Installing Crowd Data Center
To install Crowd Data Center, you'll create a cluster of Crowd instances that will make sure your users have uninterrupted access both to Crowd, and all other systems that are connected to it. We recommend that you start with the prerequisite information, listed on this page, to understand what Data Center is, and to know exactly what you'll need to complete the installation.
Before you begin
Before you install Crowd Data Center, take a look at the specifics below.
What is Crowd Data Center? | |
| How do I get it? | |
What are the prerequisites? | |
| Do I need a load balancer? |
1. Install Crowd
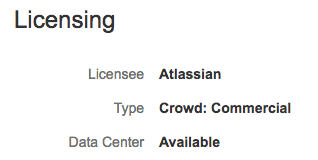
Crowd Data Center is available for Crowd 3.0, or later. If you're not on this version yet, install or upgrade your Crowd instance. See Crowd installation and upgrade guide.
After you've installed Crowd and applied your license, you can verify that Data Center is available by going to Administration ![]() > Licensing.
> Licensing.
2. Set up the shared directory
You'll need to create a remote directory that is readable and writable by all nodes in the cluster. There are multiple ways to do this, but the simplest is to use an NFS share.
Stop Crowd.
- Go to Crowd's home directory, and check whether it already has the
sharedsub-directory, which might have been created after starting Crowd. If it's there, you'll need to copy its contents to the new shared directory that you'll create in the next steps. If you can't find it, just omit this step. - Create a remote directory, accessible by all nodes in the cluster, and name it
shared. Mount shared as a sub-directory of the Crowd home directory.
<home-directory>/shared
3. Add the first Crowd node to your load balancer
Before you begin
You must enable clustering in Crowd first. To do that, in your shared directory edit the crowd.cfg.xml file and set the crowd.clustering.enabled property to true and restart Crowd.
The load balancer distributes the traffic between the nodes. If a node stops working, the remaining nodes will take over its workload, and your users won't even notice it.
- First, add your load balancer as a trusted proxy server in Crowd. See Configuring Trusted Proxy Servers.
Add the first node to the load balancer.
- Restart the node, and then try opening different pages in Crowd. If the load balancer is working properly, you should have no problems with accessing Crowd.
In Crowd, go to
 > Clustering. The node should be listed as part of the cluster.
> Clustering. The node should be listed as part of the cluster. 
If your load balancer supports health checks, configure it to perform a check on
http://<crowd-node>:8095/<context-path>/status, where<crowd-node>is the node's hostname or IP address, and<context-path>is the Crowd's context path (e.g./crowd). If the node doesn't respond with a200 OKresponse within a reasonable time, the load balancer shouldn't direct any traffic to this node.- After you've added the node to the load balancer, configure the Crowd's base URL to also point to the load balancer. Go to > General, and enter the URL of your load balancer as Base URL.

4. Add the remaining nodes to the cluster
- Copy the Crowd installation directory to the new node.
- Create a home directory, like you did for the first node, and mount
sharedas its sub-directory. Edit
crowd-init.properties, and enter the path to the home directory that you just created.- Go to
<installation-directory>/apache-tomcat/conf/Catalina/localhost, and delete theopenidserver.xmlfile. This is needed because currently the CrowdID component doesn't support clustering, and it must be enabled only on the first node. The component will work as usual. - Start Crowd. It will read the configuration from the shared directory, and start without any extra setup.
- Take a look around the new Crowd instance. Verify that user and group management, directory synchronization, and any custom integrations all work as expected.
- Again, verify that the node was added to the cluster. In Crowd, go to
 > Clustering.
> Clustering.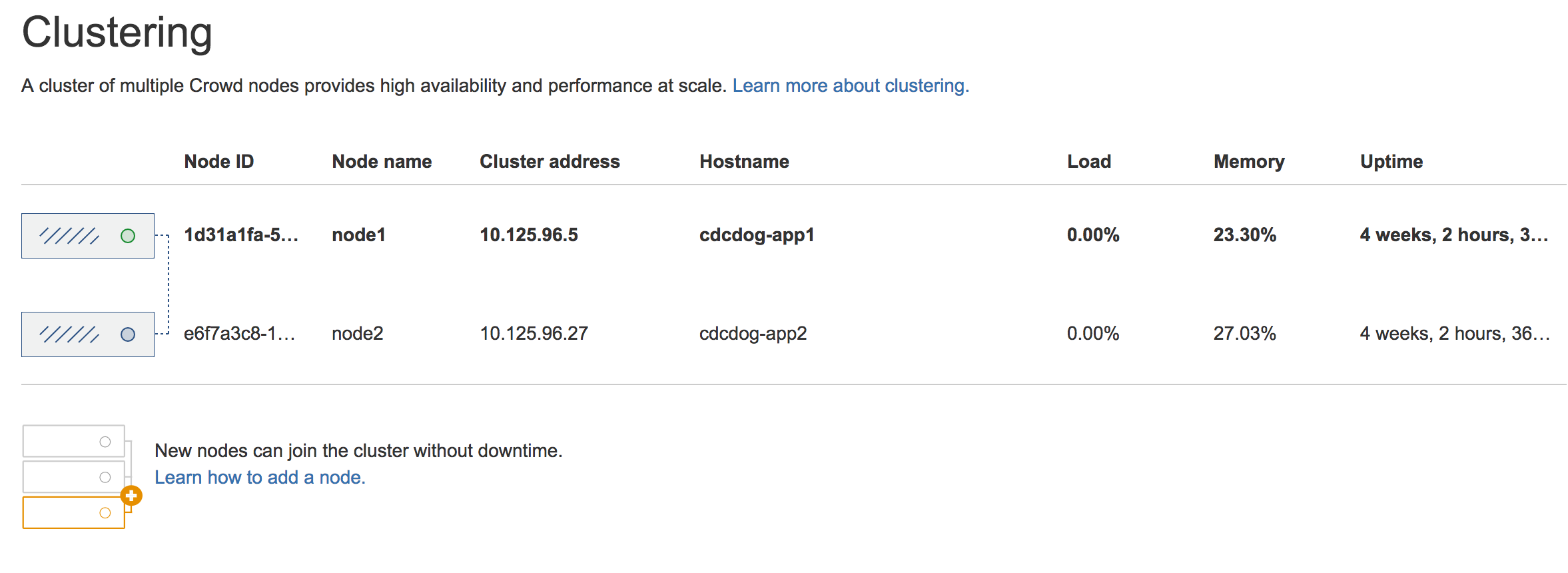
If everything looks fine, you can configure your load balancer to start routing traffic to the new node. Once you do this, you can make a couple of changes in one Crowd instance to see if they're visible in other instances as well.
What else?
Adding node names
When displaying information about your nodes in the Crowd footer or on the ![]() > Clustering page, Crowd Data Center uses random IDs that were generated for your nodes. Instead, you can give them more persistent and readable names by setting the
> Clustering page, Crowd Data Center uses random IDs that were generated for your nodes. Instead, you can give them more persistent and readable names by setting the cluster.node.name system property, like in the following example:
CATALINA_OPTS=-Dcluster.node.name=node-1Well done! Crowd Data Center is now at your service. Learn more about what Crowd Data Center provides