Scaling Bitbucket Server
This page discusses performance and hardware considerations when using Bitbucket Server.
Note that Bitbucket Data Center, not discussed on this page, uses a cluster of Bitbucket Server nodes to provide Active/Active failover, and is the deployment option of choice for larger enterprises that require high availability and performance at scale.
Hardware requirements
The type of hardware you require to run Bitbucket Server depends on a number of factors:
- The number and frequency of clone operations. Cloning a repository is one of the most demanding operations. One major source of clone operations is continuous integration. When your CI builds involve multiple parallel stages, Bitbucket Server will be asked to perform multiple clones concurrently, putting significant load on your system.
- The size of your repositories – there are many operations in Bitbucket Server that require more memory and more CPUs when working with very large repositories. Furthermore, huge Git repositories (larger than a few GBs) are likely to impact the performance of the Git client.
- The number of users.
Here are some rough guidelines for choosing your hardware:
- Estimate the number of concurrent clones that are expected to happen regularly (look at continuous integration). Add one CPU for every 2 concurrent clone operations. Note that enabling the SCM Cache Plugin (bundled with Bitbucket Server from version 2.5.0) can help to reduce the cloning load on the Bitbucket Server instance due to CI polling. See Scaling Bitbucket Server for Continuous Integration performance .
- Estimate or calculate the average repository size and allocate 1.5 x number of concurrent clone operations x min(repository size, 700MB) of memory.
Adaptive throttling
Until Bitbucket Server 4.11, resource throttling was achieved by allocating a fixed number of tickets and each hosting operation would have to acquire a ticket before it could proceed. Hosting operations finding no tickets available had to queue until one was available and would time out if it queued for too long. The default was 1.5 tickets per number of CPU cores, but you could increase this within the app properties. Getting this number right was challenging.
Bitbucket Server 4.11 introduced a new throttling approach for SCM hosting operations that adapts to the stress the machine is under, referred to as adaptive throttling. With adaptive throttling, Bitbucket examines the total physical memory on the machine and determines a maximum ticket number that the machine can safely support given an estimate of how much memory a hosting operation consumes, how much memory BBS needs, and how much search needs. The default minimum (1 ticket per CPU core) and maximum (12 tickets per CPU core) of the ticket range can be changed.
Other characteristics of adaptive resource throttling:
- Allows a variable range of ticket values depending on how close current CPU usage is to a target CPU usage (defaults to 75% CPU usage). This can be changed.
- Every 5 seconds it resamples the CPU usage and recalculates how many tickets within the range can be supported.
- CPU readings are smoothed so as to not respond too suddenly to CPU spikes and overshoot/undershoot the optimum number of tickets.
Adaptive throttling is enabled by default for Bitbucket Server 4.11+, but may revert to fixed throttling strategy under these circumstances:
- You previously set a non-default fixed number of tickets, for instance
throttle.resource.scm-hosting=25 - You previously configured this strategy explicitly, for instance
throttle.resource.scm-hosting.strategy=fixed
throttle.resource.scm-hosting.fixed.limit=25 - The adaptive throttling configuration is invalid in same way
- The total memory of the machine is so limited that the entire tickets range is unsafe
Understanding Bitbucket Server's resource usage
Most of the things you do in Bitbucket Server involve both the Bitbucket Server instance and one or more Git processes created by Bitbucket Server. For instance, when you view a file in the Bitbucket Server web application, Bitbucket Server processes the incoming request, performs permission checks, creates a Git process to retrieve the file contents and formats the resulting webpage. In serving most pages, both the Bitbucket Server instance and Git processes are involved. The same is true for the 'hosting' operations: pushing your commits to Bitbucket Server, cloning a repository from Bitbucket Server or fetching the latest changes from Bitbucket Server.
As a result, when configuring Bitbucket Server for performance, CPU and memory consumption for both Bitbucket Server and Git should be taken into account.
