. Three mirrors help manage traffic across regions where the majority of users are located.
Instead of an actual load balancer, we use a proprietary Virtual Traffic Manager, hosted on two instances suitable for handling the bandwidth we need. We use a dedicated NFS server to provide plenty of RAM for page caching.
For details on each node type, read AWS documentation on Instance Types (specifically, General Purpose Instances and Memory-Optimized Instances.
For more information on Elasticsearch instances, read Amazon Elasticsearch Service.
Integrated services
Our Bitbucket Data Center instance uses Crowd to manage its user directory, and is also integrated with several other Atlassian products. These include the following public Jira services:
- http://getsupport.atlassian.com/
- http://jira.atlassian.com/
- https://www.atlassian.com/software/jira/service-desk
In total, our Bitbucket Data Center instance is linked to the following mix of applications:
21 x Bamboo links
10 x JIRA links
3 x Confluence links
2 x FishEye / Crucible
This instance also has 30 apps installed and enabled.
Monitoring strategy
Our monitoring strategy focuses on ensuring that the instance has enough resources to handle its load. This typically involves quickly addressing bottlenecks around Git-related operations, whether that means adding more node resources, performing a rolling restart, or any other appropriate fix. This is not just to keep source control robust throughout the instance, but to help prevent any slowdown from cascading to integrated services that depend on source control.
For the most part, this means ensuring that the instance has a healthy performance rate; keeping this level of performance means the instance is far from any critical failures. In our experience, most of these failures start to manifest themselves as hosting ticket queues, so we set an alert for this (see General load).
We also monitor for events that signal an impending split-brain scenario. Specifically, we monitor the number of Hazelcast remote operations and alert against historically critical levels (see Node for details).
The following tables provide further details on how we monitor each subsystem of the instance, our alert levels (if any), and what we do if any alerts are triggered. These strategies are specific to our setup, scale, and use case.
General load
| Metric we track | Alerting level | What we do when alert is triggered |
|---|---|---|
Hosting tickets. Bitbucket uses tickets to help prevent the system from being overloaded with requests. Hosting tickets limit the number of source control management (SCM) hosting operations which may be running concurrently. GIT pushes and pulls over HTTP or SSH make up SCM hosting operations. | Hosting tickets queued for 5 minutes. As in, an alert is triggered when there have been tickets on the hosting tickets queue for 5 minutes straight. This usually means that either the load is too high or the instance is not processing tickets quickly enough. | We check whether queueing is caused by high load or a slow instance. If it's the former, we increase the resources available to the instance (see Bitbucket Server is reaching resource limits for related details). If the instance is slow, we investigate other subsystems (JVM, the nodes, Git processes, or database) to determine a root cause. |
| Number of active database connections. This metric helps indicate whether there is a bottleneck in the service. | 50 or more active database connections (per node) throughout a 5-minute period. Using past performance data, we determined that this alert is the upper limit at which the instance can still gracefully recover from. Most incidents start to occur beyond the 5-minute mark. | When alerted, we investigate other metrics for any imminent issues. In most cases, the instance will simply self-correct over time. On rare occasions, we discovered issues in other subsystems that sometimes resulted in the need for a rolling restart. As a matter of policy, we upgrade to the most recent version as soon as possible. This allows us to take advantage of stability improvements in each release. Because of this, the risk of outages or instability drops over time. |
Thread pool length. Specifically, we monitor the length of the following Bitbucket server threadpools: IoPumpThreadPool, ScheduledThreadPool, and EventThreadPool. We've seen misbehaving apps on the Bitbucket instances of customers perform long-running tasks on threadpools, which can affect the service. | Queue length exceeds 40 throughout a 5-minute period. We studied the queue lengths of related customer cases, and formed this alert based on them. | If this alert is triggered, we plan to first check all apps for any signs of trouble. If none are problematic, we check other metrics to see if any alerts were triggered (or are close to being triggered). So far, our instance has never triggered this alert. See Diagnostics for third-party apps for details on how to view and analyze alerts generated by apps. |
Node
| Metric we track | Alerting level | What we do when alert is triggered |
|---|---|---|
| CPU and RAM utilization. Git can be resource-intensive – particularly on CPU and RAM, so we monitor these metrics. | We don't have any automated alerts for this. Rather, we monitor it in conjunction with hosting tickets to help assess any slowdown in the instance. | If the hosting tickets alert is triggered in conjunction with high CPU and RAM usage, we increase resources available to the instance (see Bitbucket Server is reaching resource limits for related details). |
| Disk Latency. Git performance can be very sensitive to latency. | We don't have any automated alerts for this. Rather, we monitor it in conjunction with hosting tickets to help assess any slowdown in the instance. | If the hosting tickets alert is triggered as disk latency is high, we check the storage hardware and connection. We also check disk latency data when we investigate any incidents resulting in poor performance to help determine the root cause. |
| Hazelcast: number of remote operations. A high number of these requests can indicate a cluster network problem that can result in a split-brain scenario (see Recovering from a Data Center cluster split-brain for related details). | > 1000/second over a 5 minute period. This value typically indicates a problem with the cluster network, or that certain event queues are backed up. It also suggests that the cluster is having problems recovering from a split-brain scenario. | When this alert is tripped, we immediately perform a rolling restart on the Hazelcast cluster nodes. In addition, we contribute to the Hazelcast project to improve its resilience and reliability. |
Non-alerted metrics
We don't set any alerts for the following metrics, but we monitor them regularly for abnormal spikes or dips.
| Metric we track | Monitoring practice |
|---|---|
HTTP request latency. We monitor the average HTTP response time as a general indication of latency. | We monitor this as part of our performance testing cycle, and don't have any automated alerts for it. This metric also helps us quickly check the performance level of the instance, although any critical performance levels already trigger other alerts (in particular, hosting tickets). In the event of any significant outage, we study the data collected for this metric when investigating the root cause. |
Git pushes/pulls per second. Pushes and pulls form a large majority of all Git operations, and helps provide a general idea of how much load the instance is under. | We monitor this metric at a high level, as Git pulls (fetch or clone) consume a significant amount of CPU and RAM. Sudden spikes in this metric can indicate something is throttling throughput or applying abnormal load to the system. We don't set any alerts for this metric, though, as critical levels will start queueing hosting tickets – and we already have alerts for that. When we investigate any outages or similar incidents, we analyze the data collected for this metric and compare it with general usage/load over time. We collect this data using JMX counters. See Enabling JMX counters for performance monitoring for more details. |
JVM Heap. A healthy value for this metric indicates that Bitbucket has enough memory. | We monitor this metric mostly for development feedback. This data also helps us check whether Bitbucket has any memory leaks. |
CPU usage by Garbage Collector. When the Garbage Collector uses a lot of CPU time, it usually causes performance slowdown. | We monitor this metric mostly for development feedback. This data often helps us find the cause of performance slowdown. |
We're here to help