Jira Service Management 4.16.x release notes
23 March 2021
We're excited to present Jira Service Management 4.16.
Highlights
- Get more insights into the usage of custom fields (Data Center)
- Bulk delete custom fields (Data Center)
- Configure default values for system fields (Data Center)
- Let users log in with multiple identity providers (Data Center)
- Check the status of your data pipeline exports
- Keep Jira safe by disabling basic authentication
- Indexing improvements

More
Read the upgrade notes for important details about this release and see the full list of issues resolved.
Compatible applications
If you're looking for compatible Jira applications, look no further:
The following features live in the Jira platform, which means they’re available for the whole Jira family — Jira Core, Jira Software, and Jira Service Management.
Get more insights into the usage of custom fields DATA CENTER
Too many custom fields can clutter your Jira instance and negatively impact performance, but knowing which one to delete isn’t always easy. To make it easier for you, every custom field now includes data about its usage so you can identify the important ones and part ways with the rest.

Two new columns, Issues and Last value update, show how many issues are using your custom field and the last value update. The columns are sortable, so you can quickly find good candidates for deletion. Learn more
Bulk delete custom fields DATA CENTER
We’ve also added a way to select and delete multiple custom fields at once. It’s not that we want you to use it particularly often, but we’re guessing that with the new features for custom fields, you’ll find plenty that can be deleted right away.

Whatever season is there in your part of the globe right now, it’s always good to do some spring cleaning. Learn more
Configure default values for system fields DATA CENTER
We're introducing a possibility to configure a default value for the Description field. From now on admins can add and apply contexts with a default value to multiple issue types and projects.

We’ve added a new page to the administration area for the System fields to group out-of-the-box Jira fields. At the moment, you can add and apply different contexts with default values only for the Description field.
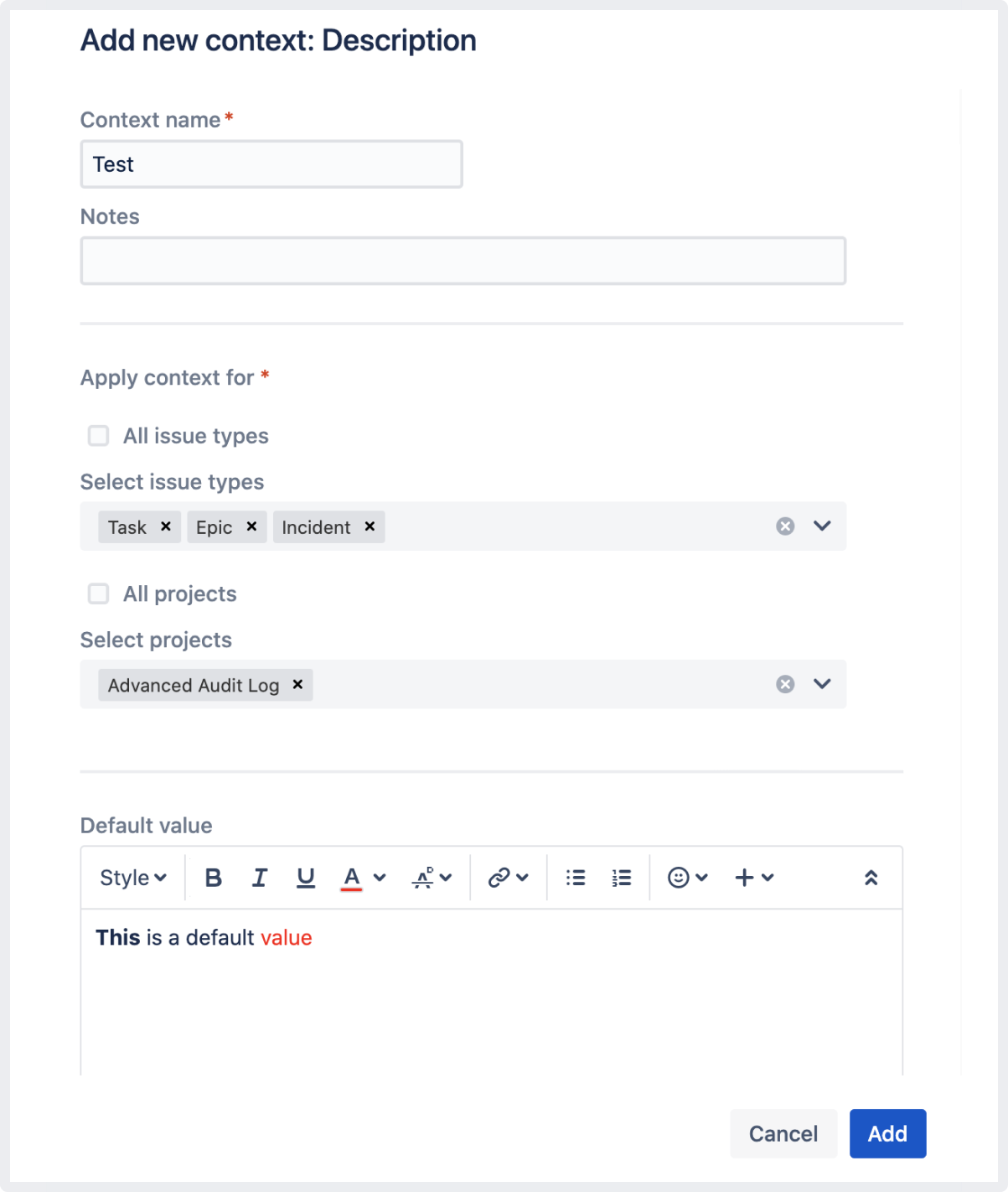
For other fields, you can easily view the screens they’re associated with, and add some more if needed.
In Jira Service Management, default values for the Description field will be available when your agents create or edit requests, but they won’t be displayed on customer portals.