Memory
When deciding on how much memory to allocate for Bitbucket Server, the most important factor to consider is the amount of memory required for Git. Some Git operations are fairly expensive in terms of memory consumption, most notably the initial push of a large repository to Bitbucket Server and cloning large repositories from Bitbucket Server. For large repositories, it is not uncommon for Git to use up to 500 MB of memory during the clone process. The numbers vary from repository to repository, but as a rule of thumb 1.5 x the repository size on disk (contents of the .git/objects directory) is a rough estimate of the required memory for a single clone operation for repositories up to 400 MB. For larger repositories, memory usage flattens out at about 700 MB.
The clone operation is the most memory intensive Git operation. Most other Git operations, such as viewing file history, file contents and commit lists are lightweight by comparison.
Bitbucket Server has been designed to have fairly constant memory usage. Any pages that could show large amounts of data (e.g. viewing the source of a multi-megabyte file) perform incremental loading or have hard limits in place to prevent Bitbucket Server from holding on to large amounts of memory at any time. In general, the default memory settings (max. 768 MB) should be sufficient to run Bitbucket Server. The maximum amount of memory available to Bitbucket Server can be configured in setenv.sh or setenv.bat.
The memory consumption of Git is not managed by the memory settings in setenv.sh or setenv.bat. The Git processes are executed outside of the Java virtual machine, and as a result the JVM memory settings do not apply to Git.
CPU
In Bitbucket Server, much of the heavy lifting is delegated to Git. As a result, when deciding on the required hardware to run Bitbucket Server, the CPU usage of the Git processes is the most important factor to consider. And, as is the case for memory usage, cloning large repositories is the most CPU intensive Git operation. When you clone a repository, Git on the server side will create a pack file (a compressed file containing all the commits and file versions in the repository) that is sent to the client. While preparing a pack file, CPU usage will go up to 100% for one CPU.
Encryption (either SSH or HTTPS) will have a significant CPU overhead if enabled. As for which of SSH or HTTPS is to be preferred, there's no clear winner, each has advantages and disadvantages as described in the following table.
| HTTP | HTTPS | SSH | |
|---|---|---|---|
| Encryption | No CPU overhead for encryption, but plaintext transfer and basic auth may be unacceptable for security. | Encryption has CPU overhead, but this can be offloaded to a separate proxy server (if the secure connection is terminated there). | Encryption has CPU overhead. |
| Authentication | Authentication is slower – it requires remote authentication with the LDAP or Crowd server. | Authentication is much faster – it only requires a simple lookup. | |
| Cloning | Cloning a repository is slightly slower – it takes at least 2 and sometimes more requests, each of which needs authentication and permission checks. The extra overhead is small though - usually in the 10-100ms range | Cloning a repository takes only a single request. | |
Clones examined
Since cloning a repository is the most demanding operation in terms of CPU and memory, it is worthwhile analyzing the clone operation a bit closer. The following graphs show the CPU and memory usage of a clone of a 220 MB repository:
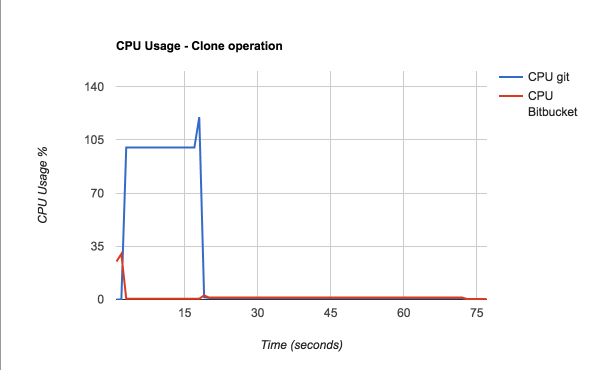
Git process (blue line)
- CPU usage goes up to 100% while the pack file is created on the server side.
- CPU peaks at 120% when the pack file is compressed (multiple CPUs used).
