Hierarchical File System Attachment Storage
Confluence 8.1 introduced a new way to store attachment data in the file system.
When you upgrade to Confluence 8.1 or later, your attachments will be migrated to a new folder structure. More information about this migration task is available on this page.
For information about the previous folder structure, see the version of Hierarchical File System Attachment storage in Confluence 8.0 documentation or earlier.
Confluence stores attachments, such as files and images, in a file system.
The structure of the attachment storage has been designed to:
limit the number of entries at any single level in a directory structure
eliminate the need to move attachments between directories when a page is moved to a new location
On this page:
Directory structure
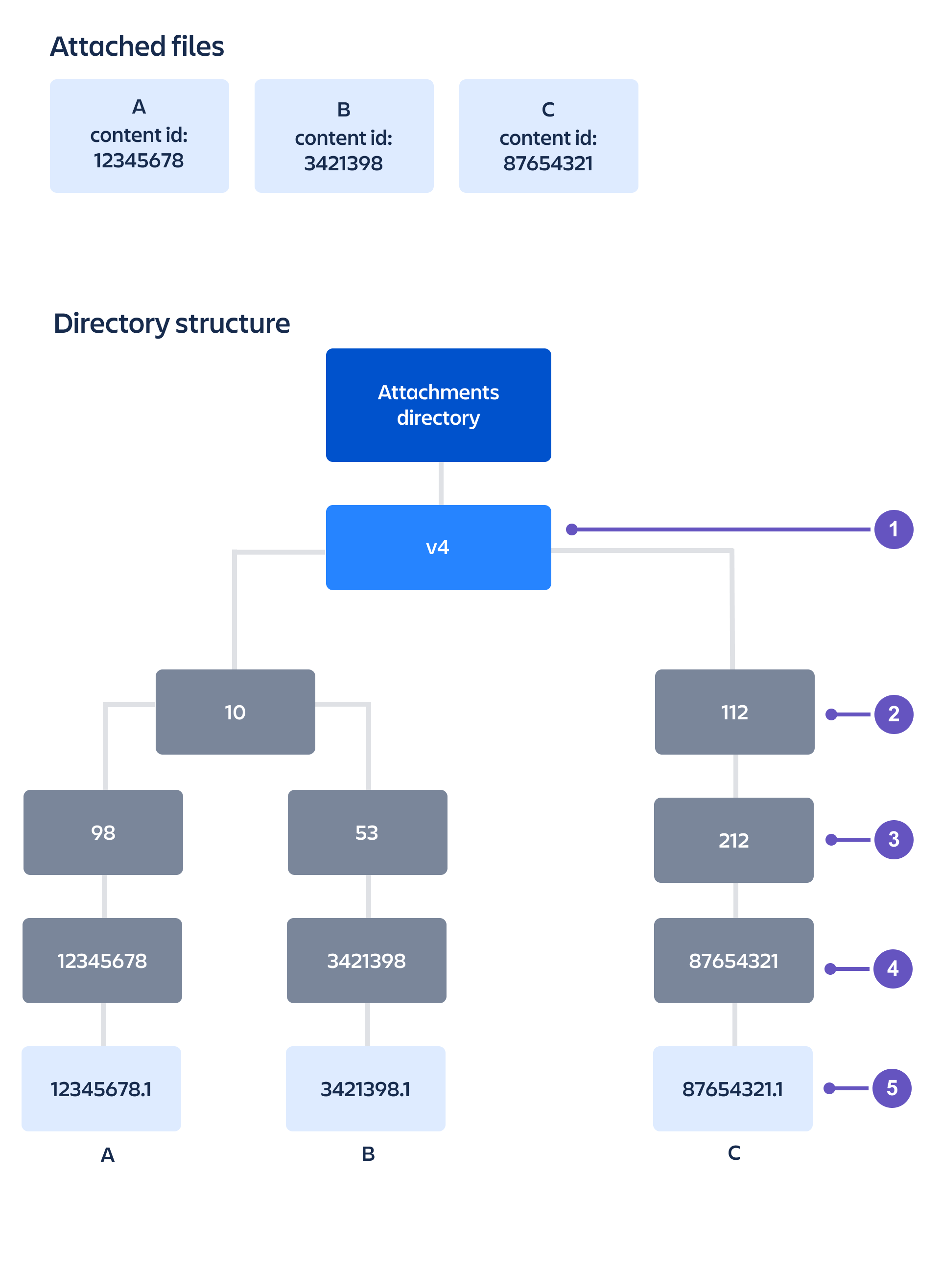
Attachments in Confluence have a single identifying attribute: the Content id of the original version of the attachment.
