Insight 5.0 release notes
Endless import opportunities
We have totally reworked the import functionality from scratch. We are proud to provide you the possibility to unleash more of Insight's true potential. We have seen it before; one, two or more excel sheets, possibly with a database that together are the "truth" regarding assets.
We have removed the previous restriction, which meant that it was only possible to have one import connected to one object type at the same time. In other words it is now possible to automatically sync your data from all of the above sources (and yes it is possible to sync data from an external database with Insight 5.0) to Insight in order to enable the complete view of the combined data.
When we were working on the import functionality we added the possibility to do the opposite as above: Given an external data source it is now possible to read different parts from the source and insert it into different object types using IQL. Not only by IQL but it's also possible to divide external data directly from the source, which greatly improves the ability to configure great imports.
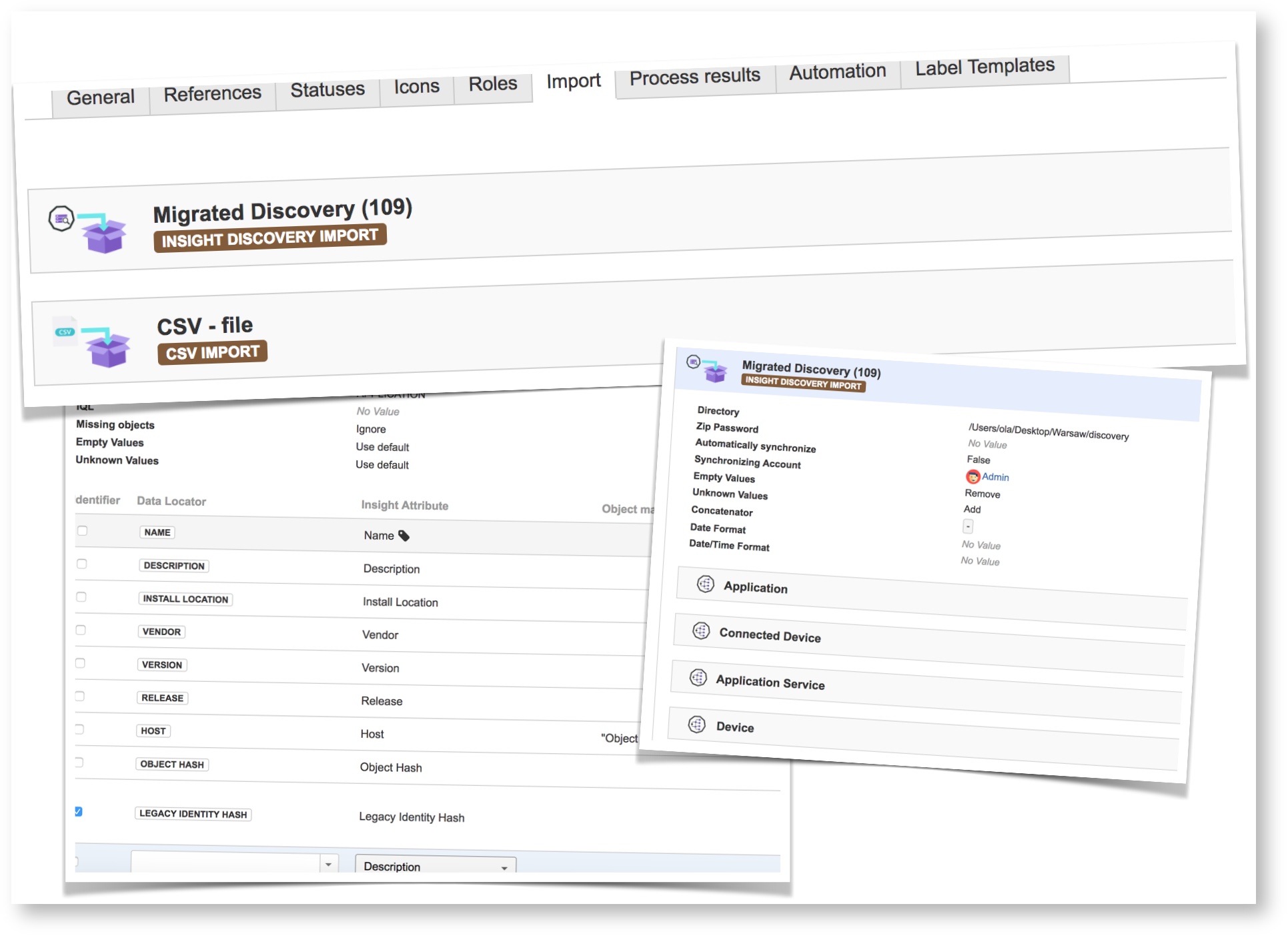
Let us explain how the Discovery import benefits from the above change. You can now configure which data to import into Insight, which object types that will be populated with data, what attributes should be populated and the type of these attributes. It is finally possible to put the extra information (that Insight Discovery can be configured with) to be populated into structured attributes in Insight. Even object reference fields can now be created by entering an IQL with some placeholders.
