LDAP import
A Lightweight Directory Access Protocol (LDAP) directory is a collection of data about users and other assets. If you work with a corporate directory that contains your assets or employee-manager relationships used for approval processes, you can import such LDAP entries to Assets. To make things easy, Assets has modules that works with popular LDAP directories, which fetch the structure and the assets from your directory. This article shows you how to set this up. More about importing
You need to be a Jira admin to create, configure, and enable LDAP imports.
Skip to:
- LDAP overview
- LDAPS validation
- Importing LDAP
- Pre-defined structure and configuration
- Import configuration created
- Object type mapping
Overview
LDAP is an Internet protocol that web applications can use to look up information about those assets from the LDAP server.
We provide a built-in connectors for the most popular LDAP directory servers:
Microsoft Active Directory
Apache Directory Server (ApacheDS)
Apple Open Directory
Fedora Directory Server
Novell eDirectory
OpenDS
OpenLDAP
OpenLDAP Using Posix Schema
Posix Schema for LDAP
Sun Directory Server Enterprise Edition (DSEE)
A generic LDAP directory server
LDAPS validation
LDAPS (Secure LDAP) is supported and doesn't have any special requirements from Assets to work.
If you are trying to import from an LDAPS source, you can choose to validate the LDAP server certificate with an imported Certificate Authority (CA) certificate. If you select to validate the LDAP server certificate, you must import the root CA certificate from the CA that signed the LDAP server certificate, so your Jira can use the CA certificate to validate the LDAP server certificate. More information is explained here.
Be sure to change the port to 3269. This is due to the fact that a GC (global catalog) server returns referrals on 389 which refers to the greater AD "forest", but acts like a regular LDAP server on 3268 (and 3269 for LDAPS) when changing from LDAP to LDAPS.
Importing LDAP
From your service project, go to Assets, then Object Schemas.
From the Object Schemas list, select More actions and then select Configure.

In the Schema configuration view, open the Import tab.
Under the Import tab:
If there’s no import structure, you’ll see the message “You don't have any import connections yet”. Select Create Import configuration to create a new import structure.
If an import structure has already been created, select Create Configuration.

Select the import method you wish to use, then select Next.
Fill in the General, Module, and Scheduling import fields.

7. Select Save Import Configuration.
Next, you can create a predefined structure and configuration for your LDAP import.
Pre-defined structure and configuration
You can import users or groups from only one Organizational Unit (OU) during an Assets LDAP import. For more information, see How to import users or groups from specific OUs with Assets LDAP import.
Create predefined structure – this will create object types with attributes and relationships in the schema
Create predefined configuration – this will create type mappings in the import configuration.

Here's some details for the LDAP import:
The structure will be created based on the result from the LDAP server. When creating the predefined structure, a query will be sent to the LDAP server with the configuration specified and fetch the result. Based on the result, an object type hierarchy will be created. Each node (identified by DN) that has children will be treated as an object type and created. The attributes belonging to the Assets object type will be the attributes found on the node in the LDAP server.
If the result returned by LDAP server retrieves objects that don't have children, then it won't be possible to create a predefined structure automatically and it should be created manually.
The predefined structure will create two additional attributes for each object type. The attribute CN (Common Name) will be used as label and the attribute DN (Distinguished Name) will be set with the property hidden.
All attributes created by the predefined structure in the LDAP import will be of type Default Text. If the data represent something else review the attributes and change them accordingly.
Example
Example LDAP structure | Resulting Assets Object Type Structure |
|---|---|
|
|
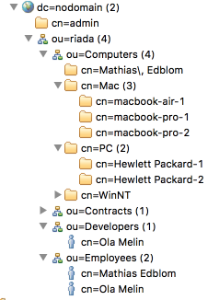

The predefined configuration will query the LDAP server and create a configuration mapping based on the same criteria as the structure described above. As data locators all attributes found will be choosable with the addition of the CN (Common Name) and the DN (Distinguished Name).
The identifier will be set to DN for each object to uniquely identify each object from the LDAP server. Since the predefined configuration will be different based on the connected LDAP server, the following is one example mapping the Employees as seen in the previous example.

If the LDAP import is configured to import users one can use the REGEX configuration to split users in order to create multiple users.
Import configuration created
You can now view your import configuration, but it's not ready yet. You still need to create or review the object type and attribute mapping, and make sure there are no problems with your import configuration.
When you're ready, go to 2. Create object type and attribute mapping.
Before you go
In the next step, you'll create the object mapping settings. Here are some settings specific to the LDAP import type.
Object type mapping
Name | Description |
|---|---|
| Selector | In the LDAP import type, the Selector is prepended to the Base DN value before the search in LDAP is executed. The value is used to narrow down the structured tree in the LDAP to specific nodes. The search filter will be the same as specified in the general configuration but the selector will narrow the scope where the search filter is applied. For example, if the Base DN is |