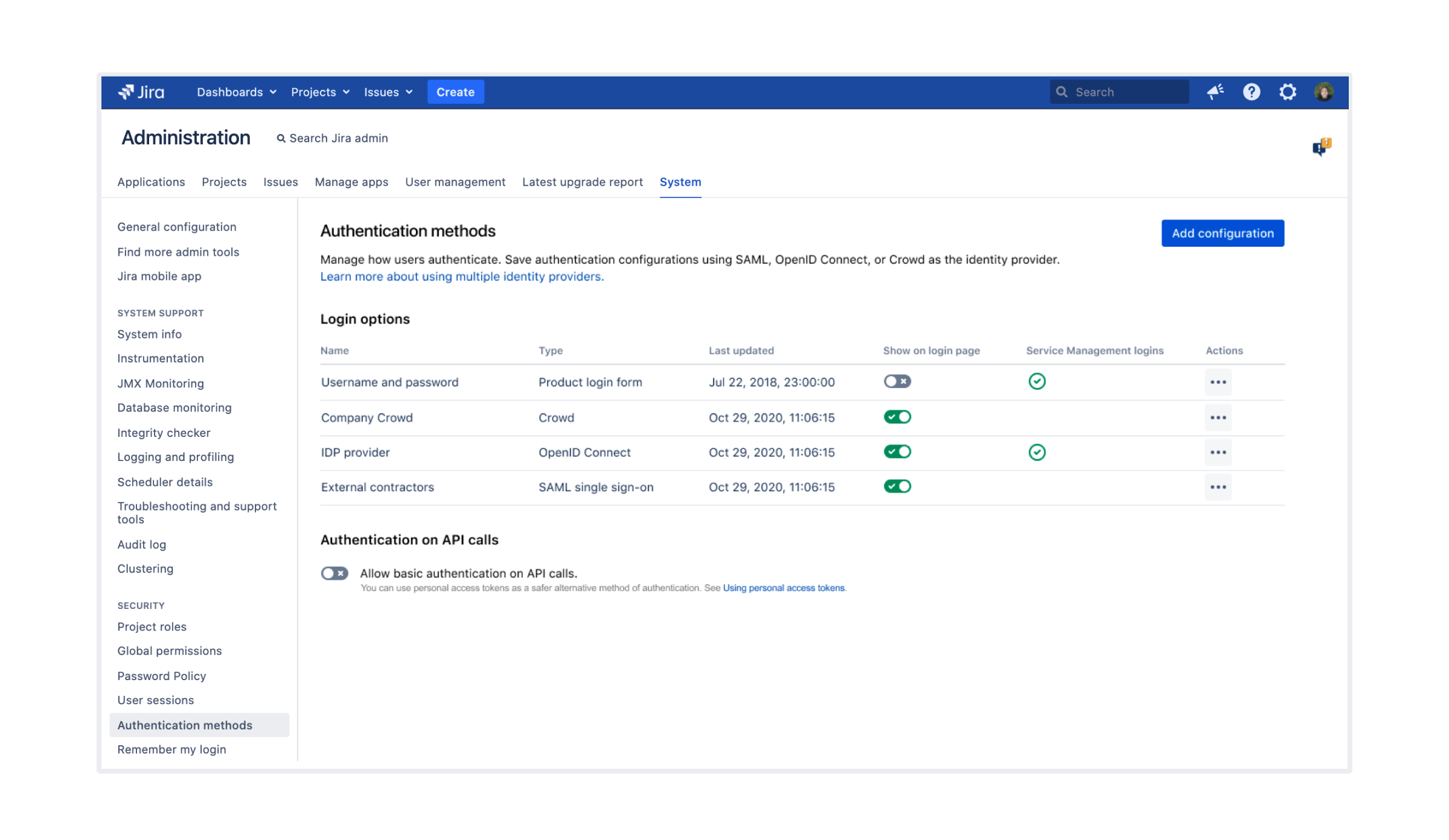
Let users log in with multiple identity providers DATA CENTER
We’re happy to announce that from now on, you can configure multiple Identity Providers (IdPs) in SAML and OpenID Connect configuration, and let your users choose the right one for them as they log in. You can enable the new login methods independently for customer portals in Jira Service Management. Learn more
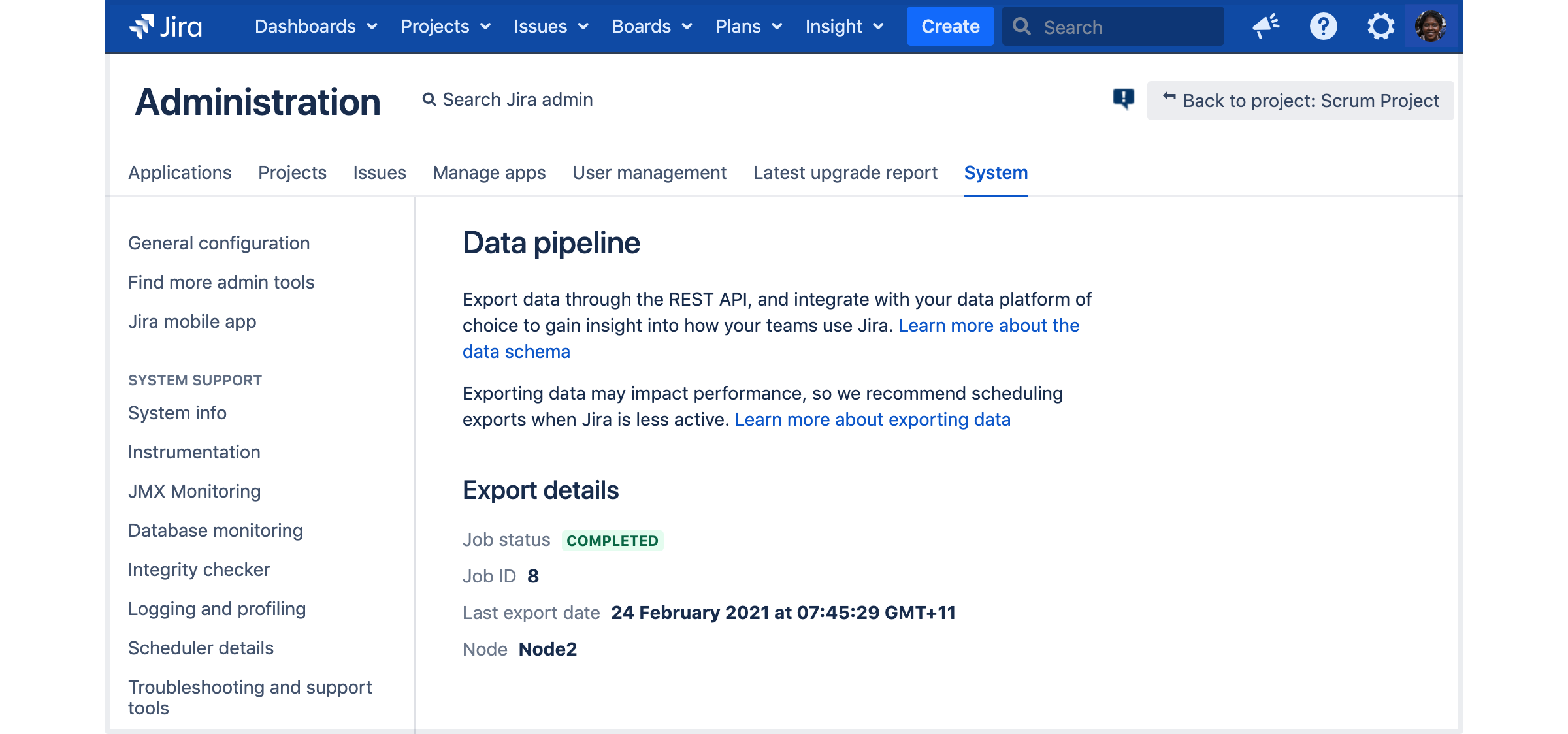
Check the status of your data pipeline exports DATA CENTER
The data pipeline allows you to export current state data from Jira, then feed it into your favourite business intelligence platform (such as Tableau or PowerBI) for analysis. Learn more
You can now check the status of the latest export from Jira. Go to ![]() > System > Data pipeline.
> System > Data pipeline.
Keep Jira safe by disabling basic authentication
While working on adding multiple identity providers, we’ve also included a way to disable basic authentication on the login page and in API calls. Since basic authentication is less secure than single sign-on, we advise that you switch to SSO, and disable basic authentication completely. Learn more
Indexing improvements
We’ve made some changes to indexing that should make it both better and faster:
Better performance, the same high consistency
In Jira Service Management 4.10, we’ve decreased indexing performance so we could introduce higher index consistency—an improvement worth the cost. Now, we’ve made additional changes to index searchers and cache to bring the performance back up to speed again. The reindexing tasks, like background reindexing, SLA recalculation, and DVCS reindexing should be at least 10% faster, with full index consistency retained. Learn more
Priority queues for user indexing requests
We’ve also improved the way we handle different types of indexing requests so they no longer affect user actions. In previous versions, background reindexing tasks used a single queue and could overflow it when many indexing operations were requested at once. Now, we’ve separated this queue into two—one for handling indexing requests created by users, and the other for all other requests. Thanks to that, users requests get a priority, and everything stays fast and well organized. Learn more
Resolved issues
Issues resolved in 4.16.0
Released on 23 March 2021
Issues resolved in 4.16.1
Released on 20 April 2021
Issues resolved in 4.16.2
Released on 2 June 2021