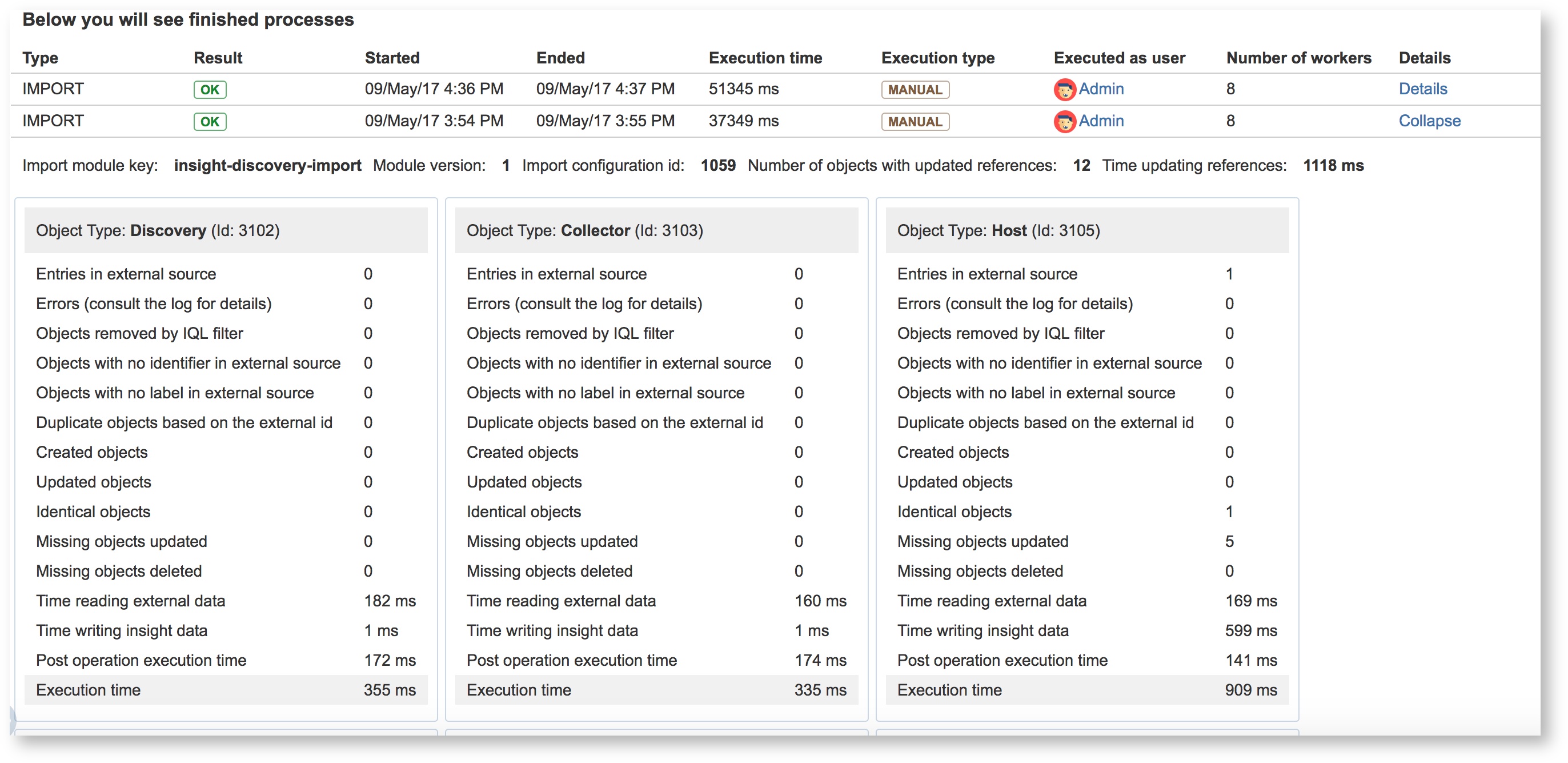
To ease the task of troubleshooting and to monitor executed processes in Insight, we have introduced process result. This is implemented for the new imports but we will of course reuse it for more functionality in the future. At this time, it is possible to see how an import was executed, how many items were created, updated, ignored, deleted, and the time consumed. A huge benefit when it comes to be confident in data that is imported (and eventually other jobs).
