Estimating an issue
Before you begin
Estimating stories in your backlog helps you predict how long it would take you to deliver certain portions of the backlog. Note that this discussion refers to the best practices we've implemented as the main path in JIRA Software — you can choose not to use this approach if you feel it's really not suitable for your team.
![]() This page only applies to Scrum boards.
This page only applies to Scrum boards.
On this page:
Estimate an issue
Before a sprint starts, you need to enter the Original Estimates of your issues. And as you work on the issues during the sprint, you may need to adjust the Remaining Estimates as necessary.
To enter the Original Estimate, do the following for each issue:
- Navigate to the Backlog of your desired board.
- Click the issue that you want to set the Original Estimate for.
- In the Issue Detail View, type your estimate in the Estimate field.
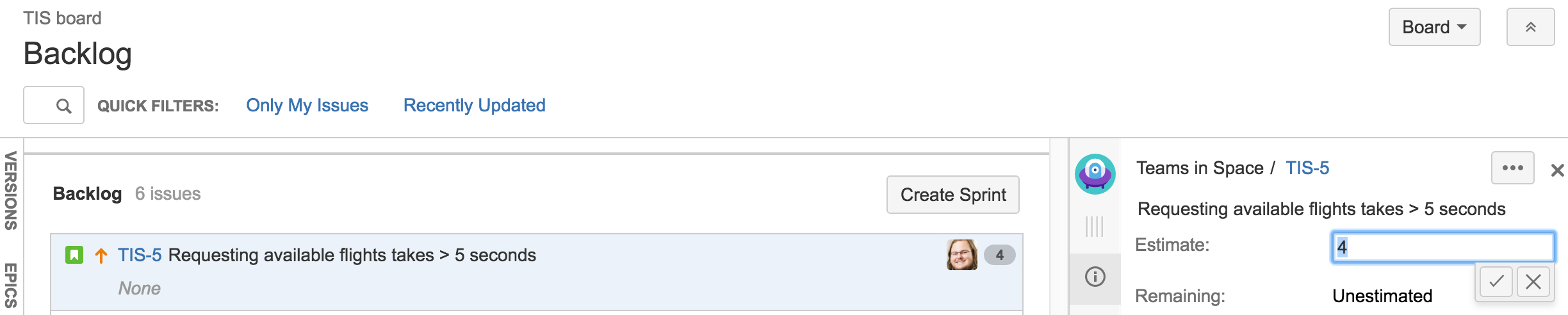
 The type of units used by the 'Estimate' field (e.g. hours) is affected by your Estimation Statistic — see Configuring estimation and tracking.
The type of units used by the 'Estimate' field (e.g. hours) is affected by your Estimation Statistic — see Configuring estimation and tracking.
To adjust the Remaining Estimate:
- Navigate to the Active sprints of your Scrum board.
- Click the issue that you want to adjust the Remaining Estimate for.
In the Issue Detail View, type your estimate in the Remaining field.
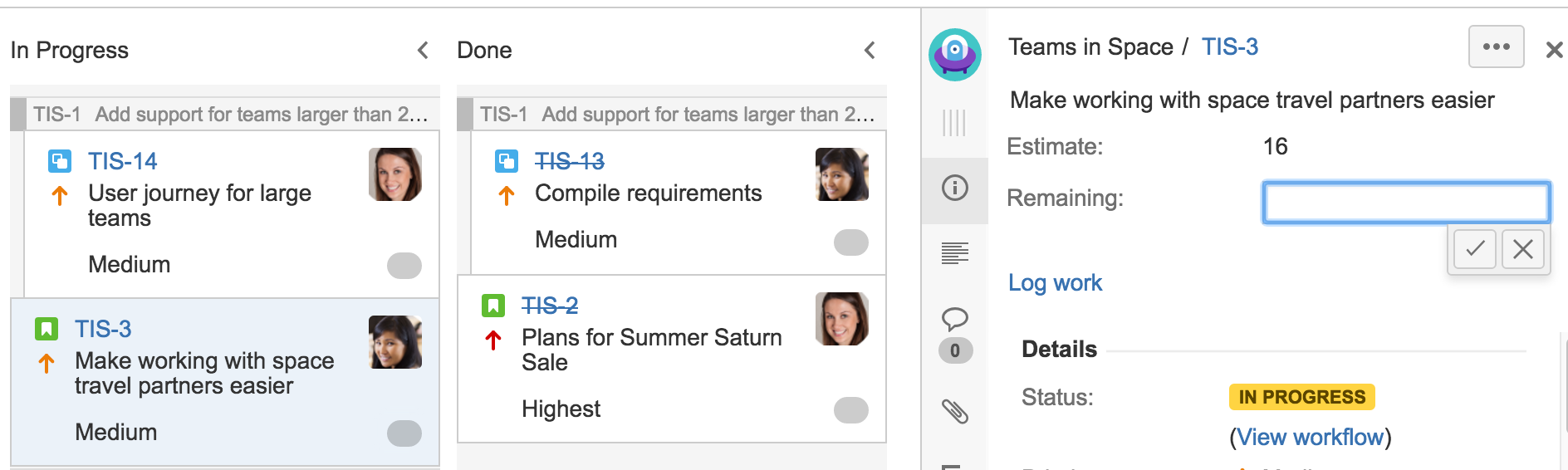 The type of units used by the 'Remaining' field (e.g. hours) is affected by your Tracking Statistic — see Configuring estimation and tracking.
The type of units used by the 'Remaining' field (e.g. hours) is affected by your Tracking Statistic — see Configuring estimation and tracking.
Concepts about estimation
Here are some concepts to consider when estimating issues in JIRA Software.