For example, the original version of the attachment has the Content id 12345678 so the attachment file names for versions 1, 2, and 6 will be 12345678.1, 12345678.2, 12345678.6 respectively.
The directory structure consists of 5 levels with the name of each level derived from the following algorithms:
level | Derived From |
|---|---|
1 (top) | Always 'v4' indicating the Confluence version 4 storage layout format |
2 | Calculated as Content id modulo 65535, modulo 256 |
3 | Calculated as Content id modulo 65535, divided by 256 |
4 | The Content id of the attached file |
5 | These are the file names. They are named the Content id and version number of the file, for example: x.1, x.2, x.6. |
The modulo calculation is used to find the remainder after division, for example 800 modulo 250 = 50.
#!/bin/sh
content_id=$1
version=1
domain=`expr $content_id % 65535`
folder_1=`expr $domain % 256`
folder_2=`expr $domain / 256`
echo "v4/$folder_1/$folder_2/$content_id/$content_id.$version"Diagram of the directory
Extracted text files
When a text-based file is uploaded in Confluence (for example Word, PowerPoint, etc), its text is extracted and indexed so that people can search for the content of a file, not just the filename. We store the extracted text so that when that file needs to be reindexed, we don't need to re-extract the content of the file.
The extracted text file will be named with the content id and version number, for example, 12345.2.extracted_text, and stored alongside the file versions themselves (within level 5 in the example above). We only keep the extracted text for the latest version, not earlier versions of a file.
Migration to version 4
Confluence 8.1 introduced the v4 layout format for storing attachments. To ensure a smooth transition from the previous version 3 structure, we added an automatic background task to do this migration when you upgrade to Confluence 8.1 or later.
The migration task moves all attachments from the ver003 directory to the new v4 directory. Any missing or broken attachments resulting from previous failed page moves that are found in this process will be restored. Duplicate attachments will be saved with the extra extension .duplicate.X.
This background task will only run on Confluence startup if a ver003 directory exists in the attachments folder. During this process, Confluence will work as usual.
When the migration task is finished, a report file v3-to-v4-report.log will be available in the attachments directory. A new report is created for each migration run. It contains a list of files with corresponding issues, and the migration status is printed at the bottom – for example, completed successfully, completed with warnings, or interrupted. The report file does not print successfully migrated attachments to avoid huge log files.
Customizations
These dark feature customizations are available for your migration. To learn how to configure them, see Configuring System Properties.
System property | Description |
|---|---|
-Datlassian.darkfeature.confluence.disable-attachments-ver004=true | Set this property to disable migration to Any attachments that have already been migrated to |
-Dconfluence.attachments-ver004-migration-num-of-threads=X | By default, migration uses up to half of the available CPUs on the node. Set the number of CPUs by providing a number instead of X. Reach out to support for assistance with this feature. |
Troubleshooting
Issue | Solution |
|---|---|
| I want to know what logs are available | You can find more about the migration from application logs in There is also a report file |
I want to find out if the migration was successful | The ver003 directory will be deleted if migration was successful. You should also review the report log. The final status will be printed at the bottom. |
I want to find out if the migration is happening | A report log is created in the attachments directory. Also an entry is printed in |
I can see multiple report logs in the attachments folder, I want to find out which is the correct one | A report log is created for each migration. If multiple reports are generated, you need to review the latest report and troubleshoot the issue. You may need to delete or move any files that are not real attachments from the ver003 directory. Once all attachments have been migrated successfully, there won’t be new report logs in the folder. |
The report shows | Due to past issues, some of your attachments may be duplicated in the ver003 directory. See
CONFSERVER-62835
-
Getting issue details...
STATUS
. If the migration task finds duplicate files it will move them to v4 directory and add |
The report shows | This means a file failed to migrate. Check if permissions allow the move operation, and if the file is not a real attachment you will need to delete or move it from the ver003 directory manually. Then, restart Confluence to trigger another migration task. |
I'm running a Confluence DC cluster and can't see any migration logs | The migration runs only on one node, so if you're not in the same node you won't be able to see progress for it in the application log, Every node in the cluster should be able access the report file |
I want to know if the migration is using up extra disk resources | Migration performs Also, |
I don’t want to do this migration yet | We have a dark feature that allows you to disable migration to v4. See customizations for more info. |