We did not think that the above functionality was enough, so we decided to make the import functionality module based with a clear interface and the possibility for extension. It is now possible to write your own import modules and deploy it as an add-on to JIRA and be able to load data from any source of data. The responsibility for the module is to read and interpret data while configuration and insertion of structured data is handled by Insight.
We hope that a lot of import modules will be supplied 3rd parties to help migrate users from different systems into Insight. To ensure that our concept works, we have added a "JIRA environment" import which basically scans JIRA for configuration data, such as Projects, Issue Types, Fields, Notification Schemes and so on, and all relationships will be created! A JIRA administrators dream! Think about it, you can now easily create automatic rules that triggers when a project unused for 6 month, when a permission rule is changed for a critical permission schema, or when someone are removing an important field from a JIRA screen. There's no end to the possibilities!
True inheritance
With Insight 5.0, it is now possible to use inheritance in object type structures. What inheritance means is that every child of a parent with inheritance enabled will inherit all the parent´s attributes, and the inheritance will work on the grandchildren and their children and so forth. It is now possible to create an object type "Host" with children "Linux Host" and "Windows Host" where the latter two inherit common attributes such as "IP Address" and "Host name" from the "Host" object type.
To make this visible, we changed Insight's basic view so that it is possible to see all objects in an inheritance tree for both the current object type and all of it's children. This enables the possibility to filter and search with IQL on all children in the inheritance tree and compare them to each other. When implementing this we realized that in some cases, an object type may exist only to define attributes to it's children, so we introduced the abstract concept, meaning that an abstract object type can not contain any objects.
Of course, this is something that should be visible in the graph, so we added that feature too.
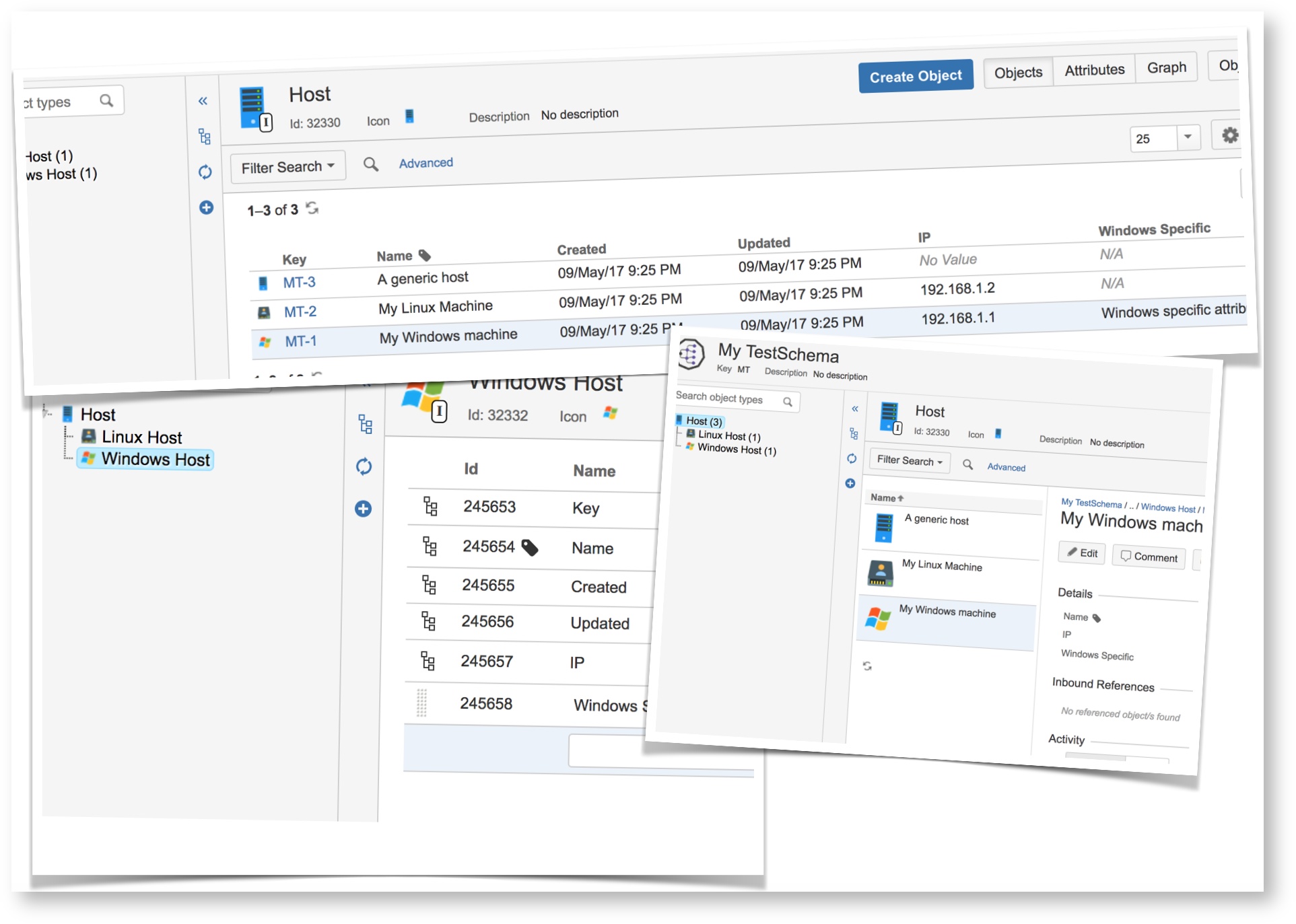