- CPU drops back to 0.5% while the pack file is sent back to the client.
Bitbucket Server (red line)
- CPU usage briefly peaks at 30% while the clone request is processed.
- CPU drops back to 0% while Git prepares the pack file.
- CPU hovers around 1% while the pack file is sent to the client.
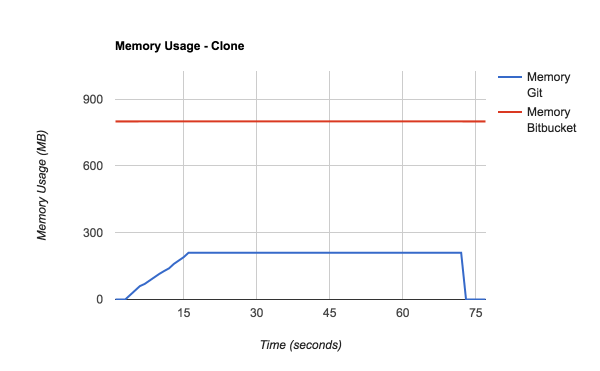
Git process (blue line)
- Memory usage slowly climbs to 270 MB while preparing the pack file.
- Memory stays at 270 MB while the pack file is transmitted to the client.
- Memory drops back to 0 when the pack file transmission is complete.
Bitbucket Server (red line)
- Memory usage hovers around 800 MB and is not affected by the clone operation.

This graph shows how concurrency affects average response times for clones:
- Vertical axis: average response times.
- Horizontal axis: number of concurrent clone operations.
Configuring Bitbucket Server scaling options and system properties
Bitbucket Server limits the number of Git operations that can be executed concurrently, to prevent the performance for all clients dropping below acceptable levels. These limits can be adjusted – see Bitbucket Server config properties.
These properties define concurrent task limits for the ThrottleService, limiting the number of concurrent Git operations of a given type
that may be run at once. This is intended to help prevent Bitbucket Server from overwhelming a server machine with running processes. Bitbucket Server has two settings to control the number of Git processes that are allowed to process in parallel: one for the web UI and one for the 'hosting' operations (pushing and pulling commits, and cloning a repository).
When the limit is reached for the given resource, the request will wait until a currently running request has completed. If no request completes within a configurable timeout, the request will be rejected. When requests while accessing the Bitbucket Server UI are rejected, users will see either a 501 error page indicating the server is under load, or a popup indicating part of the current page failed. When Git client 'hosting' commands (pull/push/clone) are rejected, Bitbucket Server does a number of things:
- Bitbucket Server will return an error message to the client which the user will see on the command line: "Bitbucket Server is currently under heavy load and is not able to service your request. Please wait briefly and try your request again"
- A warning message will be logged for every time a request is rejected due to the resource limits, using the following format:
"A [scm-hosting] ticket could not be acquired (0/12)" - For five minutes after a request is rejected, Bitbucket Server will display a red banner in the UI to warn that the server is under load.
The hard, machine-level limits these are intended to prevent hitting are very OS- and hardware-dependent, so you may
need to tune them for your instance of Bitbucket Server. When hyperthreading is enabled for the server CPU, for example, it is likely that the server will allow sufficient concurrent Git operations to completely bury the I/O on the machine. In such cases, we recommend starting off with a less aggressive default on multi-cored machines – the value can be increased later if hosting operations begin to back up. These defaults are finger-in-the-wind guesstimates (which so far have worked well).
Additional resource types may be configured by defining a key with the format throttle.resource.<resource-name>.
When adding new types, it is strongly recommended to configure their ticket counts explicitly using this approach.
Database requirements
The size of the database required for Bitbucket Server depends in large part on the number of repositories and the number of commits in those repositories.
A very rough guideline is: 100 + ((total number of commits across all repos) / 2500) MB.
So, for example, for 20 repositories with an average of 25,000 commits each, the database would need 100 + (20 * 25,000 / 2500) = 300MB.