You will not be able to set inheritance on an already created object type structure but you can create a structure and move your objects accordingly.
Label
Many people have asked us to be able to change the "display name" on Insight objects. We are proud and happy to introduce this functionality. All attributes
that are of type "Text" can now be changed to be the Label. This means that it is this attribute (the label) that will be seen everywhere in Insight and JIRA.
Files
Files uploaded to Insight from CSV import perspective or Label Templates can no be access via a File section for each object schema. You can see the status of the file and also dependency to other resources in the system.
Audit log
It is now possible to configure Insight to create audit log entries for object changes. Look in the configuration page under the manage add-ons page. Each change to an object will be added as a row in the insight_audit.log. This feature is disabled by default.
Insight logging
The Insight logs have moved from their separate folder into the common log folder. The default is that Insight logs will be rotated each day but the housekeeping of the files needs to be handled according to your own log policy.
Insight locked
When Insight is starting up without a Index file, if Insight is configured to load cache from database or if Insight detects that the cache is corrupt during startup Insight will be locked until the process of reindex all Insight objects is complete. This is to ensure that Insight is not operating on data that is not valid.
When Insight is locked all automation events that are triggered will be queued until Insight is unlocked. Import tasks that are triggered will halt with an exception stating that Insight is locked.
Parallelism
We added the possibility to configure Insights parallelism. The default is to use all available cores when dividing tasks that needs to be done. If this is not the way you want Insight to operate visit the Insight configuration page and change the value to one that suit your needs.
What does the parallelism mean? Some tasks (like import, reindex and object search) will be divided into chunks and executed in parallel. Since the tasks are not dependent on each other executing them in parallel will result in a faster completion time. This comes at the cost of CPU utilisation since more cores will be used to process information.
Ultimately
We are keen on performance so when we're on the new release, we've improved cache management even more and therefore reduced database reads greatly (at the expense of CPU and memory of course).
REST API changes
When creating or updating object types the boolean properties inherited and abstractObjectType needs to be specified.
The JSON to create an object type before Insight 5:
{"name": "My Name", "iconId": 1, "objectSchemaId": 1}Will have to be:
{"name": "My Name", "iconId": 1, "objectSchemaId": 1, "inherited": false, "abstractObjectType": false}JAVA API changes
Breaking changes
We have changed the way how classes of type ObjectBean, ObjectBeanAttribute and ObjectAttributeValueBean are handled. It is no longer possible to instantiate any of these classes, they can only be retrieved from within Insight. The classes that should be used are instead MutableObjectBean, MutableObjectAttributeBean and MutableObjectAttributeValueBean. If you used the recommended way to create ObjectAttributeBean and ObjectAttributeBeanValue you are not affected.
All of the above classes have similar constructs and each of them has a method .createMutable() which will create a mutable copy.
Following is the recommended way to instantiate the classes mentioned (if you have used them in a previous version of Insight they will work after upgrading to Insight 5).
MutableObjectBean mObjectBean = new MutableObjectBean();
MutableObjectBean mObjectBean = objectBean.createMutable();
MutableObjectAttributeBean mObjectAttributeBean = objectBean.createObjectAttributeBean(objectTypeAttributeBean);
MutableObjectAttributeBean mObjectAttributeBean = objectAttributeBean.createMutable();
MutableObjectAttributeValueBean mObjectAttributeValueBean = objectAttributeBean.createObjectAttributeValueBean();
MutableObjectAttributeValueBean mObjectAttributeValueBean = objectAttributeValueBean.createMutable();eturn type changed of ObjectBean.getObjectAttributeBeans() to List<? extends ObjectAttributeBean> instead of previous List<ObjectAttributeBean>
Return type changed of ObjectAttributeBean.getObjectAttributeValueBeans() to List<? extends ObjectAttributeValueBean> instead of previous List<ObjectAttributeValueBean>Added functionality
We have added a factory for you to easier create those attributes and values from the API. If you're looking for an easier way to create ObjectAttributeBeans with corresponding ObjectAttributeValueBeans this is the new place to start.
public MutableObjectAttributeBean createObjectAttributeBeanForObject(ObjectBean objectBean, ObjectTypeAttributeBean ota,
String... values) throws InsightException ;Supply an ObjectBean, ObjectTypeAttributeBean and your values as strings. You will have to add the MutableObjectAttributeBean to a MutableObjectBean after creation. See full example usage in the script Create object or the following groovy snippet:
/* Set the name of the customer */
def nameObjectTypeAttributeBean = objectTypeAttributeFacade.loadObjectTypeAttributeBean(1); // 1 is the ID of the object type attribute "Name"
objectAttributeBeans.add(objectAttributeBeanFactory.createObjectAttributeBeanForObject(newObjectBean, nameObjectTypeAttributeBean, issue.getSummary()));Before upgrading to Insight 5.0
We strongly recommend that you review all your import configurations after you have upgraded to Insight 5 from Insight 4.
If your installation of Insight is configured with an Insight Discovery import you will have to do the following after you have installed Insight 5:
- Download and install version 2.x of Insight Discovery from Marketplace.
- Navigate to your Object Schema where your Insight Discovery import is configured and press Migrate Configuration.
- Verify the migrated import configuration.
If your installation of Insight is configured with a Tempo Account import you will have to do the following after you have installed Insight 5:
- Download and install Insight Tempo Integration from Marketplace.
- Navigate to your Object Schema where your Tempo import is configured and press Migrate Configuration.
- Verify the migrated import configuration.
Upgrading from JIRA 2.x?
For Insight 2.x users, make sure that you upgrade to the latest version of Insight 3.x before upgrading to Insight 5.0 if you are on Insight 2.x.
This is very important for the upgrade process!
Upgrading from Insight 5 Beta version
If you used the Insight 5 beta there is no need to do anything particular. The recommended upgrade path is to upgrade to the latest Insight 5 marketplace version from the beta. There is no need, and it is not recommended, to roll back to Insight 4 before upgrading.